
Elastic:IK分词器分词、停用词热更新如何配置(一)基于API
1. 基于API实现热更新在ik的github有关于热更新的介绍1.1 基于API的热更新的前置知识热更新是IK新版本中才支持的功能,其API需要满足两个要求:1、http请求中需要返回两个header,一个是Last-Modified,一个ETag。两个header都是字符串类型的。他们之中只要有一个发生变化,就会读取详情的数据并且更新词库,如果没有变化则不会更新词库。这个条件如果做前端的同学应
1. 基于API实现热更新
在ik的github有关于热更新的介绍
1.1 基于API的热更新的前置知识
热更新是IK新版本中才支持的功能,其API需要满足两个要求:
1、http请求中需要返回两个header,一个是Last-Modified,一个ETag。两个header都是字符串类型的。他们之中只要有一个发生变化,就会读取详情的数据并且更新词库,如果没有变化则不会更新词库。这个条件如果做前端的同学应该会比较熟悉,前端判断缓存是否更改时也是通过这两个条件。
Last-Modified是上次更新时间
ETag是实体标签(Entity Tag)的缩写,根据实体内容(文本数据)生成的一段hash字符串,可以通过它的标识数据的修改状态,当数据发生改变时,ETag也随之改变
2、返回的内容格式是一行一个分词,换行符用\n
1.2 思路
分词文件可以存放在一个文本文件中,注意文件需要时UTF-8编码格式的。放在nginx或者其他简易http server下,当文件修改时,http server会在客户端请求该文件时自动返回相应的Last-Modified和ETag。
另外可以做一个工具来从业务系统提取相关词汇,再更新到这个文件中
1.2.1 如何设置ETag的值
首先ETag要满足以下三个条件:
1、当文件内容改变时,ETag值跟着改变
2、计算简单,不会特别消耗CPU(因此就不能使用MD5、SHA128、SHA256等算法)
3、必须支持横向扩展,也就是在不同的服务器节点上生成的ETag是一样的
参考Nginx中ETag的生成:
由Last-Modified和content_length表示为16进制组合而成
etag = '"' + Long.toHexString(lastModified) + '-' + Long.toHexString(contentLength) + '"';
1.2.2 有了Last-Modified为什么还需要ETag?
开始之前我们先思考这个问题来帮助我们进一步理解热更新:有了Last-Modified为什么还需要ETag
1、原因就是因为某些服务器如果不能精确的获取到数据的最后修改时间的话,那么就无法通过Last-Modified来判断数据是否有更新了,就会导致词库更新不及时,出现延迟的问题。
2、Last-Modified一般只能精确到秒,如果数据更新的比较频繁的话,会导致识别不到更新,当然这点在IK分词器中不存在,因为IK分词器的热更新默认是一分钟获取一次。
3、如果我在一分钟内改了文件,发现改错了,又改回来了,那么这个时间虽然修改时间变了,但是因为内容没变,我是不希望更新它的。
综上所述,我们需要一个ETag来帮助我们判断是否更新了文本内容,同时ETag还需要根据文本内容来产生。
1.3 实操
1、创建分词库和停止词的文本文件
extend.dic
伍55
伍Benjamin
贵州贵阳
爽爽的贵阳
无敌尊贵氪金版iphone
stop.dic
那个
那些
的
这些
这个
是
不是
2、编写API
配置文件
ik:
hot-word-path: "/Library/project/study/java/elasticsearch/elasticsearch-ik-hot-update/src/main/resources/extend.dic"
stop-word-path: "/Library/project/study/java/elasticsearch/elasticsearch-ik-hot-update/src/main/resources/stop.dic"
api代码
@RestController
@RequestMapping("hot")
@Slf4j
public class HotUpdateController {
@Value("${ik.hot-word-path}")
private String hotWordFilePath;
@Value("${ik.stop-word-path}")
private String stopWordFilePath;
/**
* 获取分词、停止词
* type 0分词,1停止词
* @param response
* @param type
* @throws IOException
*/
@RequestMapping("updateHotWord")
public void hotWord(HttpServletResponse response,@RequestParam Integer type) throws IOException {
if(type == null || (type != 0 && type != 1)){
return;
}
File file = new File(type == 1 ? stopWordFilePath : hotWordFilePath);
FileInputStream fis = null;
try {
fis = new FileInputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
log.error("hot word load failed: ",e.getMessage());
}
// TODO 优化读取文本内容的方法:不受int长度的显示
byte[] buffer = new byte[(int)file.length()];
long lastModified = file.lastModified();
String etag = '"' + Long.toHexString(lastModified) + '-' + Long.toHexString(buffer.length) + '"';
response.setHeader("Last-Modified",String.valueOf(lastModified));
response.setHeader("ETag",etag);
response.setContentType("text/plain;charset=utf-8");
int offset = 0;
if(fis != null){
try{
while (fis.read(buffer,offset,buffer.length-offset) != -1){}
}catch (IOException e){
e.printStackTrace();
log.error("hot word read failed: ",e.getMessage());
}finally {
fis.close();
}
}
OutputStream out = response.getOutputStream();
out.write(buffer);
out.flush();
}
}
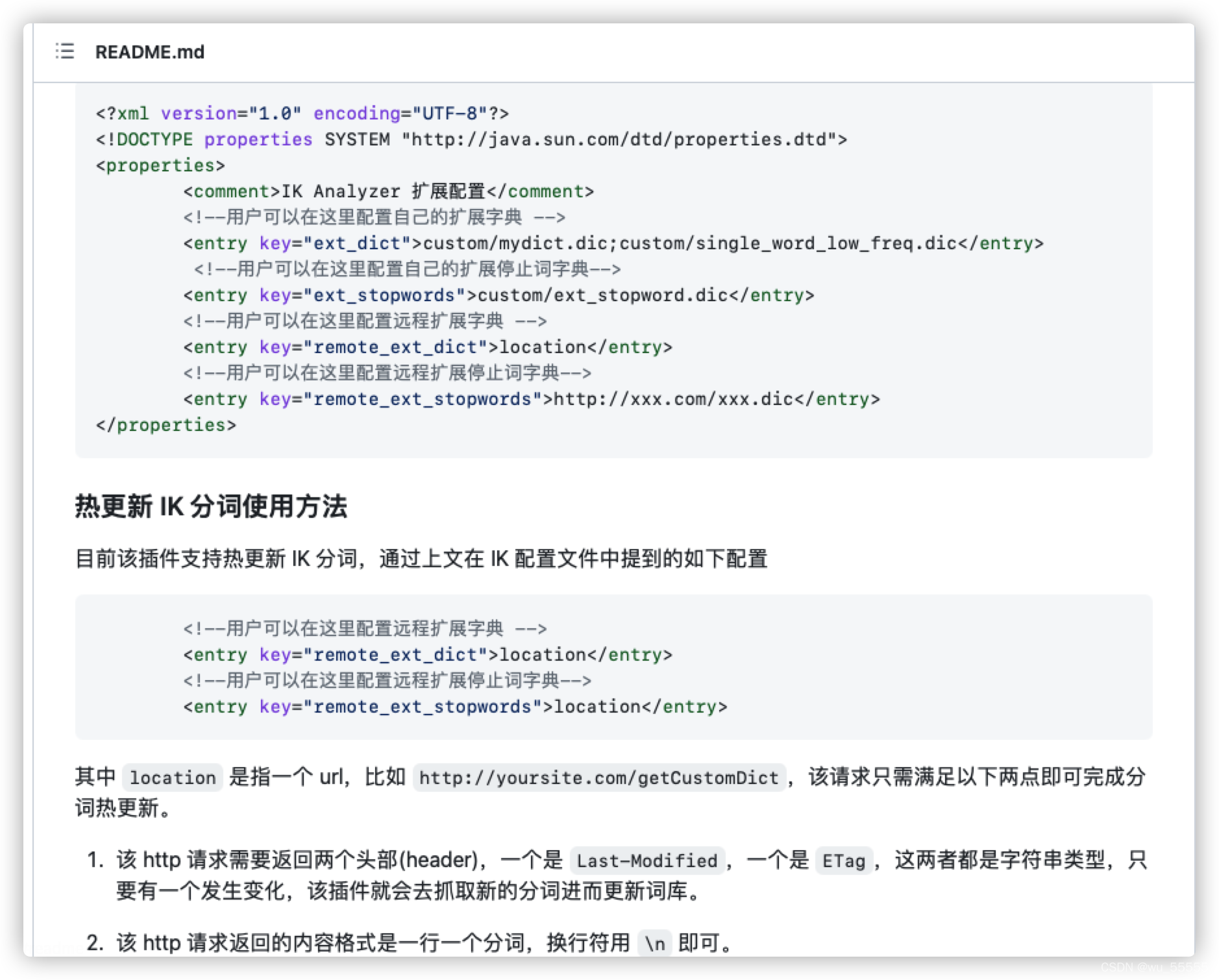
3、修改ik分词器配置文件IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/my_extend.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.101.109:8080/hot/updateHotWord?type=0</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://192.168.101.109:8080/hot/updateHotWord?type=1</entry>
</properties>
4、重启es
会发现启动时会显示读取的分词内容

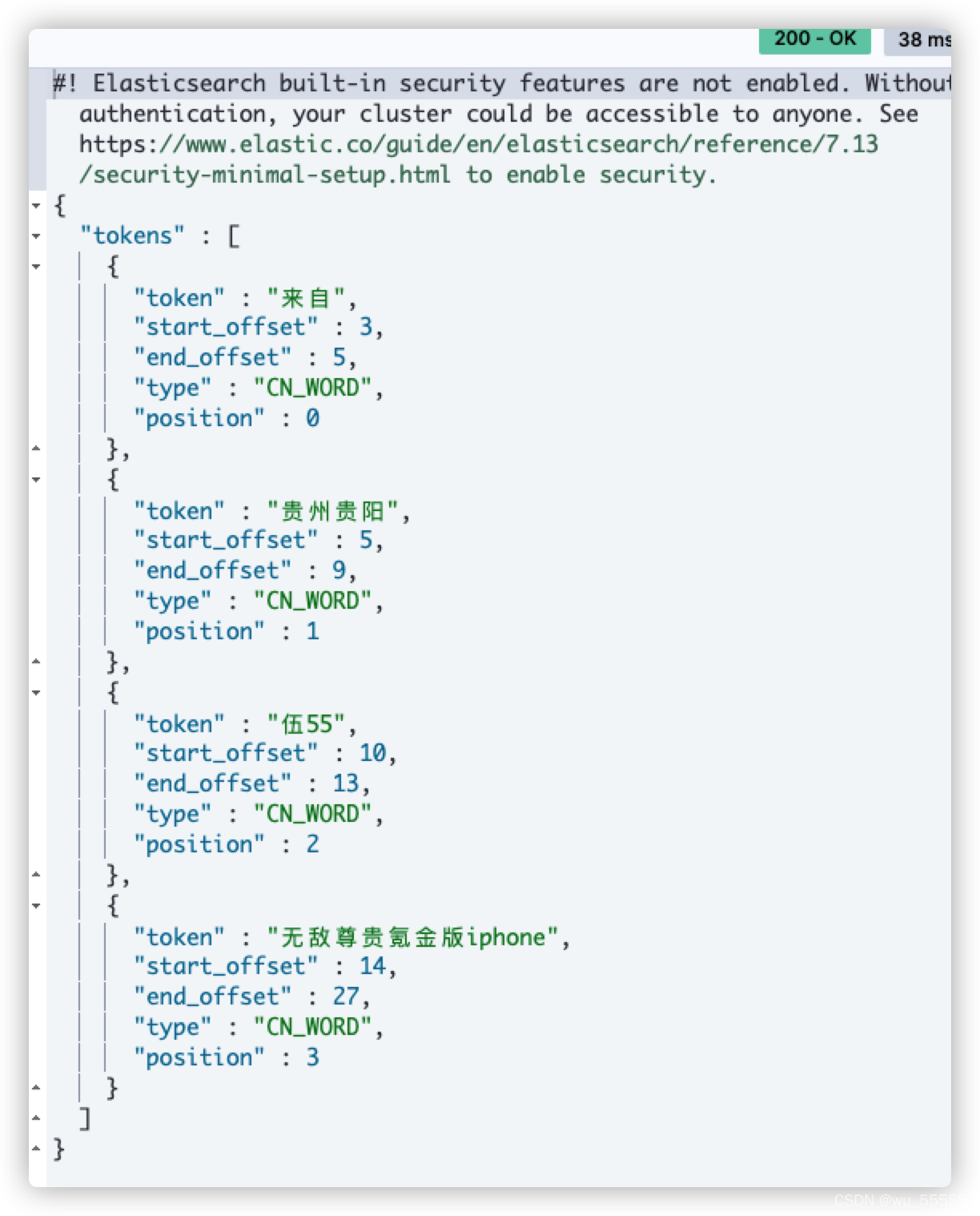
5、测试
GET _analyze
{
"analyzer": "ik_smart",
"text": ["这个是来自贵州贵阳的伍55的无敌尊贵氪金版iphone"]
}
结果
分词与分词库中设置的一致,停止词也被过滤了。测试通过
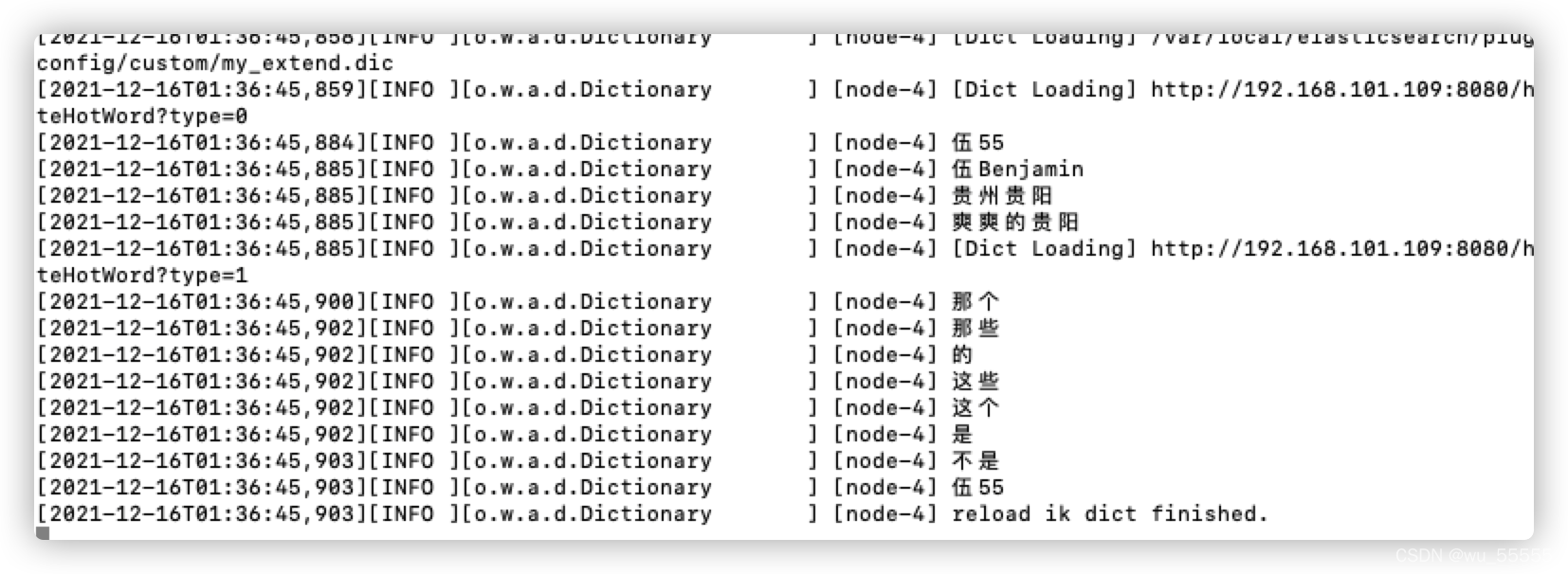
6、修改热词
extend.dic 中去掉了最后一条分词
伍55
伍Benjamin
贵州贵阳
爽爽的贵阳
stop.dic中新增了“伍55”停止词
那个
那些
的
这些
这个
是
不是
伍55
修改后日志也会输出读取到的文本内容
7、测试
GET _analyze
{
"analyzer": "ik_smart",
"text": ["这个是来自贵州贵阳的伍55的无敌尊贵氪金版iphone"]
}
结果:此次的结果就没有“无敌尊贵氪金版iphone”分词了,“伍55”也被过滤了,测试通过!

2. 基于API的方式的优缺点
优点:上手简单
缺点:
(1)词库的管理不方便,要直接操作磁盘文件,检索页很麻烦
(2)文件的读写没有专门的优化,性能不好
(3)多一次接口调用和网络传输
下一期讲解如何通过修改IK源码的方式来实现基于数据库的热更新
3. 参考博客
【1】https://stackoverflow.com/questions/4533/http-generating-etag-header
【2】https://q.shanyue.tech/base/http/112.html

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)