
cube studio开源一站式云原生机器学习平台-架构(二)
前言:cube是开源的云原生机器学习平台,目前包含特征平台,支持在/离线特征;数据源管理,支持结构数据和媒体标注数据管理;在线开发,在线的vscode/jupyter代码开发;在线镜像调试,支持免dockerfile,增量构建;任务流编排,在线拖拉拽;开放的模板框架,支持tf/pytorch/spark/ray/horovod/kaldi等分布式训练任务;task的单节点debug,分布式任务的批

全栈工程师开发手册 (作者:栾鹏)
一站式云原生机器学习平台
github:https://github.com/tencentmusic/cube-studio
前言:cube studio是开源的云原生机器学习平台,目前包含特征平台,支持在/离线特征;数据源管理,支持结构数据和媒体标注数据管理;在线开发,在线的vscode/jupyter代码开发;在线镜像调试,支持免dockerfile,增量构建;任务流编排,在线拖拉拽;开放的模板框架,支持tf/pytorch/spark/ray/horovod/kaldi等分布式训练任务;task的单节点debug,分布式任务的批量优先级调度,聚合日志;任务运行资源监控,报警;定时调度,支持补录,忽略,重试,依赖,并发限制,定时任务算力的智能修正;nni,katib,ray的超参搜索;多集群多资源组,算力统筹,联邦调度;tf/pytorch/onnx模型的推理服务,serverless流量管控,tensorrt gpu推理加速,依据gpu利用率/qps等指标的 hpa能力,虚拟化gpu,虚拟显存等服务化能力。
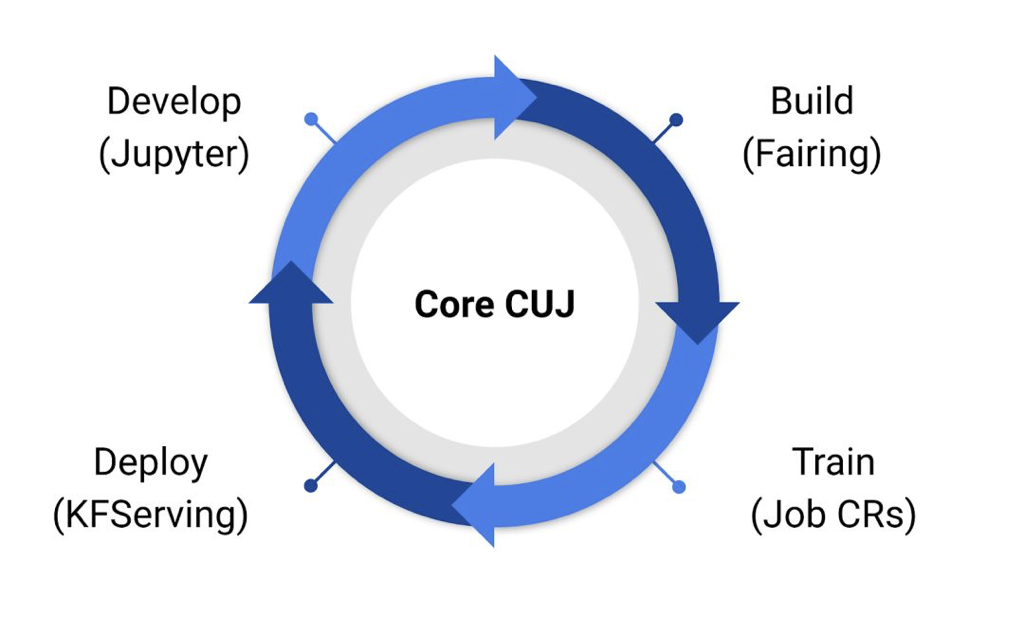
附能工作各流程
因为cube机器学习平台基于kubeflow做开发,我们先来了解下kubeflow附能算法工作的各个环节。在开发环节,kubeflow集成的jupyterhub;构建镜像/任务环节,kubeflow集成了fairing;在训练环节,kubeflow集成了各种分布式训练的Job CRs;在服务化环节,kubeflow依赖istio、knative-serving,集成了kfserving。另外监控系统,链路追踪,日志系统都可以独立部署,没有写到kubeflow仓库中。

Jupyter
jupyter 创建和管理多用户交互式Jupyter notebooks。Jupyterhub管理前后端在jupyter-web-app中,创建后会创建自定义资源Notebook。Notebook-controller用来管理启动notebook server。
前端:components/jupyter-web-app/frontend, webpack http://localhost:4200/jupyter/
后端: components/jupyter-web-app/backend,flask http://localhost:5000

在机器学习平台中,创建了notebooks.kubeflow.org的crd,用来根据用户的配置生成 notebook,每个用户可以有多个notebook,notebook的权限管理在产品侧实现,所以notebook的流量代理不一定是根据真实用户进行的。
notebooks.kubeflow.org
我们先来看看该crd如何使用。下面是一个示例
apiVersion: kubeflow.org/v1
kind: Notebook
metadata:
name: pengluan-test
namespace: jupyter
spec:
template:
spec:
containers:
- command:
- sh
- -c
- jupyter lab --notebook-dir=/mnt/pengluan --ip=0.0.0.0 --no-browser
--allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password=''
--NotebookApp.allow_origin='*' --NotebookApp.base_url=/notebook/jupyter/pengluan-test
image: xxx
name: test
workingDir: /mnt/pengluan
serviceAccountName: default-editor
配置pod需要注意的是你的启动命令一定是jupyter的启动进程,并配置启动参数,这也要求你的镜像中必须集成了jupyter。其中notebook-dir参数值最好是通过pvc挂载进来的分布式存储目录,这样就能将用户文件和jupyter环境分离开。
另外你可以按照pod spec的参数配置jupyter容器的resource,securityContext,volumes、volumeMounts,imagePullSecrets,imagePullPolicy等。
通过notebook crd,就可以使多个用户使用多个notebook,可以共享也可以隔离。在产品侧通过控制权限,也可以实现项目组共用notebook的功能。
jupyter
我们知道jupyter产品,包含jupyter notebook,jupyterlab,jupyterhub。分别是编辑器,丰富版的在线编辑器,和多用户版的编辑器。我们在多用户层面是通过自建的权限管理体系,所有没有使用jupyterhub,并且由于jupyterlab比jupyter notebook更强大的功能和更好的用户体验,我们选择使用jupyterlab。封装方式很简单,只需要你原本的镜像pip install jupyterlab就可以了。
服务网格代理多个notebook
另外当有多个notebooks.kubeflow.org创建后,对应的每个jupyter容器都有一个独立的访问地址。而这些访问地址是通过istio进行代理的。在jupyterlab启动参数中NotebookApp.base_url=/notebook/nodebook1/pengluan,这个就是访问当前notebook1的前缀路径。这样我们就可以根据前缀路径,使用istio的virtualservices.networking.istio.io来配置代理。这一部分可以结合istio服务网格部分一块了解。

构建镜像和任务
构建镜像包含多种方式,最长使用的莫过于,我们在本地打docker images。如果你需要在线实时更新镜像环境,那就可以在线构建镜像了。下面是几种在线构建的方式
Fairing-构建镜像
fairing.config.set_builder(name='docker', registry=DOCKER_REGISTRY, base_image=base_image,image_name=tfjob_name)
Kaniko集群模式
Kaniko需要k8s环境,fairing自动化构建镜像,会创建k8s-job,创建专门用来进行构建镜像的pod。kaniko集群构建不需要Docker守护程序,Kaniko pod使用自己的“executor”以root用户执行构建步骤,构建步骤本身是由执行程序代码执行的。

构建步骤:
- “executor”遍历Dockerfile中定义的每个构建步骤。并随其压缩/添加/更改rootfs的内容,更改“diff”层。将diff层依次添加到基础镜像中以形成新镜像
- 新生成镜像后 push 到指定的 registry。注意:在容器中推送到csighub,需要修改builder pod 的/etc/hosts
构建上下文:
三种方式:本地目录,三大云存储商、Minio 兼容s3
构建缓存:
1、源镜像可以下载到本地卷中共享。
2、执行RUN Dockerfile指令期间在远程镜像仓库创建镜像的缓存
Minio sdk:https://docs.minio.io/docs/golang-client-quickstart-guide
平台中的Builder pod会挂载docker-config,构建镜像,并使用minio做镜像缓存。
缺点:需要与k8s做交互,还要额外管理k8s-job,copy文件传输需要代码控制和网络传输。
Podman新构建方式
使用命令与docker类似,但是不需要守护后端,单容器任务,但是需要超级权限、 vfs存储层模式,当podman本身就在容器时配置相对麻烦。
Docker原始方式
需要挂载主机docker,使用docker in docker 镜像。缺点,镜像数据存储在机器上,会增加机器的磁盘占用,或者需要手动清理。
Fairing-构建任务
使用fairing创建tfjob分布式任务的方式如下:
fairing.config.set_deployer(name='tfjob', namespace=my_namespace, stream_log=False,
worker_count=num_workers, ps_count=num_ps, job_name=tfjob_name,
labels={'app':tfjob_name},
pod_spec_mutators = [
mounting_pvc(pvc_name=pvc_name, pvc_mount_path=model_dir),
add_resource(resource=resource),
])
kubeflow fairing集成了对k8s-job,tfjob,pytorchjob的部署,减少平台开发工作量。如果无法满足你的需求,你完全可以自己开发一套控制包。实现原理是相同的,都是通过python kubernetes包对k8s crd进行操作。
数据处理
spark-job
目前还未在平台中支持spark-job的使用。目前主要以使用tdw spark调度集群来替代spark job的功能。是否会在集群中开发spark job的使用目前还没有确定。
k8s-job
当然你还可以使用k8s的原生job资源。自己定义单容器任务,或者自己构建operator,支持分布式任务。这个是平台最常用的处理方式,比如目前的通过tdw api 提交tdw spark任务,支持hdfs数据的上传下载,都是k8s 普通pod形式的job。因为平台提供功能模板化,只要提供相应的数据处理模板,就可以使用相应的数据处理能力。这是传统docker运行进程转为k8s任务最便捷的方式。
TensorFlow Extended

这个是tf官方推出的分布式数据处理和训练方案,目前没有集成到平台中,在数据分布式处理时也不失为一种好的方案。
训练处理环节
训练环节,平台提供了很多训练job的crd,可以让我们方便的使用分布式任务。
分布式训练tfjobs
tensorflow
tensorflow 支持如下三种分布式策略:
MirroredStrategy:适用于单机多卡的训练场景,功能有限,不在本文讨论范围内。
ParameterServerStrategy:用于多机多卡场景,主要分为 worker 节点和 PS 节点,其中模型参数全部存储在 PS 节点,worker 在每个 step 计算完梯度后向 PS 更新梯度。
CollectiveAllReduceStrategy:用于多机多卡场景,通过all-reduce的方式融合梯度,只需要 worker 节点,不需要 PS(parameter server) 节点,从另外一个角度说,该节点既充当 worker 角色,又充当 PS 角色。该方案是带宽优化的,具有性能好,可扩展性强的特点,是 tensorflow 未来推荐的方案。
以 ParameterServerStrategy 为例,一个分布式训练集群至少需要两种类型的节点:PS(参数服务器,为模型的参数提供分布式的数据存储) 和 worker(负责实际训练模型的任务)。由于在训练中需要一个worker节点来评估效果和保存checkpoint,因此单独把该节点作为 chief(或者叫 master,负责协调训练任务) 节点。有时还可以具有Evaluator节点,负责在训练过程中进行性能评估。通常情况下,一个集群需要多个 worker 节点,多个 PS 节点,一个 chief 节点。所有 worker 节点的 CPU/内存/GPU等资源配置完全相同,所有 PS 节点的CPU/内存等资源配置也相同。

tfjobs.kubeflow.org
从资源拓扑角度出发,如果能够提供一种自定义 k8s 资源(crd),用户可以基于该资源定义 PS/worker/chief 的数量和规格,就可以一键式创建分布式训练,大大简化了分布式训练的部署和配置。平台提供了tfjobs这种自定义资源,示例如下:可以只包含worker副本控制器,使用其中一个worker启动ps服务。
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
generateName: tfjob
spec:
tfReplicaSpecs:
PS:
Replica spec
Worker:
Replica spec
tf-operator
kuebflow通过tf-operator 来管理tfjobs.kubeflow.org,用户可以借助 tfjobs.kubeflow.org 在 k8s 上一键拉起分布式训练集群。当我们创建tfjobs的资源时,tf-operator会按照如何的过程工作。

当我们创建tfjobs资源时,tf-operator会根据tfjobs的参数创建分布式tf训练的各节点容器和服务,并配置TF-CONFIG环境变量,并为每个角色创建headless service,保证每个角色的pod都有一个独立的访问地址。为每个容器配置所有角色容器的地址,和当前容器的角色。由代码自己去识别自己的角色和该处理的内容,以及识别访问其他角色容器的地址。
分布式训练pytorchjobs
pytorch
使用分布式时,在梯度汇总求平均的过程中,各主机之间需要进行通信。因此,需要指定通信的协议架构等。torch.distributed 对其进行了封装。torch.distributed 支持 3 种后端,分别为 NCCL,Gloo,MPI。各后端对 CPU / GPU 的支持如下所示:

那么,在什么情况下选用什么样的backend?经验法则:
- 使用NCCL后端进行分布式GPU培训
- 使用Gloo后端进行分布式CPU培训。
pytorchjobs.kubeflow.org
同样kubeflow提供了一种自定义资源pytorchjobs,可以通过yaml部署。同样包含master和worker副本。
apiVersion: kubeflow.org/v1
kind: PyTorchJob
metadata:
name: pytorch-tcp-dist-mnist
namespace: default
spec:
cleanPodPolicy: None
pytorchReplicaSpecs:
Master:
Replica spec
Worker:
Replica spec
status:
completionTime:
conditions:
replicaStatuses:
Master: {}
Worker: {}
startTime:
分布式训练xgbjobs
xgboost算法本身支持分布式训练,可以在spark、k8s上进行并行调度。
xgboostjobs.xgboostjob.kubeflow.org
kubeflow定义了xgboostjobs自定义资源,我们只需要配置master和worker就可以实现部署xgb分布式。
apiVersion: "xgboostjob.kubeflow.org/v1alpha1"
kind: "XGBoostJob"
metadata:
name: "test"
spec:
xgbReplicaSpecs:
Master:
ReplicaSpecs:
Worker:
ReplicaSpecs:
k8s通过xgboost-operator监听xgboostjob资源,创建对应的pod和service。目前由于xgb训练本身支持并行化,单机训练速度也足够快,所以在分布式上需要当模型足够大以后需求才会更多起来。
其他的模型框架
其他的模型框架也在支持中,以后补充

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)