动手深度学习13——计算机视觉:数据增广、图片分类
一、数据增广1.1 为何进行数据增广?CES真实案例:几年前,一家做无人售货的公司发现演示机器在现场的效果很差,因为现场在赌城拉斯维加斯,现场与之前的开发测试办公室:色温不同。赌城灯光很暗,偏黄测试demo时机器放在桌子上,桌子很亮,反射后图片取景有变化解决:开场前一天现场测试有问题,马上现场采集数据发回国内,训练一个新的模型,并且买了一块桌布就没有反光了。例如语音识别、CV等场景,训练模型时可以
文章目录
- 本帖经过一次大的修改,现在只包含数据增广、微调和图片分类(赛事)
- 这些帖子是我做的李沐-动手深度学习课程的笔记。之前这篇帖子写的是数据增广、微调、目标检测(锚框)等等。后来我把目标检测(锚框)的部分内容移到了另一篇帖子(动手深度学习13:计算机视觉——目标检测:锚框算法原理与实现、SSD、R-CNN)
一、数据增广
参考李沐《动手深度学习》、哔哩哔哩视频
图片分类常见卷积神经网络(VGG、ResNet)等可以参考李沐《现代卷积神经网络》、VGG哔哩哔哩视频
也可以参考我之前做的笔记《学习笔记五:卷积神经网络一》
1.1 为何进行数据增广?
- CES真实案例:
几年前,一家做无人售货的公司发现演示机器在现场的效果很差,因为现场在赌城拉斯维加斯,现场与之前的开发测试办公室:
- 色温不同。赌城灯光很暗,偏黄
- 测试demo时机器放在桌子上,桌子很亮,反射后图片取景有变化
解决:开场前一天现场测试有问题,马上现场采集数据发回国内,训练一个新的模型,并且买了一块桌布就没有反光了。
例如语音识别、CV等场景,训练模型时可以模拟部署场景的各种情况,是提高模型泛化性的一种手段。
- 数据增广的优点:
- 数据增⼴可以⽣成相似但不同的训练样本,从⽽扩⼤了训练集的规模,增加数据多样性。
- 此外,随机改变训练样本可以减少模型对某些属性的依赖,从⽽提⾼模型的泛化能⼒。例如,我们可以以不同的⽅式裁剪图像,使感兴趣的对象出现在不同的位置,减少模型对于对象出现位置的依赖。我们还可以调整亮度、颜⾊等因素来降低模型对颜⾊的敏感度
- 增广方式:语音中加入不同背景音,图片可以改变颜色、亮度和形状等。
一般的做法是图片进行随机在线数据增广之后再进行训练,相当于一个正则项。
- 软件安装:
pip install torch==1.10.2
pip install torchvision==0.11.3
pip install d2l==0.17.4
1.2 常见图片增广方式
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open('../img/cat1.jpg')
d2l.plt.imshow(img);

定义辅助函数apply。此函数在输⼊图像img上多次运⾏图像增⼴⽅法aug并显⽰所有结果:
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]#对num_rows * num_cols的图片进行增广存储到Y
d2l.show_images(Y, num_rows, num_cols, scale=scale)#打印出增广后的图片
img:被增广图片
aug:增广办法
num_rows、num_cols:图片被增广成几行几列
scale:放大比例
1.2.1 翻转
- 图片可以左右、上下翻转,但不一定总是可行。比如树叶可以上下翻转,但是建筑上下翻转就很奇怪,所以要根据样本来决定。
- 使⽤transforms模块来创建RandomFlipLeftRight实例,这样就各有50%的⼏率使图像向左或向右翻转
apply(img,torchvision.transforms.RandomHorizontalFlip())#随机左右翻转

apply(img, torchvision.transforms.RandomVerticalFlip())#随机上下翻转

1.2.2 切割(裁剪)
从原图切割一块,再变形到固定形状(卷积网络固定输入)。切割方式可以是随机高宽比、随机大小、随机位置。
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
- (200, 200):裁剪后resize到200*200像素(卷积网络输入是固定的)
- scale(0.1,1):随机裁剪⼀个⾯积为原始⾯积10%到100%的区域
- ratio=(0.5, 2)):裁剪区域的宽⾼⽐从0.5到2之间随机取值

1.2.3 改变颜色
主要是改变色调(偏黄偏蓝等等)、饱和度(浓度)、亮度等等。创建一个RandomColorJitter实例,并设置如何同时[随机更改图像的亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)]:
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
#brightness=0.5表示明度在50%-150%之间随机变化,其它参数类同
#四个参数随机取值组合决定图片变化

1.2.4 综合使用
- 在实践中,我们将结合多种图像增广方法。比如,我们可以通过使用一个Compose实例来综合上面定义的不同的图像增广方法,并将它们应用到每个图像:
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
color_aug = torchvision.transforms.ColorJitter(
brightness=0.2, contrast=0, saturation=0.2, hue=0.05)
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)

- 还可以有其它方式,比如高斯模糊、锐化、图片中间去块等等。但不是每一种都有用。如果测试集或者部署环境中没有那些奇怪的图片,某些方法可以不用。所以是应该先考虑测试集、部署环境中图片会有哪些变化,再考虑图片增广应该使用哪些方法。

1.3 使用图像增广进行训练
我们使⽤CIFAR-10数据集进行图像增广之后再训练模型。CIFAR-10数据集中对象的颜⾊和⼤⼩差异更明显。CIFAR-10数据集中的前32个训练图像如下所⽰:
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",
download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
- 为了在预测过程中得到确切的结果,我们通常对训练样本只进行图像增广,且在预测过程中不使用随机操作的图像增广。在这里,我们[只使用最简单的随机左右翻转]。(因为图片已经在最中间了,且比较小,大概32*32。且训练测试集亮度颜色差不多,不需要做太厉害的增广)
- 此外,我们使用
ToTensor实例将一批图像转换为4d的Tensor矩阵方便训练,即形状为(批量大小,通道数,高度,宽度)的32位浮点数,取值范围为0到1。
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])
- 生成数据集
接下来,我们[定义一个辅助函数,以便于读取图像和应用图像增广]。PyTorch数据集提供的transform函数应用图像增广来转化图像:
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,
transform=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader
这里的d2l.get_dataloader_workers()=4,多开进程是因为图片随机增广的时候计算量很大,开多进程可以快一点。
- 定义模型
我们在CIFAR-10数据集上训练一个多GPU的ResNet-18模型:
#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需(稍后讨论)
X = [x.to(devices[0]) for x in X]#如果X是list就一个个copy到devices
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()#梯度归零
pred = net(X)
l = loss(pred, y)
l.sum().backward()#梯度回传
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
- 增广训练
定义train_with_data_aug函数,使用图像增广来训练模型]。该函数获取所有的GPU,并使用Adam作为训练的优化算法,将图像增广应用于训练集,最后调用刚刚定义的用于训练和评估模型的train_ch13函数。
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):#训练集是增广数据集train_augs
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
使用基于随机左右翻转的图像增广来训练模型:
train_with_data_aug(train_augs, test_augs, net)
loss 0.167, train acc 0.943, test acc 0.843
5486.0 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
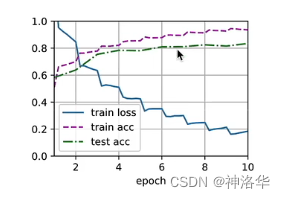
不用图像增广,效果:
loss 0.072, train acc 0.975, test acc 0.824
5560.0 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
对比可以看到,简单翻转图片可以有效降低过拟合程度(训练测试集精度差异更小,overfiting更小)。有些情况下测试集精度高于训练集精度,是由于训练集图片增广太狠,出现很多奇怪的图片,精度下降。而测试集中图片不会那么奇怪,效果反而更好。
1.4 小结
- 图像增广基于现有的训练数据生成随机图像,来提高模型的泛化能力。
- 为了在预测过程中得到确切的结果,我们通常对训练样本只进行图像增广,而在预测过程中不使用带随机操作的图像增广。
- 深度学习框架提供了许多不同的图像增广方法,这些方法可以被同时应用。
二、微调
2.1 为啥要微调
- 实际工作中,我们训练的模型数据集大小通常在Fashion-MNIST(6万张)训练数据集和ImageNet(120万张)数据集之间。假如我们需要训练一个识别车的模型,适合ImageNet的复杂模型可能会在这个汽车数据集上过拟合(汽车数据集多样性比ImageNet小)。
- 此外,由于训练样本数量有限,训练模型的准确性可能无法满足实际要求。

解决方案有两种:
-
收集更多的数据。 但是,收集和标记数据可能需要大量的时间和金钱。 例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究资金。 尽管目前的数据收集成本已大幅降低,但这一成本仍不能忽视。
-
应用迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。 例如,尽管ImageNet数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征也可能有效地识别椅子。
2.2 微调(fine-tuning)步骤
当目标数据集比源数据集小得多时,微调有助于提高模型的泛化能力。(其实相当于用源模型的参数作为目标模型的参数初始化,这样比目标模型随机初始化效果好。而输出层是随机初始化来训练)
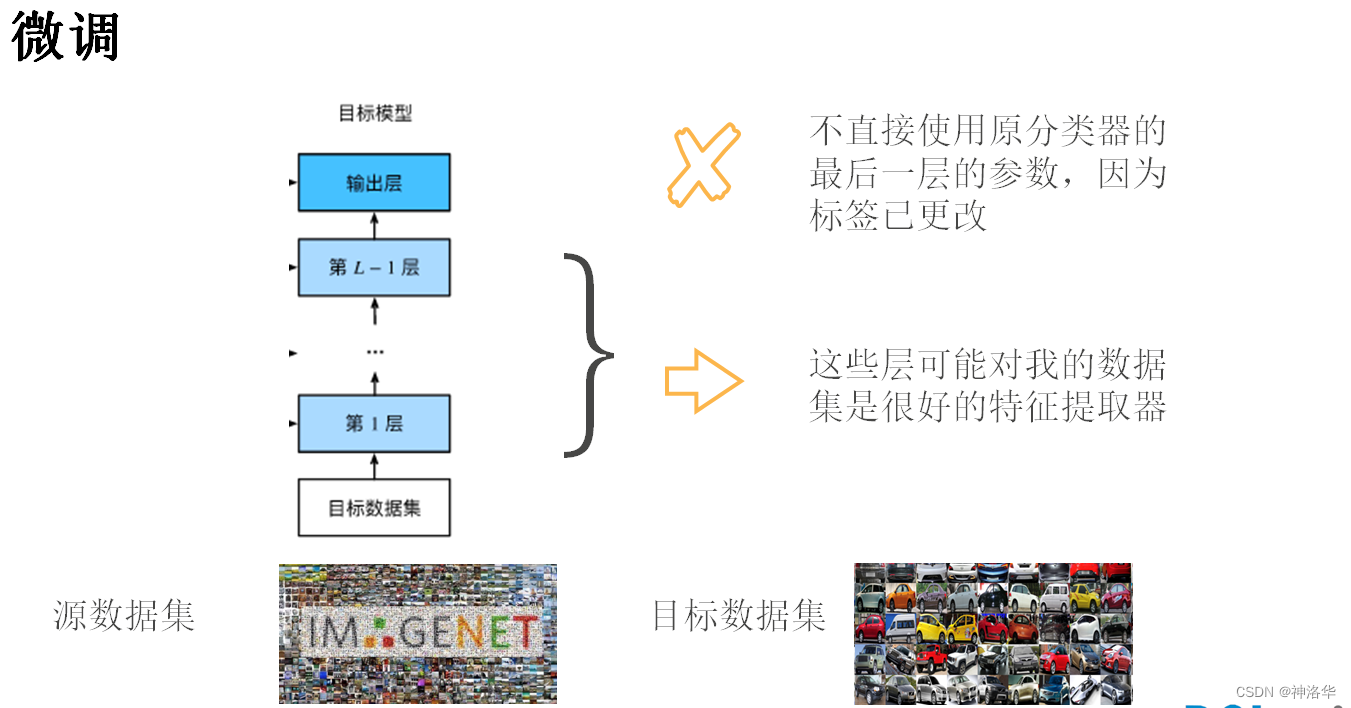
- 在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
- 向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
- 在目标数据集(如汽车数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
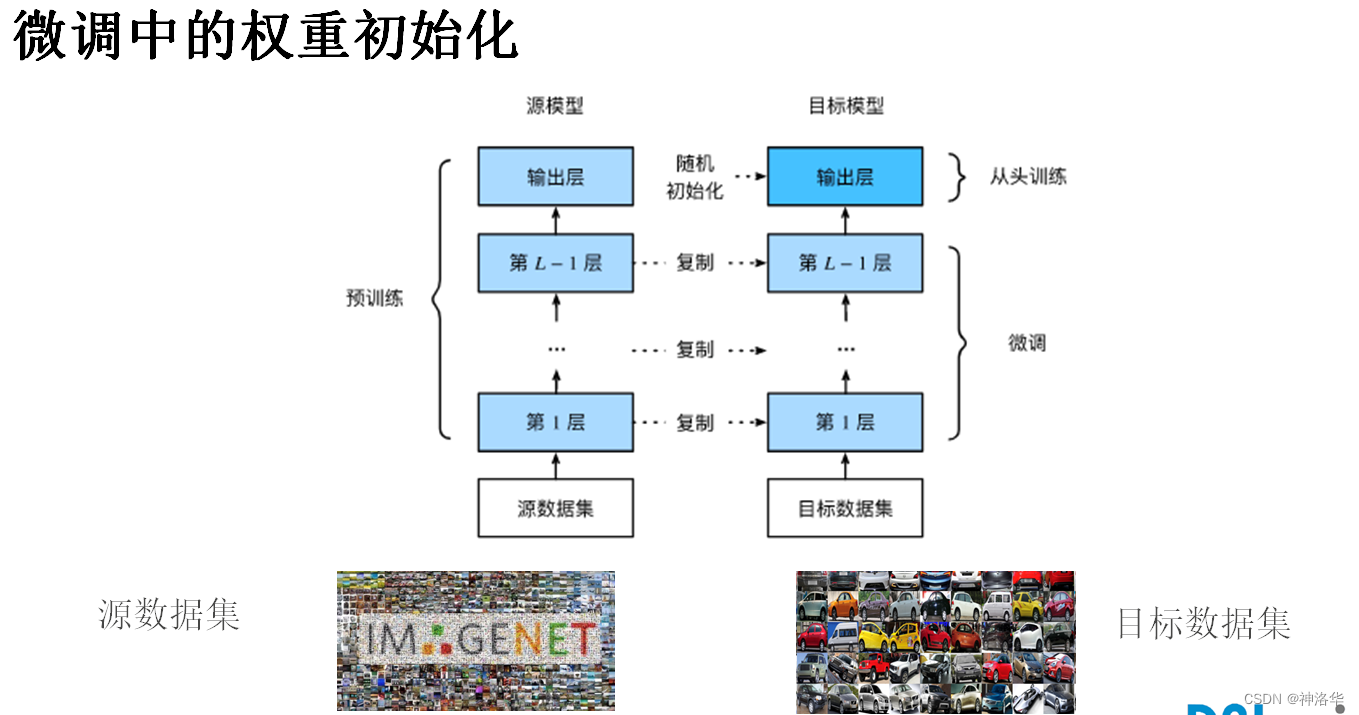
- 源数据集可能包含目标数据集中的某些类别,这些样本可以加入目标数据集一起初始化。(在初始化期间使用来自预训练模型的相应权重向量)
- 在已有神经网络上微调目标数据集,但具有强大的正则化
- 使用较小的学习率
- 使用较少的迭代周期
- 如果源数据集比目标数据集更复杂,则微调通常会得到更高质量的模型
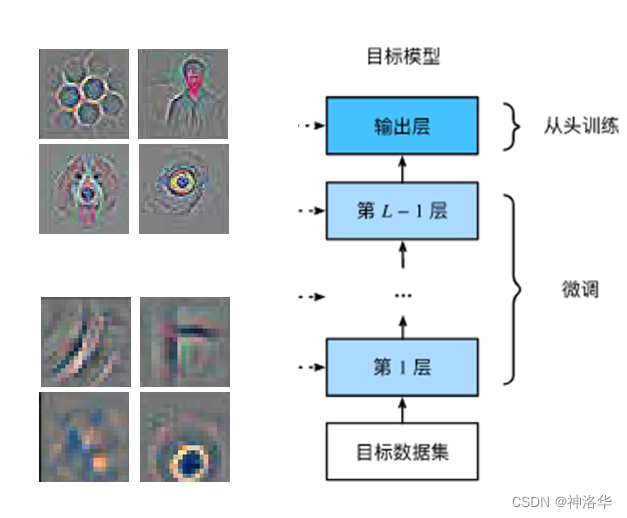
- 神经网络学习分层特征表示
- 低层特征是通用的(底层权重可以固定,模型复杂度变低,数据集小的时候相当于正则)
- 高层特征与数据集中的对象更相关
- 在微调期间修复底层的参数
- 另一个强有力的正则
2.3 总结
- 微调通过使用在大数据集上训练好的模型,来初始化目标模型权重以得到更好的精度
- 预训练模型质量很重要
- 微调通常速度更快,精度更高
- 以后学术界或者大公司才会从头训练大的深度学习模型,慢慢的几乎所有基于深度学习的应用都会基于微调。
- 如果目标数据集和源数据集差异非常大,那么从头训练目标数据集效果可能更好。或者医学的就找医学的预训练模型。
2.4 代码举例
简介:热狗数据集有正负两类,预下载在ImageNet上训练好的resnet-18模型,然后在热狗数据集上微调。微调时,最后一个fc层学习率为10*lr,其它层学习率为lr,最后效果很好。(基本2个epoch效果就很好了,lr=5e-5比较小)
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);

注意:
- 因为在ImageNet上做了RGB三通道标准化,所以热狗数据集也要做这一步。(如果网络中有BN就不需要这么做了)
- ImageNet输入是224*224,所以热狗数据集图片也要resize到224
- 数据增强只用简单的水平翻转
三、实战 Kaggle 比赛:图像分类 (CIFAR-10)(待补充)
3.1 动手深度学习代码
!pip install d2l==0.17.5
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
3.1.1 下载数据集
为了便于⼊⻔,我们提供包含前1000个训练图像和5个随机测试图像的数据集的⼩规模样本。要使⽤Kaggle竞赛的完整数据集,你需要将以下demo变量设置为False:
#@save
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip',
'2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
# 如果你使用完整的Kaggle竞赛的数据集,设置demo为False
demo = False
if demo:
data_dir = d2l.download_extract('cifar10_tiny')
else:
data_dir = '../data/cifar-10/'
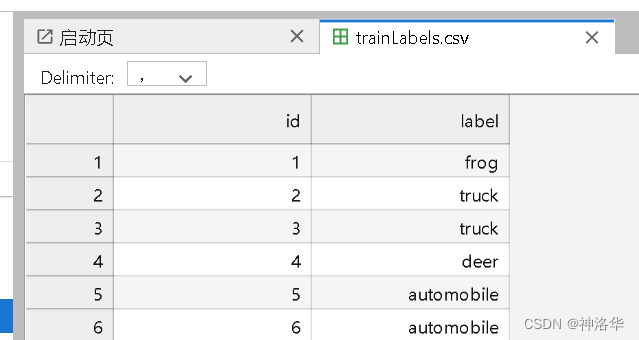
read_csv_labels :读取’trainLabels.csv‘,返回一个图片标签的字典,最后labels格式如下:
#@save
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行(列名)
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]#去除换行符
return dict(((name, label) for name, label in tokens))#把csv一行行数据(列表)换成图片id和类别的字典
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
print('# 训练样本 :', len(labels))
print('# 类别 :', len(set(labels.values())))
"""
lines:['1,frog\n', '2,truck\n']...
tokens:[['1', 'frog'], ['2', 'truck']...]
labels:
{'1': 'frog',
'2': 'truck',...}...
"""
# 训练样本 : 1000
# 类别 : 10
3.1.2 拆分数据集
- reorg_train_valid函数:拆分原训练集为新的训练集和验证集。
- 参数valid_ratio:验证集中的样本数与原始训练集中的样本数之比。 如果n等于样本最少的类别中的图像数量,而r是比率。验证集将为每个类别拆分出max([nr],1)张图像。
- 假设valid_ratio=0.1,原训练集50000张图像,因此新训练集’train_valid_test/train’中将有45000张图像用于训练,而剩下5000张图像将作为路径’train_valid_test/valid’中的验证集。 各数据集中同类别的图像将被放置在同一文件夹下
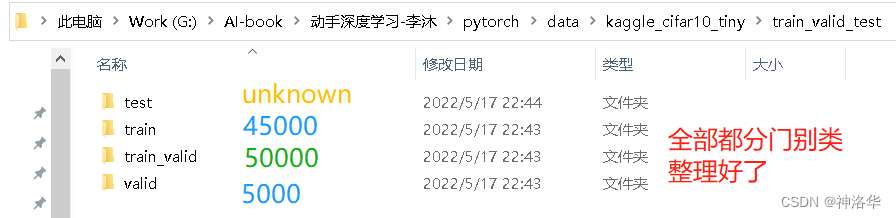
-
labels:包含本来的训练集’train‘的所有图片标签的字典,其格式如下:
{‘1’: ‘frog’,
‘2’: ‘truck’,…} -
os.path.join(data_dir, ‘train_valid_test’,‘train_valid’, label):创建新文件夹‘data_dir/train_valid_test/train_valid’,并创建类别(label)子文件夹,如下图所示:

#@save
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
#@save
def reorg_train_valid(data_dir, labels, valid_ratio):
"""将验证集从原始的训练集中拆分出来"""
# 训练数据集中样本最少的类别中的样本数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio))
label_count = {}
#遍历训练集'train'的文件
for train_file in os.listdir(os.path.join(data_dir, 'train')):
"""labels是包含训练集标签的字典,格式如下:
{'1': 'frog',
'2': 'truck',...}
print(train_file)格式为:
1.png
2.png
...
所以train_file.split('.')[0]就是每张图片的编号1.2.3....
labels[train_file.split('.')[0]]就是训练集每张图片的label
frog
truck
truck
"""
label = labels[train_file.split('.')[0]]#图片标签,和train_file对应
fname = os.path.join(data_dir, 'train', train_file)#原训练集图片名,和train_file对应
#创建新文件夹‘data_dir/train_valid_test/train_valid',并创建类别文件夹
#这里厉害的是,fname和train_file对应,label也和train_file对应。所以训练集图片一一copy到类别文件夹而不会出错。
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label))
#每个类新来的图片和不到n_valid_per_label数量的图片直接copy到valid文件夹
#label_count是记录copy到valid的图片的类别数字典。每copy一次就+1
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label))
label_count[label] = label_count.get(label, 0) + 1
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label))
return n_valid_per_label
下面的reorg_test函数用来在预测期间整理测试集,以方便读取。(原test文件复制到’train_valid_test/test/unknown’文件夹)
#@save
def reorg_test(data_dir):
"""在预测期间整理测试集,以方便读取"""
for test_file in os.listdir(os.path.join(data_dir, 'test')):
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown'))
为了便于⼊⻔,我们使用tiny数据集(包含前1000个训练图像和5个随机测试图像)。要使⽤Kaggle竞赛的完整数据集,你需要将以下demo变量设置为False
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
3.1.3 数据预处理
- 整理数据集,设置超参数
设置tiny数据集的batch_size=32,完整cifar10的batch_size设置为更大的整数,例如128。 验证集比例取r=0.1。
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)
- 图像增广
我们使用图像增广来解决过拟合的问题。例如在训练中,我们可以随机水平翻转图像。 我们还可以对彩色图像的三个RGB通道执行标准化。 下面,我们列出了其中一些可以调整的操作。
transform_train = torchvision.transforms.Compose([
# 在高度和宽度上将图像放大到40像素的正方形
torchvision.transforms.Resize(40),
# 随机裁剪出一个高度和宽度均为40像素的正方形图像,
# 生成一个面积为原始图像面积0.64到1倍的小正方形,
# 然后将其缩放为高度和宽度均为32像素的正方形
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),
ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
#在测试期间,我们只对图像执行标准化,以消除评估结果中的随机性。
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
- 读取数据集
接下来,我们读取由原始图像组成的数据集,每个样本都包括一张图片和一个标签。
- train_ds:新训练集,valid_ds:验证集。这两个用于训练模型,调整超参数
- train_valid_ds:原训练集,这个用于最终的训练(就是把分出去的验证集也加进来使用)
- test_ds:测试集
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
- 训练集使用图像增广操作,验证集用于模型评估,不应引入图像增广的随机性。
- 在最终预测之前,我们根据训练集和验证集组合而成的训练模型进行训练,以充分利用所有标记的数据。
train_iter, train_valid_iter = [torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,
drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,
drop_last=False)
3.1.4 定义模型并开始训练
- 定义模型
我们定义了 7.6节中描述的Resnet-18模型。
def get_net():
num_classes = 10
net = d2l.resnet18(num_classes, 3)
return net
loss = nn.CrossEntropyLoss(reduction="none")
- 定义训练函数
我们将根据模型在验证集上的表现来选择模型并调整超参数。 下面我们定义了模型训练函数train。
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay):
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,
weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter is not None:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])#应用多GPU训练
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step()
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
- 训练和验证模型
现在,我们可以训练和验证模型了,而以下所有超参数都可以调整。 例如,我们可以增加周期的数量。当lr_period和lr_decay分别设置为4和0.9时,优化算法的学习速率将在每4个周期乘以0.9。 为便于演示,我们在这里只训练20个周期。
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 0.1, 0.001
lr_period, lr_decay, net = 10, 0.1, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay)
3.1.5 在 Kaggle 上对测试集进行分类并提交结果
在获得具有超参数的满意的模型后,我们使用所有标记的数据(包括验证集)来重新训练模型并对测试集进行分类。
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
for X, _ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv', index=False)
在这场Kaggle竞赛中使用完整的CIFAR-10数据集。将超参数设为batch_size = 128,num_epochs = 100,lr = 0.1,lr_period = 50,lr_decay = 0.1。看看你在这场比赛中能达到什么准确度和排名。或者你能进一步改进吗?
3.2 [96%] Fine-tuning ResNet34 with PyTorch
这段代码是此次kaggle比赛的一位选手的代码《[96%] Fine-tuning ResNet34 with PyTorch》
3.2.1 简介:使用 PyTorch 进行微调
在整个笔记本中,我们使用了来自 Kaggle 的 CIFAR-10 数据集,这是一个流行的计算机视觉数据集,包含 60,000 个 32x32 彩色图像,被分类为十个类别之一,每个类别有 6000 个图像。 该数据集足够复杂,可以很好地了解微调的好处,以及为什么可以使用此过程来获得高精度分数,而无需花费数小时和金钱从头开始重新训练复杂模型。 使用默认超参数和中型模型 (ResNet34),我们能够在 Kaggle 上实现大约 96% 的准确率,比该数据集的最新技术低 3%。
3.2.2 提取数据
Kaggle 提供的原始 CIFAR-10 数据集由两个 .7z 文件 (train.7z, test.7z)、标签 (trainLabels.csv) 和示例提交 (sampleSubmission.csv) 组成)。我们在 data 文件夹中提供这些文件。
首先,我们将两个压缩文件提取到两个名为 original_train 和 original_test 的文件夹中。然后,我们将这些文件移动到 PyTorch 的 ImageDataset 类所需的结构中,其中每个图像都存储在一个以其标签命名的文件夹中(例如,第 n 个飞机图像将存储在 *airplane/n.png *)。我们将在 data 中创建四个子文件夹:
- train:包含训练数据(不包括验证集),用于在超参数搜索期间训练模型
- valid:包含验证数据,用于在超参数搜索期间训练模型
- train_valid:包含训练+验证数据一起,用于模型的完全重新训练
- test 包含测试数据,即我们必须提交给 Kaggle 的所有未标记数据以及预测标签
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# py7zr is required to extract the .7tz files
!pip install py7zr
import py7zr
import shutil
from pathlib import Path
root = Path('./data')
input_path = Path('../input/cifar-10')
with py7zr.SevenZipFile(input_path/'train.7z', mode='r') as z:
z.extractall(root)
with py7zr.SevenZipFile(input_path/'test.7z', mode='r') as z:
z.extractall(root)
shutil.copy(input_path/'trainLabels.csv', root/'trainLabels.csv')
#train.7z, test.7z解压到original_train 和 original_test 文件夹
(root/'train').rename(root/'original_train')
(root/'test').rename(root/'original_test')
- img_index:不带扩展名的图片编号
- entry.name:图片文件名,带扩展名
打印出来就是:
| img_index | entry.name |
|---|---|
| 126979 | 126979.png |
| 180981 | 180981.png |
| 288998 | 288998.png |
另外关于mkdir函数:
mkdir(parents=True, exist_ok=True)
- parents:如果父目录不存在,是否创建父目录。
- exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
from random import random
import os
def copy_file(source_directory, destination_directory, filename):
"""
copy_file函数用于将source_directory下的文件复制到destination_directory下
"""
destination_directory.mkdir(parents=True,exist_ok=True)
shutil.copy(source_directory/filename,destination_directory/filename)
def organize_train_valid_dataset(root,labels,valid_probability=0.1):
"""
根据 PyTorch 的 ImageDataset 结构创建 train、train_valid 和 valid 文件夹
根据valid_probability拆分训练集和验证集。
"""
source_directory = root/'original_train'
with os.scandir(source_directory) as it:
for entry in it:
if entry.is_file():
img_index = entry.name.split('.')[0] # index是图像的名称,除了扩展名
#通过真假矩阵过滤,查找labels中索引entry的类别class
img_class = labels[labels.id==int(img_index)].label.values[0]
# 以概率“valid_probability”将图像随机拆分到valid文件夹
channel = Path('train') if random()>valid_probability else Path('valid')
destination_directory = root/channel/img_class
#将图像复制到 train 或 valid 文件夹,以及 train_valid 文件夹
#原始train训练集拆分为train和valid数据集,用来训练
#原始train训练集复制到'train_valid'文件夹,用于最终训练
copy_file(source_directory, destination_directory, entry.name)
copy_file(source_directory, root/'train_valid'/img_class, entry.name)
def organize_test_dataset(root):
"""
将test文件夹下的图片标记为‘undefined’,创建符合PyTorch ImageDataset结构的文件夹
"""
source_directory = root/'original_test'
with os.scandir(source_directory) as it:
for entry in it:
if entry.is_file():
img_index = entry.name.split('.')[0] #index是图像的名称,除了扩展名
channel = Path('test')
destination_directory = root/channel/'undefined'
copy_file(source_directory,destination_directory, entry.name)
import pandas as pd
# 用DataFrame格式读取'trainLabels.csv'
labels = pd.read_csv(root/'trainLabels.csv')
# 创建train/train_valid/valid 文件夹结构
valid_probability = 0.1
organize_train_valid_dataset(root, labels, valid_probability)
# 创建test 文件夹结构
organize_test_dataset(root)
3.2.3 加载数据集
如上所述,我们依靠 PyTorch 的 ImageDataset 类来创建训练、验证、训练+验证和测试所需的数据集。 然后,我们从每个数据集中创建一个 DataLoader,用于训练/评估循环,以有效地从磁盘批量获取图像。
我们执行初始步骤以加载训练数据并计算所有图像和所有像素的每个通道(R、G、B)的数据集的均值和标准差。 我们逐批计算平均值和标准差值以避免将整个数据集加载到内存中,然后计算平均值和标准差的平均值。
注意:如果您有足够的 RAM(或 GPU 上的内存),您可以使用等于整个 train_dataset 长度的 batch_size,它将提供更准确的通道估计均值和标准差。
读取整个train数据集,计算所有图片剪裁、转成tensor之后的均值和方差,用于下一步的标准化Normalize
import torchvision
import torch
"""这一步是为了计算数据集的均值和方差,用来在后面Normalize(mean, stdev)时
使用,而不是直接用ImageNet的数值Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])"""
train_dataset = torchvision.datasets.ImageFolder(
root/'train',
transform=torchvision.transforms.Compose([
# Resize step is required as we will use a ResNet model, which accepts at leats 224x224 images
torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(),
])
)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=512, shuffle=False, num_workers=2, pin_memory=True)
means = []
stdevs = []
for X, _ in train_dataloader:
# Dimensions 0,2,3 are respectively the batch, height and width dimensions
means.append(X.mean(dim=(0,2,3)))
stdevs.append(X.std(dim=(0,2,3)))
mean = torch.stack(means, dim=0).mean(dim=0)
stdev = torch.stack(stdevs, dim=0).mean(dim=0)
用于训练和训练+验证数据集的转换包括通过我们的 ResNet 模型 (224x224) 将图像大小调整到所需的分辨率,使用在 CIFAR10 数据集上学习的“AutoAugment”策略,最后将图像从 PIL 转换为 Tensor。 对于验证集和测试集,我们只需调整图像大小并将其转换为张量格式。
torchvision.transforms.AutoAugment函数,用于数据增强。参数有:
- policy (AutoAugmentPolicy):数据增强策略,可选有IMAGENET、CIFAR10 和SVHN
- interpolation:插值,默认为“InterpolationMode.NEAREST”。如果输入为 Tensor,则仅支持“InterpolationMode.NEAREST”、“InterpolationMode.BILINEAR”。
- full(序列或数字,可选):转换后区域的像素填充值图片。如果给定一个数字,该值将分别用于所有波段。
"""这部分代码基本和李沐老师的差不多"""
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((224,224)),
torchvision.transforms.AutoAugment(policy=torchvision.transforms.AutoAugmentPolicy.CIFAR10),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, stdev)])
train_dataset, train_valid_dataset = [torchvision.datasets.ImageFolder(folder, transform=train_transforms)
for folder in [root/'train', root/'train_valid']]
valid_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize((224,224)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, stdev)])
valid_dataset, test_dataset = [torchvision.datasets.ImageFolder(folder, transform=valid_transforms)
for folder in [root/'valid', root/'test']]
train 和 train+validation DataLoader 使用较小的“batch_size”,因为我们还需要跟踪内存中的梯度。 此外,我们在每个 epoch 打乱数据集以避免以相同的顺序加载批次。
valid的和test的 DataLoader 使用更大的 batch_size 并且不需要shuffle,因为我们想要确定性的结果。
作为 Kaggle 的经验法则,worker 的数量通常设置为 2 * num_gpus,使用 pin_memory = True 来加快数据传输到 GPU 的速度。
num_gpus = torch.cuda.device_count()
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True,
num_workers=2*num_gpus, pin_memory=True)
train_valid_dataloader = torch.utils.data.DataLoader(train_valid_dataset, batch_size=128,
shuffle=True, num_workers=2*num_gpus, pin_memory=True)
valid_dataloader = torch.utils.data.DataLoader(valid_dataset, batch_size=256, shuffle=False,
num_workers=2*num_gpus, pin_memory=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=256, shuffle=False,
num_workers=2*num_gpus, pin_memory=True)
3.2.4 训练
该过程的第一步是在我们自己的验证集上评估模型性能,验证集包含我们从 Kaggle 获得的 10% 的标记数据。 理想情况下,将在找到最佳模型和超参数以提高最终准确性的同时执行此步骤。 在这里,我们只是在将结果提交给 Kaggle 之前执行此步骤以显示预期的模型精度。
注意:在进行适当的超参数调整时,根据整体标签数据的大小,k-fold 方法可能更适合估计模型的泛化能力。
我们微调了一个在 ImageNet 上训练的 ResNet34 模型。 可能会使用其他模型,但就本笔记本而言,ResNet34 是训练时间和模型准确性之间的良好折衷。
该模型最初有一个 1000 维的输出层,但我们的数据集只有 10 个类,因此我们移除了输出层并定义了一个新的全连接层,其中只有 10 个神经元,CIFAR-10 中的每个类一个。 这些新神经元的参数通过 Xavier 初始化进行初始化。
def get_net():
resnet = torchvision.models.resnet34(pretrained=True)
# 替换FC输出层
resnet.fc = torch.nn.Linear(resnet.fc.in_features, 10)
torch.nn.init.xavier_uniform_(resnet.fc.weight)
return resnet
训练循环是一个标准的 PyTorch 循环,对于每个 epoch,我们执行以下宏步骤:
- 通过进行预测、计算损失、反向传播梯度和更新参数来迭代训练数据加载器
- 遍历 Valid DataLoader(如果存在)以计算验证损失和准确性
- 使用调度器(如果存在)降低学习率
- 一定的
checkpoint_epochs之后存储模型检查点(可选)
import time
def train(net,train_dataloader,valid_dataloader,criterion,optimizer,scheduler=None,epochs=10,device='cpu',checkpoint_epochs=10):
start = time.time()
print(f'Training for {epochs} epochs on {device}')
for epoch in range(1,epochs+1):
print(f"Epoch {epoch}/{epochs}")
net.train() # 将网络置于训练模式以进行 Dropout 和 Batch Normalization
train_loss = torch.tensor(0., device=device) # loss和accuracy在GPU上,以避免数据传输
train_accuracy = torch.tensor(0., device=device)
for X, y in train_dataloader:
X = X.to(device)
y = y.to(device)
preds = net(X)
loss = criterion(preds, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
train_loss += loss * train_dataloader.batch_size
train_accuracy += (torch.argmax(preds, dim=1) == y).sum()
if valid_dataloader is not None:
net.eval() # 将网络置于训练模式以进行 Dropout 和 Batch Normalization
valid_loss = torch.tensor(0., device=device)
valid_accuracy = torch.tensor(0., device=device)
with torch.no_grad():
for X, y in valid_dataloader:
X = X.to(device)
y = y.to(device)
preds = net(X)
loss = criterion(preds, y)
valid_loss += loss * valid_dataloader.batch_size
valid_accuracy += (torch.argmax(preds, dim=1) == y).sum()
if scheduler is not None:
scheduler.step()
print(f'Training loss: {train_loss/len(train_dataloader.dataset):.2f}')
print(f'Training accuracy: {100*train_accuracy/len(train_dataloader.dataset):.2f}')
if valid_dataloader is not None:
print(f'Valid loss: {valid_loss/len(valid_dataloader.dataset):.2f}')
print(f'Valid accuracy: {100*valid_accuracy/len(valid_dataloader.dataset):.2f}')
#设定多少个epoch之后保存模型
if epoch%checkpoint_epochs==0:
torch.save({
'epoch': epoch,
'state_dict': net.state_dict(),
'optimizer': optimizer.state_dict(),
}, './checkpoint.pth.tar')
print()
end = time.time()
print(f'Total training time: {end-start:.1f} seconds')
return net
在这个笔记本中,我们最多只使用一个 GPU,如果你有更多的 GPU 和/或设备,你可以自由地重构代码以使用 DistributedDataParallel。
微调时,网络主体的模型参数使用比头部更低的学习率进行训练,因为对于后者,我们必须从头开始训练它们。 我们依靠 PyTorch 的 Parameter Groups 为这两个组定义两个学习率,并使用带有 weight_decay = 5e-4 的 Adam 优化器(通过超参数搜索找到)。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
lr, weight_decay, epochs = 1e-5, 5e-4, 20
net = get_net().to(device)
criterion = torch.nn.CrossEntropyLoss()
# params_1x 是网络主体的参数,即除FC层之外的所有层的参数。设定fc层学习率是其它层的10倍
params_1x = [param for name, param in net.named_parameters() if 'fc' not in str(name)]
optimizer = torch.optim.Adam([{'params':params_1x}, {'params': net.fc.parameters(), 'lr': lr*10}], lr=lr, weight_decay=weight_decay)
net = train(net, train_dataloader, valid_dataloader, criterion, optimizer, None, epochs, device)
3.2.5使用全部训练集训练
在评估了验证集上的模型性能之后,我们希望在完整的训练 + 验证数据上重新训练模型,以在将结果提交给 Kaggle 之前压缩所有剩余的性能。 作为一般规则,我们训练的数据越多,结果就越好。
lr, weight_decay, epochs = 1e-5, 5e-4, 20
net = get_net().to(device)
criterion = torch.nn.CrossEntropyLoss()
params_1x = [param for name, param in net.named_parameters() if 'fc' not in str(name)]
optimizer = torch.optim.Adam([{'params':params_1x}, {'params': net.fc.parameters(), 'lr': lr*10}], lr=lr, weight_decay=weight_decay)
net = train(net, train_valid_dataloader, None, criterion, optimizer, None, epochs, device)
3.2.6 生成预测
在完整标记的数据集上重新训练网络后,我们准备对测试集进行评分并将结果提交给 Kaggle。 我们遍历 test_dataloader 以获得每个测试图像的预测标签,然后创建一个最终的 DataFrame,就像 sampleSubmission.csv 中提供的那样,以在 Kaggle 上使用。
preds = []
net.eval()
with torch.no_grad():
for X, _ in test_dataloader:
X = X.to(device)
preds.extend(net(X).argmax(dim=1).type(torch.int32).cpu().numpy())
ids = list(range(1, len(test_dataset)+1))
ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_dataset.classes[x])
df.to_csv('submission.csv', index=False)
四、 实战Kaggle比赛:狗的品种识别(ImageNet Dogs)(待补充)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)