
社区发现基础
社区发现社区网络基本知识由数量巨大的节点和节点之间具有错综复杂连接关系的边所构成的大型网络统称为复杂网络。节点代表实体,边代表实体之间的关系。复杂网络的性质复杂网络中存在的共同性质包括小世界特性、无标度特性、高聚集特性和社区结构。小世界性是指复杂网络具有短路径长度和大的聚类系数的特点,平均路径长度值较小,通常其数量级不超过 10。(如六度分割理论)无标度性是指复杂网络中节点的度分布服从幂率分布。(
社区发现
社区网络基本知识
由数量巨大的节点和节点之间具有错综复杂连接关系的边所构成的大型网络统称为复杂网络。节点代表实体,边代表实体之间的关系。
复杂网络的性质
复杂网络中存在的共同性质包括小世界特性、无标度特性、高聚集特性和社区结构。
小世界性是指复杂网络具有短路径长度和大的聚类系数的特点,平均路径长度值较小,通常其数量级不超过 10。(如六度分割理论)
无标度性是指复杂网络中节点的度分布服从幂率分布。(说明不是一个随机网络,因为随机网络应该服从的是泊松分布)无标度网络中有大量度比较小的节点,而随机网络中这样的节点很少出现,随机网络中大多数的节点度在平均度附近,而且无标度网络中大度节点(枢纽节点)的概率也要大很多。
社区结构是指网络拓扑结构中表现出来的社团化特征,整个网络由若干个社团构成,并保证每个社团内的节点之间的连接相对非常紧密,但是各个社团之间的连接相对比较稀疏。
研究社区发现的意义
社区发现的研究工作具有很多现实意义,人们通过挖掘和识别社区结构可以了解网络中含有的丰富内容,理解网络社团组织结构的发展规律以及它们之间拓扑结构的相互关系等。另外,社区发现在个性化信息服务方面的表现极为突出,有效地发现社区结构后,可进一步地根据社区中成员的需求喜好、兴趣、位置区域和行为方式等,为他们推荐和提供特定的服务
社区发现介绍
如果将复杂网络模型转化为一张包含众多节点和连边的图,那么社团结构就是一张特殊的子图。它由一些相似的相互连接的顶点构成,并且保证同一社区内部的节点间连接密度要高于不同社区间的连接密度。
寻找网络中存在的不相交社区结构的过程称为社区发现
强社区定义下,每个节点对于社区内的连接都要比其与社区外部的连接要多。在实际中,这个要求往往显得过于严格。在弱社区意义下,子图内所有节点在内部的度数之和要比在外部的度数之和大。很明显,如果一个社区是强社区结构,那么它一定也是弱社区结构。在实际的应用中,大多数算法发现的社区结构均为弱社区。
“社区内边密度”和“社区间边密度”两种度量:其表示社区的内部边密度必须大于整个网络的边密度,同时,社区的外部边密度必须小于整个网络的边密度。
网络中存在着节点同时属于多个社团的情况,即网络中社区结构具有一个重要性质—重叠性。网络中那些同时隶属于不同社区的节点被称为重叠节点,和某些社区之间共享重叠节点的社区被称为重叠社区。
传统的社会网络分析方法专注于静态网络的研究,主要研究如何在网络中确定有意义的社团结构。但是在许多复杂网络中,实体间的交互随时间动态变化,而网络的变化必然导致其中的社区结构也随着时间有所变化。这样随着时间变化而导致结构发生变化的社区就称为动态社区。
动态社区发现主要目标是发现不同时刻下的社区结构,主要研究的是发现动态社区结构的方法,以此来揭示网络中隐含的不断动态变化的社区结构。一般情况下,动态社区发现的前提是假设社区变化相对平缓(社区变化波动不大)并且网络变化中会含有核心稳定社区结构
根据网络节点是否变化可以将其分为静态社区发现和动态社区发现,根据网络社区结构是否重叠可将其分为社区发现和重叠社区发现。
社区结构的评价
要验证和评价发现的社区结构的优劣通常有两类方法,分别针对不同的情况:一类是社区结构己知的情况,这种情况主要是针对某种网络模型所生成的基准网络;还有一些少量的现实网络中己知的结构如在线社交网络中的隶属关系等(包括:公司、学校和亲友关系),此时需要的是将两个不同集合进行比较,即将算法发现的社区结构同己知的社区结构进行比较,最常用的两种比较适合的方法是互信息量NMI和Omega指数。另一类是社区结构未知的情况,现实中大多数的网络的社区结构几乎都是未知的,此时需要根据网络自身的实际结构,对发现出的社区进行全局评价,而目前大部分此类评价方法都是由提出的模块度函数扩展而来。







社区发现方法概述
这些算法并没有严格的边界,彼此之间可能存在相互交错,譬如LPA(Modularity-Specialized Label Propagation Algorithm)算法既可归入标签传播算法,又可以是模块度优化算法;而 BGLL(Blondel-Guillaume-Lambiotte-Lefebvre)算法和 CNM(Clauset-Newman-Moore)算法既属于模块优化算法,又带有层次算法的特征,还有很多算法是来自于不同应用领域的算法的结合。


基于相似性聚类的社区发现算法:
此类方法只考虑网络节点之间的相似度来对节点进行聚类,而忽略了节点本身的属性及其相互影响。处于网络空间中的节点不能简单的通过距离来进行相似度的判定,而应该借鉴一些用于计算空间物体相互作用的方法。由于拓扑结构能够较为真实地反映出复杂网络的一些基本特性,所以常采用的节点相似性度量标准有节点间共有的邻居个数,节点间的最短路径,节点间的余弦相似性,节点间的 Jaccard 相似性等。在得出网络节点间的相似性计算结果后,就可以通过层次聚类,谱聚类,k -均值聚类等算法按照一定的参考标准将节点划分到相应的社区。
基于模块度的社区发现算法 :
基于模块度优化的社区发现算法实际上就是通过最大化质量函数Q 来获得较好的社区划分,其得分越高,那么所检测出的社区结构就越符合于客观的事实。
全局模块度
设Avw为网络的邻接矩阵的一个元素,定义为:
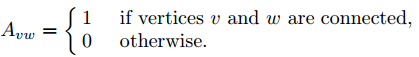
假设cv和cw分别表示点v和点w所在的两个社区,社区内部的边数和网络中总边数的比例:
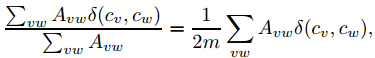
函数δ(cv,cw)的取值定义为:如果v和w在一个社区,即cv=cw,则为 1,否则为 0。m 为网络中边的总数。
模块度的大小定义为社区内部的总边数和网络中总边数的比例减去一个期望值,该期望值是将网络设定为随机网络时同样的社区分配所形成的社区内部的总边数和网络中总边数的比例的大小,于是模块度Q为:
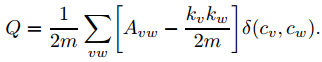
其中kv表示点v的度。
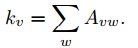
设eij表示社区I和社区J之间的连接边和与总边数的比例,ai表示社区i内部的点所关联的所有的边的数目与总边数的比例。
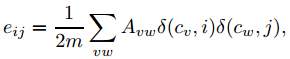
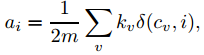
为了简化Q的计算,假设网络已经划分成n个社区,这个时候就有一个 n维矩阵,Q 的计算可以变成:
eii表示的是节点全在社区i内部中的边所占的比例
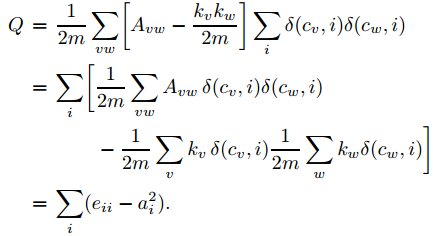
模块度的物理意义是,网络中连接两个同种类型结点的边(即社区内部的边)的比例减去在同样的社区结构”下任意连接节点的边的比例的期望值。如果社区内部边的比例不大于任意连接时的期望值,则有Q=0。Q的上限为1,而Q越接近于这个值,就说明社区结构越明显。实际网络中,该值通常位于0.3-0.7之间。
基于该种思想的算法主要有 GN(Girvan-Newman)算法,FN(Fast Newman)算法,仿真退火算法等。模块度的方法其实有双重作用,它既可以用来找寻社区划分,又可对检测出的社区结构进行质量评估,其实其最初的设计目的就是用来对 GN快速社区检测算法进行质量评估的。随着研究的深入,该模型也受到了研究者的普遍认可,在此基础上,衍生出了大量与模块度相关的算法,其中以 Louvain算法最为出名。
Louvain 算法是建立在贪心思想基础上的模块度最大化算法,可看作一种两阶段的社区模块度增益算法。在第一阶段,将网络中的每个节点都分配到一个独立的社区当中,然后通过不断合并节点以使模块度朝着增益最大的社区方向移动,直至模块度不再增加则停止合并。在第二阶段,Louvain 算法将第一阶段中通过节点合并所得到的社区看成一个超节点,将社区间的连接看成超节点的边,然后重复第一阶段的过程,直至社区模块度不再增加为止。经实践证明,只需少数的几次迭代就可使算法快速收敛,且节点只在相邻的社区间进行移动,
故在时间效率上要优于之前的许多算法。Rotta 等在 Louvain 算法的基础上又加入了更多层次的细化阶段。
同样基于贪心思想的模块度优化算法还有 FN 算法,但是相较于 FN 算法采用初始边存储矩阵来计算模块度增量,此处更推崇使用直接构造模块度增益矩阵并结合堆结构来计算和更新模块度增量以求获得最大模块度社区结构的 CNM 算法。凭借该种机制,只需存储那些通过边直接相连的社区即可(无边相连的社区结构不可能对社区模块化的整体增益造成影响),这明显降低了算法的空间复杂度。
基于模拟退火的模块度极大化算法,这种算法采用单一节点和节点集合的移动来获取最大的模块度收益。一开始,通过随机法获得一个初始的解,之后在每次的迭代过程求解过程中,在现有解的基础之上产生新的候选解(由模块度函数来进行优劣判断),结合模拟退火思想中的 Metropolis 准则来决定是否接纳该候选解。具体的候选解产生思路是:(1)允许网络节点移动到其它的社区中;(2)在不同的社区之间交换节点;(3)合并或者分解当前存在于网络结构中的社区。该算法在某种概率范围内允许使用较差的候选解而抛弃相对较好的候选解,但却存在越过局部最优圈套而发现全局最优解的可能。
此外,受自然环境中生物群落的自聚类现象的影响,Ye 等提出了一种基于模块度最优化思想的自适应聚类算法(Adjust Cluster)。其核心内容是使用模块度来定义外部社区对网络节点的拉力(Fout )和内部社区对于节点的引力(Fin)。首先把所有节点随机分配到各自对应的社区中,然后按照节点自身的局部范围信息来求解Fout 和Fin,通过两种力量的大小对比,来决定节点是留在当前的社区还是移动到新的社区当中去。鉴于该算法是建立在模块最大化基础上的一种自我调整模型,迭代计算结束的标志是网络中不再有节点移动,此刻节点间通过聚类的方式聚集在具有相同或相似属性的社区结构内,对外表现出一种良好的共性特征。近年来,越来越多的智能化仿生计算模型也加入到网络社区发现的算法研究中来用于对模块度函数进行优化求解,如蚁群算法、遗传算法等。
局部模块度
有时候,可能不知道全网络的数据,可以用局部社区的局部模块度的方式来检查社区的合理性。假设有一个已经检测出来的社区,社区的节点的集合为V,这些节点所有的邻接节点而加入到集合当中来,形成新的集合V*。定义V*的邻接矩阵为:

于是,和全局模块度相似的是,可以用节点集V全部属于节点集V*中的元素所占的比例的大小来衡量一个社区的好坏:
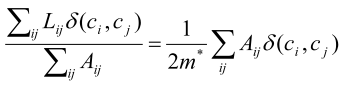
其中,δ(i,j)表示的是如果i,j都是V中则值为1,否则为0。m*表示的是邻接矩阵内边的数目。
局部模块度比全局模块度要快的多,因为局部模块度的计算只需要用到局部的网络信息,只需要在刚刚开始的时候扫描一下整个网络。对于中小规模的网络可能局部模块度的效果要低于全局模块度,但是而且对于中等或者大规模的社会网络来说,局部模块度的效果可能还要好一些。
基于图划分的社区发现算法:
GN 边介数算法最初就是借鉴基于图划分的思想来进行网络社区的发现。通过将节点边介数的概念扩展为边介数(Edge betweenness)后,可得出存在于社区之间的边具有较高的边介数,而社区内部的边则只有很低的边介数。由于节点对之间的最短路径是采用社区间的边来度量的,那么对于网络中的任意节点对来说,它们之间存在的最短路径条数就被视为该边的边介数。在此基础上,移除边介数较大的对象,就隐含地说明移除存在于社区之间的边连接,如此循环,便可构建出一棵自顶向下的聚类层次树(Dendrogram)。通过按序移除网络中边介数最大的边,即可较为直观的将社区从复杂的网络结构中剥离出来,直到社区模块度不再增加为止.
而采用 Information Centrality 作为网络边移除准则的算法其主要思想是如果网络中的某条边被移除后,节点对之间的信息传递速率就会减慢(即节点间的路径变长了),那么该边很可能就是节点间的边介边,与社区结构的发现有关。
基于概率生成模型的社区发现算法:
此类方法可看作是以统计推理为特征的一类特定算法,通过假设连接节点对的边的出现概率来构造算法模型用以对原始网络进行模拟,然后推理出与客观事实相符的且能代表该网络特征的社区结构。常见的几种概率统计模型主要包括贝叶斯估计、混合模型算法和块建模等
基于动力学模型的社区发现算法 :
复杂网络模型的特征之一就是具有动态性,主要表现为:(1) 网络社区内部节点间的关系在短暂的时间间隔内可能会发生变化;(2) 社区内部节点的状态变化是无法预测的,具有随机性的特点;(3) 社区内部节点之间的亲密程度要远大于社区之间的节点,即使是处于动态变化过程中。基于上述网络动态特征,衍生了一系列基于动力学的社区发现算法,例如标签传播算法模型,基于同步思想的算法模型和基于随机游走的算法模型等
基于半监督学习的标签传播算法模型(LPA),LPA 的主要思想是用被标记过的带有标签属性网络节点去预测那些没有被标记过的节点的标签属性,在标签的传播过程中,通过判定每个节点与它的相邻节点的相似性,然后根据相邻节点的标签属性来进行自我更新。如果标签属性越一致,就表明某节点受相邻节点的影响越大,它们就越趋于相似。但是,LPA 算法只允许每个节点只属于一个社区,换句话说它只能用于没有重叠现象的社区发现.
Xie 等人提出了一种可模仿信息扩散过程的标签传播算法 SLPA(Speaker-listener Label Propagation Algorithm)。有别于其它算法,SPLA 不会忘记上一轮迭代后的节点标签更新信息,它将采用节点标签存储列表的方式来记录每次迭代后的结果。根据节点标签在存储列表里出现的概率,即某个节点的标签出现频率要远远大于其它的标签时,便可推测该节点属于这个标签标记的社区,而且在扩散过程
中还有可能会影响到其它的节点。此外,该算法模型中的存储标签列表还可用于重叠社区结构的发现。
大多数以随机游走模型为基础的社区发现算法都是基于这样的一个认知:假设网络中存在含义明确的社区结构,从网络的某一点出发,随机游走者沿着某一网络路径行进,经历一段时间的累积后,随机游走者很有可能会停留在具有较强社区结构的社区内部。究其原因是由于社区内部的边连接密度要远远大于社区之间的边连接密度,而且社区内部节点的边连接也大都指向其社区内的成员,使得随机游走者在社区内部会停留很长的时间.
基于谱聚类的社区发现算法:
谱聚类算法起源于图的划分问题,是以严格的矩阵论和凸优化理论作为支撑的向量划分问题,与传统的聚类算法相比,不仅易于实现,而且常能取得较高的聚类精度。该方法一般采用先求解网络节点邻接矩阵的特征向量(也可是邻接矩阵的拉普拉斯矩阵),然后在第二小的特征值所对应的特征向量中,抽取v 个特征向量,而网络中的任意节点可被视为这v 个特征向量空间中的一个点(即抽取的v 个特征向量中的第 k 个元素构成了网络中第 k 个节点的坐标信息),其节点相似性可通过向量间的夹角或者距离来进行判定,最后按照某种节点聚类算法来获得网络结构的社区划分.
基于网络局部优化的社区发现算法 :
从宏观上看,网络社区结构本身就是属于一种局部特征,它的组成只与其社区内部的节点和边连接有关,而与网络拓扑结构的其它部分区域无关。所以,使用基于局部网络信息的社区发现算法在理论上应该更加符合社区结构的定义,常用的基于网络局部结构特征的算法有:基于局部扩展优化算法、派系过滤算法及标签传播算法等。
基于局部的扩展优化算法一般只关注节点所在的社区,而忽略掉网络的其它部分。所采用的基本模型是先根据网络的拓扑结构来定义健康函数,然后从选定的社区中按照种子节点开始迭代并不断向周围扩散,直到定义的健康函数值不再增加时,即可得到一个该网络的最优社区划分.Lancichinetti 等人提出了一种只搜寻那些还没有被划分到社区结构中的节点当前所属的社区,称为LFM(Local Fitness Maximization)算法
CPM 算法的主要是想是:首先社区是由一系列相互连通的完全子图所组成的,相邻的两个k -派系应当至少共享k 1个节点,任意一个k -派系只能唯一的从属于网络中的某个社区,而从属于不同社区内部的 k -派系可能存在网络节点共享的情况。通过探寻网络结构中的最大完全子图,在此基础上进一步查找包含k -派系的极大连通子图,即可获得最终的社区划分。但是,在给定的网络中寻找最大完全子图的问题仍然是一个 NP 完全困难问题。
复杂网络社区发现算法评估标准
目前,针对不同的检测情况,可将其归纳为两类。第一类是将网络社区结构作为先验性的知识,主要针对通过计算机生成的网络模型,以及一些具有客观事实并存在于真实世界中的网络模型等,在这种情况下,只需将社区发现算法所探测到的社区结构与已知的社区结构进行信息对比即可,比较常用的评估准则包括归一化互信息NMI和 Omega 指数.第二类是网络中的社区结构没有客观事实作为补充说明的情况,真实世界中的绝大多数复杂网络都属于这一类。由于没有客观参考,就只能依据网络本身的拓扑情况及其它一些附加信息来对社区发现结果做出定性的评估,现存的大多数此类社区发现评价标准都是由 Newman 模块度优化函数扩展形成的.

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)