学习笔记|Transformer——实现“序列to序列”的转换
机器学习中,我们有很多任务都是 “序列to序列” 的形式,比如语音识别、机器翻译、文本标注等等。而且在这些任务中,输入序列和输出序列的长度都是不定的,如么如何实现这种序列的转换呢?这就要用到一个很常见的网络架构— transformer 。transformer的一般结构如下图所示,包括编码(Encoder)和解码(Decoder)两个部分。Encoder对输入序列进行编码输出一个序列,转交给De
文章目录
1. Transformer 概述
在机器学习中,我们有很多任务都是 “序列to序列” 的形式,比如语音识别、机器翻译、文本标注等等。而且在这些任务中,输入序列和输出序列的长度都是不定的,如么如何实现这种序列的转换呢?这就要用到一个很常见的网络架构— transformer 。transformer的一般结构如下图所示,包括编码(Encoder)和解码(Decoder)两个部分。Encoder对输入序列进行编码输出一个序列,转交给Decoder,Decoder对这个序列进行解码,输出我们需要的序列。

2. Transformer的Encoder
首先,我们来看一下transformer的Encoder架构是怎样的。transformer对输入序列进行编码生成另一个长度相等的序列,如下图所示,这里假设输入序列是向量
x
1
、
x
2
、
x
3
、
x
4
x_1、x_2、x_3、x_4
x1、x2、x3、x4,对应的输出是向量
h
1
、
h
2
、
h
3
、
h
4
h_1、h_2、h_3、h_4
h1、h2、h3、h4。编码的目的实际上就要考虑序列的全局并聚焦重点,所以Encoder的核心就是自注意力机制,但不仅仅只有自注意力机制。

Encoder由多个Block组成,每个Block又由自注意力(self-attention)网络和全连接(full-connected)组成。向量
x
1
、
x
2
、
x
3
、
x
4
x_1、x_2、x_3、x_4
x1、x2、x3、x4通过自注意力网络后生成四个向量,这些向量是考虑了序列全局的,然后每个向量再通过一个全连接网络进行一次变换得到四个向量,通过几次Block后才输出向量
h
1
、
h
2
、
h
3
、
h
4
h_1、h_2、h_3、h_4
h1、h2、h3、h4。

实际上,Block的计算还有一些细节,如下图所示。具体包括两个方面:
- x 1 、 x 2 、 x 3 、 x 4 x_1、x_2、x_3、x_4 x1、x2、x3、x4通过自注意力网络后并不是直接输入到全连接层。首先,自注意力网络的输出向量与它的输入向量进行了求和。这种操作在深度网络中很常见,有一个专门的名字叫做残差(residual),残差操作的目的是为了防止梯度消失和网络退化。其次,经过残差操作后,进行了一次Layer normalization,把向量转化成均值为0方差为1的向量,即归一化。计算过程如下图所示(下面这个图有点错误,公式应当是 x i ′ = x i − m σ x'_i=\frac{x_i-m}{\sigma } xi′=σxi−m)。Layer normalization是为了防止向量落在激活函数的饱和区。经过上述两个过程的计算后,才得到全连接层的输入。
- 全连接层的输出也不是直接输出到下一层Block,同样经过了残差和Layer normalization的操作。

总结起来,Encoder的全部计算过程如下图所示,在一个Block中,首先经过一个Multi-Head Attention层,然后进行一次残差(residual)和Layer normalization操作,然后输入到一个全连接层(即Feed Forward),重复多个Block最后输出一个序列。
下面这个图值得注意的一个地方是输入向量并不是直接输入到Encoder,而是叠加了一个位置编码(Positional Encoding)。所谓位置编码是指将序列中某个向量所处的位置进行编码,生成一个与向量长度一样的向量,这对于自然语言处理是很重要的。例如进行此行标注的时候,句首的词是动词的可能性很小。位置编码的方式有很多,现在也有很多文章在研究一些新的方法,感兴趣的可以去研究一下。

3. Transformer的Decoder
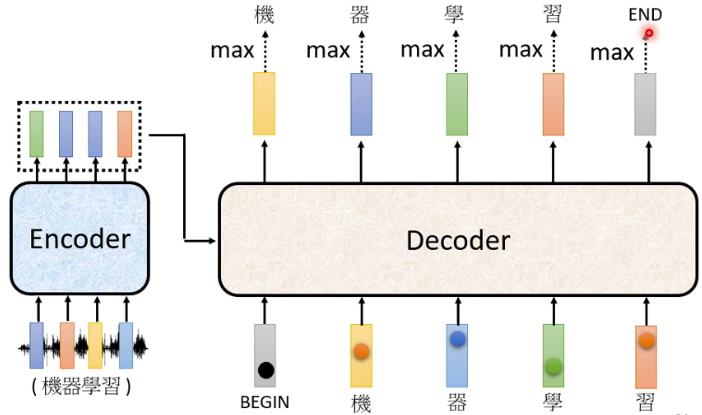
Encoder对输入进行编码后输出一个序列,Decoder则要根据这个序列输出我们最后想要的一个序列。以语音识别为例,我们对着机器说,“机器学习”。Encoder对我们的语音进行编码生成一个序列,Decoder就是要根据这个序列输出“机器学习”几个字,那么是如何实现的呢?
3.1 Decoder的自回归(Autoregressive)机制。
首先,我们要设置一个特殊的符号“Begin”作为输入,Decoder结合Encoder输出的序列和“Begin"这个输入产生一个向量。这个向量的长度非常长,长到和字典的大小相同。假如我们的字典是中文常用词3500字,那么这个向量的长度就是3500。这个向量再经过一个softmax操作,输出一个概率分布,概率最大的那个字就是“Begin”的输出。比如上面这个例子“机”字的概率最大,那么就输出“机”。

输出“机”之后,再将“机”作为Decoder新的输入。这样,Decoder的输入除了“Begin”之外,又多了一个“机”。通过Decoder和softmax之后,又输出一个“器”,然后又将“器”作为新的输入。重复上述过程,周而复始的将新的输出作为新的输入,又输出新的输出。

但是还有一个重要的问题,机器不能这么一直操作下去吧?在何时停止这个循环呢?这就需要在字典中再添加一个特殊的符号“End”。当输出一个“End”时,就停止上述循环,输出完整的序列。这样一个过程就是Decoder的自回归工作机制。那么Decoder的内部结构到底是怎样的呢?
3.2 Decoder的结构
Decoder的内部结构如下图所示,可以看出Decoder和Encoder的结构非常相似,但是有些许不同:首先在第一个自注意力层中多了一个"Masked"的字样,其次多了一个自注意力层。

首先,我们来看看第一个自注意力层多出个“Masked"是怎么回事。 前面讲自注意力机制的时候,我们讲输出
b
1
b^1
b1是考虑了输入序列全局的,即考虑了
a
1
、
a
2
、
a
3
、
a
4
a^1、a^2、a^3、a^4
a1、a2、a3、a4所有向量的信息,如下图所示。

但是注意到这里在输出”机“的时候,只能看到"Begin"一个向量,后面的向量是看不到的。对应的,如果我们假设”机“就是
b
1
b^1
b1,那么
b
1
b^1
b1只能利用
a
1
a^1
a1的信息,没法利用
a
2
、
a
3
、
a
4
a^2、a^3、a^4
a2、a3、a4的信息。同理,在输出“器”的时候,只能看到"Begin、机"两个向量,后面的向量也看不到,对应的
b
2
b^2
b2就只能利用
a
1
、
a
2
a^1、a^2
a1、a2的信息。以此类推,
b
3
b^3
b3就只能利用
a
1
、
a
2
、
a
3
a^1、a^2、a^3
a1、a2、a3的信息,
b
4
b^4
b4能利用
a
1
、
a
2
、
a
3
、
a
4
a^1、a^2、a^3、a^4
a1、a2、a3、a4的信息。

因此,Decoder的第一层自注意力网络多了一个“masked”。所谓“masked”就是盖起来的意思。比如在输出
b
2
b^2
b2时,是要把
a
3
、
a
4
a^3、a^4
a3、a4盖起来的,也就是将
α
2
,
3
′
、
α
2
,
4
′
\alpha^{'}_{2,3}、\alpha^{'}_{2,4}
α2,3′、α2,4′设为0即可,如下图所示,

现在我们已经理解了“masked”是怎么回事,接下来再看看多出一个自注意力层是怎么回事。 从下面这个图可以看出,多出来的自注意力层是连接Encoder和Decoder的桥梁,这一层称为“Cross attention”。

Cross attention的工作机制如下图所示,具体过程是:Decoder的输入通过masked self-attention层之后输出一个向量,该向量乘以一个转换矩阵得到一个向量
q
q
q。Encoder的输出序列乘以转换矩阵分别得到
K
K
K矩阵和
V
V
V矩阵,这里的
q
q
q再与上述
K
K
K矩阵和
V
V
V矩阵进行交叉计算得到一个新的向量
v
v
v。因此,Cross-Attention是利用Encoder自己的输入产生query向量
q
q
q,然后再去Encoder的输出序列中抽取信息,以作为输出。


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)