《Kubernetes监控篇:Prometheus+Grafana+Alertmanager监控K8S集群实战》
文章目录一、监控架构二、监控方案三、环境信息四、准备工作4.1、修改监听端口4.2、创建名称空间五、持久化存储5.1、安装nfs服务端5.2、安装nfs客户端5.3、安装nfs插件六、部署node-exporter6.1、资源下载6.2、资源说明6.3、部署node-exporter七、部署kube-state-metrics7.1、资源下载7.2、资源说明7.3、部署kube-state-me
文章目录
- 一、监控架构
- 二、监控方案
- 三、环境信息
- 四、准备工作
- 五、持久化存储
- 六、部署node-exporter
- 七、部署kube-state-metrics
- 八、钉钉告警机器人申请
- 九、部署webhook
- 十、部署Altermanager集群
- 十一、部署prometheus
- 十二、部署Grafana
- 十三、告警信息通知
- 十四、其他资源类型监控
- 十五、K8S监控资源合集下载
- 总结:整理不易,如果对你有帮助,可否点赞关注一下?
一、监控架构
架空架构图如下所示:
二、监控方案
这里主要介绍K8S基础组件、K8S资源对象、K8S主机资源等三方面监控信息。由于生产环境主机及数据量比较大,Prometheus联邦集群需要收费,所以这里采用的是多prometheus的方式对不同监控对象进行单独监控,后端存采用的是nfs共享存储的方式对prometheus及grafana数据出久华,告警通知采用的多alertmanager高可用的方式来实现,确保信息能正常发送。
建议:
1、条件允许情况下建议后端存储采用ceph的方式,支持动态扩容,nfs不支持动态扩容,需要部署前进行评估。
2、随着业务的扩大,prometheus中监控的指标会越来越多,查询的频率也在不停的增加,尤其是出现长时间汇总大量的计算指标数据的时候,会出现promql超时的情况,建议对prometheus进行recording rule优化。
3、Prometheus指标优化,建议对一些非核心指标通过drop action删除,减少存储数据量,提升查询速度
三、环境信息
环境信息如下所示:
| IP地址 | 系统版本 | 内核版本 | K8S版本 | 角色说明 |
|---|---|---|---|---|
| 192.168.1.227 | centos7.6 | 5.4.13 | 1.20.6 | master |
| 192.168.1.243 | centos7.6 | 5.4.13 | 1.20.6 | worker |
| 192.168.1.174 | centos7.6 | 5.4.13 | 1.20.6 | worker |
| 192.168.1.148 | centos7.6 | 5.4.13 | 无 | 后端存储(nfs) |
K8S相关信息如下图所示:
四、准备工作
4.1、修改监听端口
说明:默认在1.19之后10252、10251、10249都是绑定在127.0.0.1上的,如果想要通过prometheus监控,会采集不到数据,所以可以把端口绑定到物理机ip上,如果你的环境已经修改这一步可以忽略。 建议在安装kubernetes集群的时候进行如下操作,降低生产环境风险。
操作步骤如下:
#1、无需重启kubelet服务,在master节点修改kube-scheduler.yaml
# 如果是多master所有节点均需执行
[root@k8s-master-227 ~]# sed -i 's#127.0.0.1#192.168.1.227#g' /etc/kubernetes/manifests/kube-scheduler.yaml
#2、无需重启kubelet服务,在master节点修改kube-controller-manager.yaml
# 如果是多master所有节点均需执行
[root@k8s-master-227 ~]# sed -i 's#127.0.0.1#192.168.1.227#g' /etc/kubernetes/manifests/kube-controller-manager.yaml
#3、无需重启kubelet服务,在台master节点上把—port=0删除,否则会kubectl get cs会出现controller-manager和scheduler状态为Unhealthy
# 如果是多master所有节点均需执行
[root@k8s-master-227 ~]# sed -i '/port=0/d' /etc/kubernetes/manifests/kube-scheduler.yaml
[root@k8s-master-227 ~]# sed -i '/port=0/d' /etc/kubernetes/manifests/kube-controller-manager.yaml
#4、kube-proxy默认端口10249是监听在127.0.0.1上的,需要改成监听到物理节点上,线上建议在安装k8s的时候就做修改,降低风险
# 注意:如果是多master节点只需要在一个节点执行即可
[root@k8s-master-227 ~]# kubectl edit configmap kube-proxy -n kube-system
把metricsBindAddress这段修改成metricsBindAddress: 0.0.0.0:10249
# 5、重启kube-proxy(必须)
# 注意:如果是多master节点只需要在一个节点执行即可
[root@k8s-master-227 ~]# kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
如下图所示,即prometheus才能获取到kube-proxy、kube-controller-manager、kube-scheduler三个组件的数据
4.2、创建名称空间
由于个人习惯,将关于监控的所有pod都放置kube-monitor名称空间下,所以这里需要手动创建kube-monitor名称空间,如下所示:
[root@k8s-master-227 ~]# kubectl create ns kube-monitor
五、持久化存储
当前业务系统需要对监控的数据进行持久化存储,这里使用nfs作为动态storageClass存储,对prometheus监控数据进行持久化存储。
5.1、安装nfs服务端
说明:建议找一台单独且磁盘容量足够大的服务器作为nfs-server端。
# 1、安装nfs-server端
yum -y install nfs-utils rpcbind
systemctl start nfs && systemctl enable nfs
systemctl start rpcbind && systemctl enable rpcbind
# 3、创建共享目录
mkdir -p /data/volumes/{v1,v2,v3}
# 3、编辑配置文件
cat > /etc/exports << EOF
/data/volumes/v1 192.168.1.0/24(rw,no_root_squash,no_all_squash)
/data/volumes/v2 192.168.1.0/24(rw,no_root_squash,no_all_squash)
/data/volumes/v3 192.168.1.0/24(rw,no_root_squash,no_all_squash)
EOF
# 4、发布
[root@k8s-client volumes]# exportfs -arv
exporting 192.168.1.0/24:/data/volumes/v1
exporting 192.168.1.0/24:/data/volumes/v2
exporting 192.168.1.0/24:/data/volumes/v3
# 5、查看
[root@k8s-client ~]# showmount -e 192.168.1.17
Export list for 192.168.1.17:
/data/volumes/v1 192.168.1.0/24
/data/volumes/v2 192.168.1.0/24
/data/volumes/v3 192.168.1.0/24
5.2、安装nfs客户端
说明:当前环境kubernetes集群master节点和worker节点则为nfs客户端。
# 客户端不需要创建共享目录和编辑配置文件,只安装服务就行
yum -y install nfs-utils
5.3、安装nfs插件
说明:具有kubectl权限的主机。
官方测试资源下载
NFS动态存储StorageClass资源清单文件
1、修改deployment.yaml文件
2、创建账号
kubectl create -f rbac.yaml
3、创建nfs-client
kubectl create -f deployment.yaml
4、创建nfs-client kubernetes storage class
kubectl create -f class.yaml
5、设置StorageClass为默认
说明:默认的 StorageClass 将被用于动态的为没有特定 storage class 需求的PersistentVolumeClaims 配置存储:(只能有一个默认StorageClass),如果没有默认StorageClass,PVC 也没有指定storageClassName 的值,那么意味着它只能够跟 storageClassName相同的PV进行绑定。
kubectl patch storageclass managed-nfs-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
如下图所示:
6、测试pvc
[root@k8s-master-227 nfs]# kubectl apply -f test-claim.yaml
问题:创建的pvc一直处于pending状态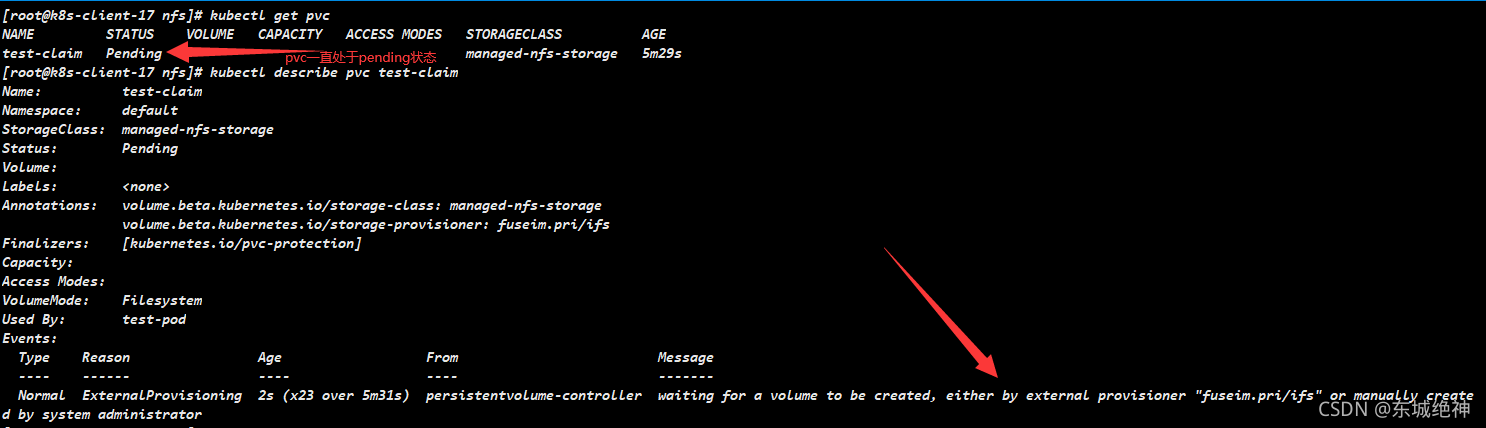
解决方案:分别在三个master节点上,修改/etc/kubernetes/manifests/kube-apiserver.yaml 文件,添加添加–feature-gates=RemoveSelfLink=false,当前kubernetes集群是使用kubeadm部署的,修改kube-apiserver.yaml 文件会自动重启apiserver服务,不用手动重启,如下图所示:
如下图所示,则表明pvc创建成功
7、测试pod
[root@k8s-master-227 nfs]# kubectl apply -f test-pod.yaml
如下图所示,则表示pod运行成功
查看nfs-server主机上共享目录/data/volumes/v1/,下面有SUCCESS文件
六、部署node-exporter
node-exporter用于采集服务器层面的运行指标,包括机器的loadavg、filesystem、meminfo等基础监控,类似于传统主机监控维度的zabbix-agent,node-export由prometheus官方提供、维护,不会捆绑安装,但基本上是必备的exporter。
6.1、资源下载
K8S监控宿主机资源node-exporter镜像及资源清单文件
亲自整理手动编写,资源列表如下所示:
6.2、资源说明
yaml文件说明:
1、建议不要修改名称空间
2、修改node-exporter.yaml文件中nodePort: 31000字段,必须设置为service-node-port-range范围之内,根据实际情况修改,这里采用NodePort方式暴露端口让node-exporter服务可以被集群外部访问。
6.3、部署node-exporter
1、安装部署
#在master节点上执行如下命令
[root@k8s-master-227 node-exporter]# kubectl apply -f node-exporter.yaml
[root@k8s-master-227 node-exporter]# kubectl get pods -n kube-monitor -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-8wdrk 1/1 Running 0 13m 192.168.1.227 k8s-master-227 <none> <none>
node-exporter-j4g6f 1/1 Running 0 13m 192.168.1.174 k8s-worker-174 <none> <none>
node-exporter-lqm9z 1/1 Running 0 13m 192.168.1.243 k8s-worker-243 <none> <none>
[root@k8s-master-227 node-exporter]# kubectl get svc -n kube-monitor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
node-exporter NodePort 10.96.34.103 <none> 9100:31000/TCP 13m
2、测试验证
七、部署kube-state-metrics
已经有了cadvisor、heapster、metric-server,几乎容器运行的所有指标都能拿到,但是下面这种情况却无能为力:
1、调度了多少个replicas?现在可用的有几个?
2、多少个Pod是running/stopped/terminated状态?
3、Pod重启了多少次?
4、我有多少job在运行中
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。
7.1、资源下载
CSDN:K8S资源对象监控kube-state-metrics-2.0.0镜像及资源清单文件
Github:K8S资源对象监控kube-state-metrics-2.0.0资源清单文件
参考官方手动修改,资源列表如下所示:
7.2、资源说明
说明:根据k8s集群版本选择对应的kube-state-metrics版本,默认是kube-state-metrics创建的svc是ClusterIP类型,只能被集群内部访问,如果需要被集群外部访问请修改service.yaml或者通过ingress代理的方式将端口暴露出来。我这里采用的是NodePort的方式让kube-state-metrics被集群外部访问。
1、官方资源和个人资源中yaml文件区别
1、个人资源中yaml文件是通过官方资源修改而来,所以不会有太大的变动
2、官方的yaml文件采用的是clusterip类型,默认名称空间为default
3、本人的yaml文件采用的是NodePort类型暴露端口,名称空间修改为kube-monitor
4、autosharding和standard区别,如果集群规模非常大建议选择autosharding,如果集群规模比较小可选择autosharding和standard
5、8080端口用于公开kubernetes的指标数据的端口,8081端口用于公开自身kube-state-metrics的指标数据的端口
6、如果采用我的yaml文件,根据k8s集群环境差异,只需修改service.yaml中的nodePort: 31001和nodePort: 31002字段,必须设置为service-node-port-range范围之内,根据实际情况修改,这里采用NodePort方式暴露端口让kube-state-metrics服务可以被集群外部访问
7、当前环境演示的autosharding模式
2、kube-state-metrics版本选择
7.3、部署kube-state-metrics
1、执行yaml文件
[root@k8s-master-227 kube-state-metrics]# kubectl apply -f autosharding/
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics created
serviceaccount/kube-state-metrics created
service/kube-state-metrics created
statefulset.apps/kube-state-metrics created
2、查看kube-state-metrics服务
[root@k8s-master-227 kube-state-metrics]# kubectl get pods -n kube-monitor -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-state-metrics-0 1/1 Running 0 16h 10.48.71.69 k8s-worker-174 <none> <none>
kube-state-metrics-1 1/1 Running 0 16h 10.48.71.70 k8s-worker-174 <none> <none>
[root@k8s-master-227 autosharding]# kubectl get svc -n kube-monitor -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kube-state-metrics NodePort 10.96.169.124 <none> 8080:31001/TCP,8081:31002/TCP 41h app.kubernetes.io/name=kube-state-metrics
3、测试验证
八、钉钉告警机器人申请
说明:命令行测试机器人发送消息,验证是否可以发送成功,有的时候prometheus-webhook-dingtalk会报422的错误,就是因为钉钉的安全限制(这里的安全策略是发送消息,必须包含prometheus才可以正常发送) 。
curl -H "Content-Type: application/json" -d '{"msgtype":"text","text":{"content":"告警测试,告警测试"}}' \
https://oapi.dingtalk.com/robot/send?access_token=xxxxxx
测试结果如下图所示:
九、部署webhook
9.1、资源下载
prometheus-webhook-dingtalk-1.4.0告警插件一键部署
目录信息如下所示
9.2、资源说明
部署前请仔细查看脚本帮助信息
9.3、部署webhook

十、部署Altermanager集群
10.1、资源下载
目录信息如下所示:
10.2、资源说明
说明:支持单机伪集群和分布式集群部署,具体部署步骤参看README.txt。
10.3、部署Altermanager
1、部署步骤如下所示
2、查看集群状态
十一、部署prometheus
11.1、Prometheus性能进行优化
1、服务维度拆分Prometheus
如果集群节点达到成千上万规模,对于一些节点级服务暴露的指标,比如kubelet内置的cadvisor暴露容器相关的指标信息,在集群规模大的情况下,这种单个服务背后的采集的指标数据就非常大。还有一些用户量访问特别多的业务,单个服务的pod副本数就可能上百个,这种服务的指标数据也非常大,针对上面这些大规模场景,一个Prometheus实例可能连这单个服务的采集任务都扛不住。Prometheus需要向这个服务所有后端实例发请求采集数据,由于后端实例数量规模太大,采集并发量就会很高,一方面对节点的带宽、CPU、磁盘IO都有一定的压力,另一方面Prometheus使用的磁盘空间有限,采集的数据量过大很容易就将磁盘塞满了。
优化建议如下:
针对以上场景,可以给这种大规模类型的服务做一下分片(Sharding),将其拆分成多个group,让一个Prometheus 实例仅采集这个服务背后的某一个group的数据,这样就可以将这个大体量服务的监控数据拆分到多个Prometheus实例上。简单的说就是部署多个prometheus,每个prometheus采集单个group的数据。
2、记录规则优化
11.2、Prometheus部署前操作
说明:在部署Prometheus 之前应该先创建serviceaccount、clusterrole、clusterrolebinding等对象,否则在安装过程中可能因为权限问题而导致各种错误。这里采用绕过复杂的RBAC设置,直接使用下面的命令将对应的serviceaccount设置成admin权限。
1、在master节点上创建sa账号,对sa做rbac授权,sa账号为monitor-sa
[root@k8s-master-227 ~]# kubectl create serviceaccount monitor-sa -n kube-monitor
[root@k8s-master-227 ~]# kubectl create clusterrolebinding monitor-clusterrolebinding -n kube-monitor --clusterrole=cluster-admin --serviceaccount=kube-monitor:monitor-sa
11.3、部署prometheus-node-exporter
说明:这里的prometheus-node-exporter是专门针对node-exporter类型的监控数据部署单个prometueus。
11.3.1、资源下载
K8S主机Prometheus监控node-exporter资源清单及镜像文件
亲自整理手动编写,资源列表如下所示:
configmap文件部分类容如下所示:
说明:资源里的yaml文件里花了大量时间整理并做了详细的注释,这里由于文件内容过多,无法一一展示,仅部分内容展示,如果需要全部资料,请通过上述链接下载。
11.3.2、资源说明
说明:部署前请仔细查看yaml文件,并根据自己环境实际情况对一些参数进行修改。
1、修改claim.yaml文件中的storage: 20Gi,建议根据实际情况填写存储大小空间,nfs不支持pvc在线扩容,生成环境一定要谨慎评估,条件允许情况下建议使用分布式存储ceph,支持在线扩容pvc。
2、修改configmap.yaml文件,[“192.168.1.227:9001”,“192.168.1.227:9002”,“192.168.1.227:9003”],这里配置的是alertmanager服务的ip和监听端口,当前环境因为是服务器有限,部署为同一台主机,建议生成环境分三台主机部署alertmanager,并根据实际情况填写。
3、修改service.yaml文件,默认nodePort: 32000,必须设置为service-node-port-range范围之内,根据实际情况修改,这里采用NodePort方式暴露端口让prometheus服务可以被集群外部访问。
4、yaml文件定义的namespace是kube-monitor,如果你不太会修改yaml文件,建议不要修改,因为涉及到的不仅仅是prometheus-node-exporter,其它所有的服务我这里都是统一放到kube-monitor名称空间下的,方便查看及统一标准。
5、告警规则文件参考https://awesome-prometheus-alerts.grep.to/rules,可直接搜索node-exporter会出现关于node-exporter指标的监控规则内容。
11.3.3、部署prometheus
1、执行yaml文件
2、查看prometheus服务
3、浏览器输入http://192.168.1.243:32000,查看target
4、查看Alerts
5、alert指标参数详解,如下图所示:
6、查看监控数据
说明:如上所示则表明Prometheus已经采集到了node-exporter相关数据。
11.4、部署prometheus-kube-state-metrics
说明:这里的prometheus-kube-state-metrics是专门针对-kube-state-metrics类型的监控数据部署单个prometueus。
11.4.1、资源下载
K8S主机Prometheus监控kube-state-metrics资源清单及镜像文件
亲自整理手动编写,资源列表如下所示:
configmap文件部分类容如下所示:
说明:资源里的yaml文件里花了大量时间整理并做了详细的注释,这里由于文件内容过多,无法一一展示,仅部分内容展示,如果需要全部资料,请通过上述链接下载。
11.4.2、资源说明
说明:部署前请仔细查看yaml文件,并根据自己环境实际情况对一些参数进行修改。
1、如果在部署prometheus-node-exporter时已经创建sa账号并进行rbac授权,则这一步可忽略
2、修改claim.yaml文件中的storage: 20Gi,建议根据实际情况填写存储大小空间,nfs不支持pvc在线扩容,生成环境一定要谨慎评估,条件允许情况下建议使用分布式存储ceph,支持在线扩容pvc。
3、修改configmap.yaml文件,[“192.168.1.227:9001”,“192.168.1.227:9002”,“192.168.1.227:9003”],这里配置的是alertmanager服务的ip和监听端口,当前环境因为是服务器有限,部署为同一台主机,建议生成环境分三台主机部署alertmanager,并根据实际情况填写。
4、修改service.yaml文件,默认nodePort: 32001,必须设置为service-node-port-range范围之内,根据实际情况修改,这里采用NodePort方式暴露端口让prometheus服务可以被集群外部访问。
5、yaml文件定义的namespace是kube-monitor,如果你不太会修改yaml文件,建议不要修改,因为涉及到的不仅仅是prometheus-kube-state-metrics,其它所有的服务我这里都是统一放到kube-monitor名称空间下的,方便查看及统一标准。
6、告警规则文件参考https://awesome-prometheus-alerts.grep.to/rules,可直接搜索node-exporter会出现关于node-exporter指标的监控规则内容。
11.4.1、部署prometheus
1、执行yaml文件
2、查看prometheus服务
3、浏览器输入http://192.168.1.243:32001,查看target
4、查看Alerts
5、alert指标参数详解,如下图所示:
6、查看监控数据
说明:如上所示则表明Prometheus已经采集到了kube-state-metrics相关数据。
11.5、部署prometheus-kubernetes
说明:这里的prometheus-kubernetes是kubernetes-apiserver、kubernetes-controller-manager、kubernetes-kubelet、kubernetes-kube-proxy、kubernetes-etcd、kubernetes-cadvisor类型的监控数据部署单个prometueus。
11.5.1、资源下载
K8S主机Prometheus监控基础组件资源清单及镜像文件
亲自整理手动编写,资源列表如下所示:
configmap文件部分类容如下所示:
11.5.2、资源说明
说明:部署前请仔细查看yaml文件,并根据自己环境实际情况对一些参数进行修改。
1、修改claim.yaml文件中的storage: 20Gi,建议根据实际情况填写存储大小空间,nfs不支持pvc在线扩容,生成环境一定要谨慎评估,条件允许情况下建议使用分布式存储ceph,支持在线扩容pvc。
2、修改configmap.yaml文件,[“192.168.1.227:9001”,“192.168.1.227:9002”,“192.168.1.227:9003”],这里配置的是alertmanager服务的ip和监听端口,当前环境因为是服务器有限,部署为同一台主机,建议生成环境分三台主机部署alertmanager,并根据实际情况填写。
3、修改service.yaml文件,默认nodePort: 32002,必须设置为service-node-port-range范围之内,根据实际情况修改,这里采用NodePort方式暴露端口让prometheus服务可以被集群外部访问。
4、yaml文件定义的namespace是kube-monitor,如果你不太会修改yaml文件,建议不要修改,因为涉及到的不仅仅是prometheus-kube-state-metrics,其它所有的服务我这里都是统一放到kube-monitor名称空间下的,方便查看及统一标准。
5、告警规则文件参考https://awesome-prometheus-alerts.grep.to/rules
11.5.3、部署prometheus
1、在master节点创建secret,将需要的etcd证书保存到secret对象etcd-certs中
[root@k8s-master-227 ~]# kubectl create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt -n kube-monitor
2、执行yaml文件
3、查看prometheus服务
4、浏览器输入http://192.168.1.243:32002,查看target
5、查看Alerts
6、查看监控数据
说明:如上所示则表明Prometheus已经采集到了k8s基础组件的相关数据。
十二、部署Grafana
12.1、资源下载
资源目录文件如下所示:
12.2、资源说明
说明:部署前请仔细查看yaml文件,并根据自己环境实际情况对一些参数进行修改。
1、修改claim.yaml文件,默认storage: 20Gi,建议根据实际情况填写,nfs不支持pvc扩容,生成环境一定要谨慎评估。
2、修改service.yaml文件,默认nodePort: 33000,必须设置为service-node-port-range范围之内,根据实际情况修改,这里采用NodePort方式暴露端口让prometheus服务可以被集群外部访问。
3、修改deployment.yaml文件中spec.template.spec.containers.resources字段的内存和cpu配置,根据实际情况进行优化。
12.3、部署Grafana
1、执行yaml文件
2、查看grafana服务
3、浏览器输入http://192.168.1.135:33000
12.4、导入数据源
说明:这里的数据源均采用的是prometheus
12.4.1、导入node-exporter数据源
说明:在Grafana中添加 DataSource,域名使用service name prometheus-node-exporter即可,这样可以通过内网去访问,即使prometheus-node-exporter调度到另外一台主机也不影响数据的接入。
service name如下图红色箭头所示:
http url如下图所示:
12.4.2、导入kube-state-metrics数据源
说明:在Grafana中添加 DataSource,域名使用service name prometheus-kube-state-metrics即可,这样可以通过内网去访问,即使prometheus-kube-state-metrics调度到另外一台主机也不影响数据的接入。
service name如下图红色箭头所示:
http url如下图所示:
12.4.3、导入K8S集群基础组件数据源
说明:在Grafana中添加 DataSource,域名使用service name prometheus-kubernetes即可,这样可以通过内网去访问,即使prometheus-kubernetes调度到另外一台主机也不影响数据的接入。
service name如下图红色箭头所示:
http url如下图所示:
12.5、导入监控模板
12.5.1、导入node-exporter监控模板
说明:这里采用的是K8S集群主机资源监控node-exporter监控模板是本人根据自己的喜好和环境编辑而成
(图一)效果如下图所示:
(图二)效果如下图所示:
(图三)效果如下图所示:
12.5.2、导入kube-state-metrics监控模板
说明:这里采用的是K8S集群资源对象kube-state-metrics监控模板是根据官方13332模板修改而成,更加个性化。
(图一)效果如下图所示:
12.5.3、导入K8S集群基础组件监控模板
说明:这里采用的是K8S集群基础组件监控模板,根据个人喜好和环境编辑而成。
(图一)效果如下图所示:
(图二)效果如下图所示:
(图三)效果如下图所示:
十三、告警信息通知
效果如下图所示:

十四、其他资源类型监控
《Kubernetes监控篇:kubernetes集群SSL证书监控实战》
《Kubernetes监控篇:Kubernetes集群blackbox-exporter监控实战(方案一)》
《Kubernetes监控篇:Kubernetes集群blackbox-exporter监控实战(方案二)》
十五、K8S监控资源合集下载
总结:整理不易,如果对你有帮助,可否点赞关注一下?
更多详细内容请参考:企业级K8s集群运维实战

开源、云原生的融合云平台
更多推荐
 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)