
机器学习(西瓜书)
这个机器不逃学!--需要不断学习不断学习不断学习~却怎么都学不会的机器学习
第一章 绪论
1.1 引言
1.2 基本术语
数据集、示例/样本、属性/特征、属性值/特征值、训练集、测试集
- 标记:示例结果信息。衍生出来的 标记空间=输出空间
- 属性空间/样本空间/输入空间:属性张成的空间(属性的可选值集合)
- 特征向量:一个示例/样本在向量空间里的映射,可直接指一个示例/样本
- 泛化能力:学得模型适用于新样本的能力
- 独立同分布:假设样本空间中全体样本服从一个未知“分布”,我们获得的每个样本都是独立地从这个分布上采样获得的。
1.3 假设空间
*:通配符
1.4 归纳偏好
- 归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好
- “奥卡姆剃刀”:若有多个假设与观察一致,则选最简单的那个
- “没有免费的午餐”定理:无论算法A多么聪明,算法B多么笨拙,他们的期望值竟然相同!
第二章 模型评估与选择
2.1 经验误差与过拟合
- 精度 =1 - 错误率,错误率 = 结果错误样本数 / 总样本数
- 训练误差/经验误差:学习器在训练集上的误差
- 泛化误差:学习器在新样本上的误差
- 过拟合:学习器把训练样本学得太好了,这时它很可能把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,导致泛化性能下降。比较难解决,且几乎无法避免,要尽量缓解或减小其风险,是机器学习面临的关键障碍。
- 欠拟合:对训练样本的一般性质尚未学好,通常是由于学习能力地下造成的,比较容易克服。
2.2 评估方法
产生训练集S和测试集T的方法:
2.2.1 留出法
- 注意事项:训练集/测试集 的划分要尽可能保持数据分布的一致性。例如在分类任务中至少要保持样本类别比例相似,注意训练集和测试集要同分布。
- 结果评估:单次使用留出法得到的估计结果往往不够稳定可靠,一般还需要采用若干次随机划分、重复进行实验评估后取平均值才能作为留出法的评估结果。
- 常见做法:将大约2/3~4/5的样本用于训练,剩余样本用于测试。
分层采样:保留类别比例来采样。例如,若训练集S占总样本70%,其中包含500个正例和500个反例,那么,测试集T占总样本30%,其中包含150个正例和150个反例。
2.2.2 交叉验证法
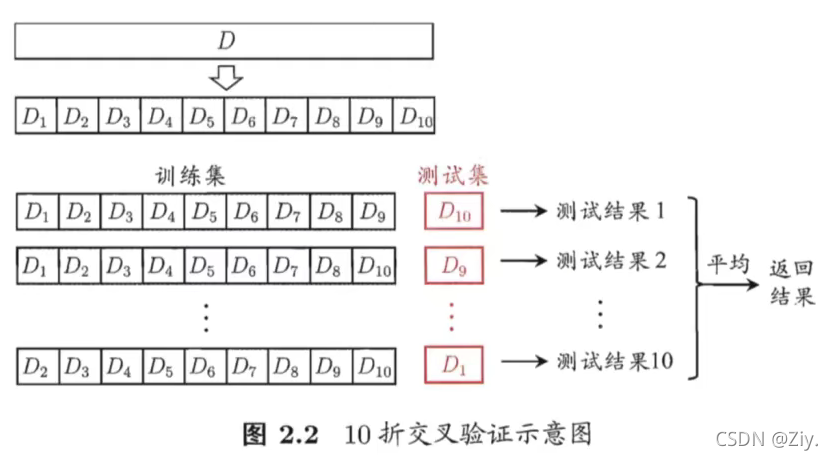
留一法:交叉验证法的特例,每个子集就是一个样本
缺点:当数据量较大时,对算力要求较高。
2.2.3 自助法
- 包外估计:实际评估的模型与期望评估模型都使用m个样本,最后仍有数据总量约1/3的、没在训练集中出现的样本用于测试
- 适用:数据集较小,难以有效划分训练/测试集时
- 好处:能从初始数据集中产生多个不同的训练集,对集成学习有很大的好处
- 缺点:自助法产生的数据集改变了初始数据集的分布,会引入估计偏差
2.2.4 调参与最终模型
- 验证集:模型评估与选择中用于评估测试的数据集
2.3 性能度量
- 性能度量:对模型泛化能力进行评估
- 回归任务最常用的性能度量是均方误差(其中的差是指预测值与真实值之间的差)

2.3.1 错误率与精度
- 错误率:分类错误的样本数占样本总数的比例
- 精度:分类正确的样本数占样本总数的比例
2.3.2 查准率、查全率与F1
- 在二分类问题中:
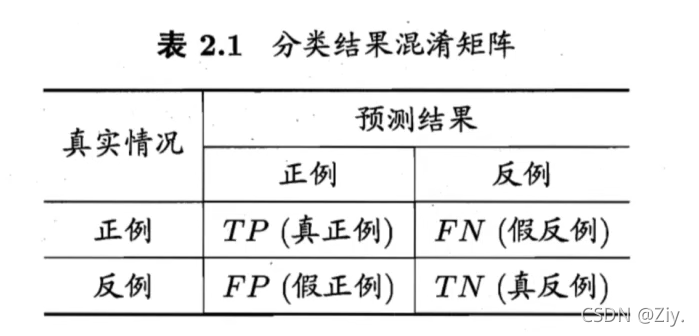
-
查准率(precision):预测结果为正例中有多少是真正例
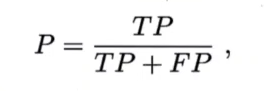
-
查全率(recall):正例中被查出来为正的比例
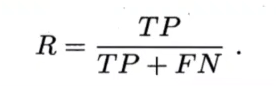
查准率和查全率是一对增长负相关的度量
- 查准率-查全率曲线,简称“P-R曲线”
- 最优阈值的确定
(1)使用平衡点Break-Even Point(BEP),即R=P时R与P的值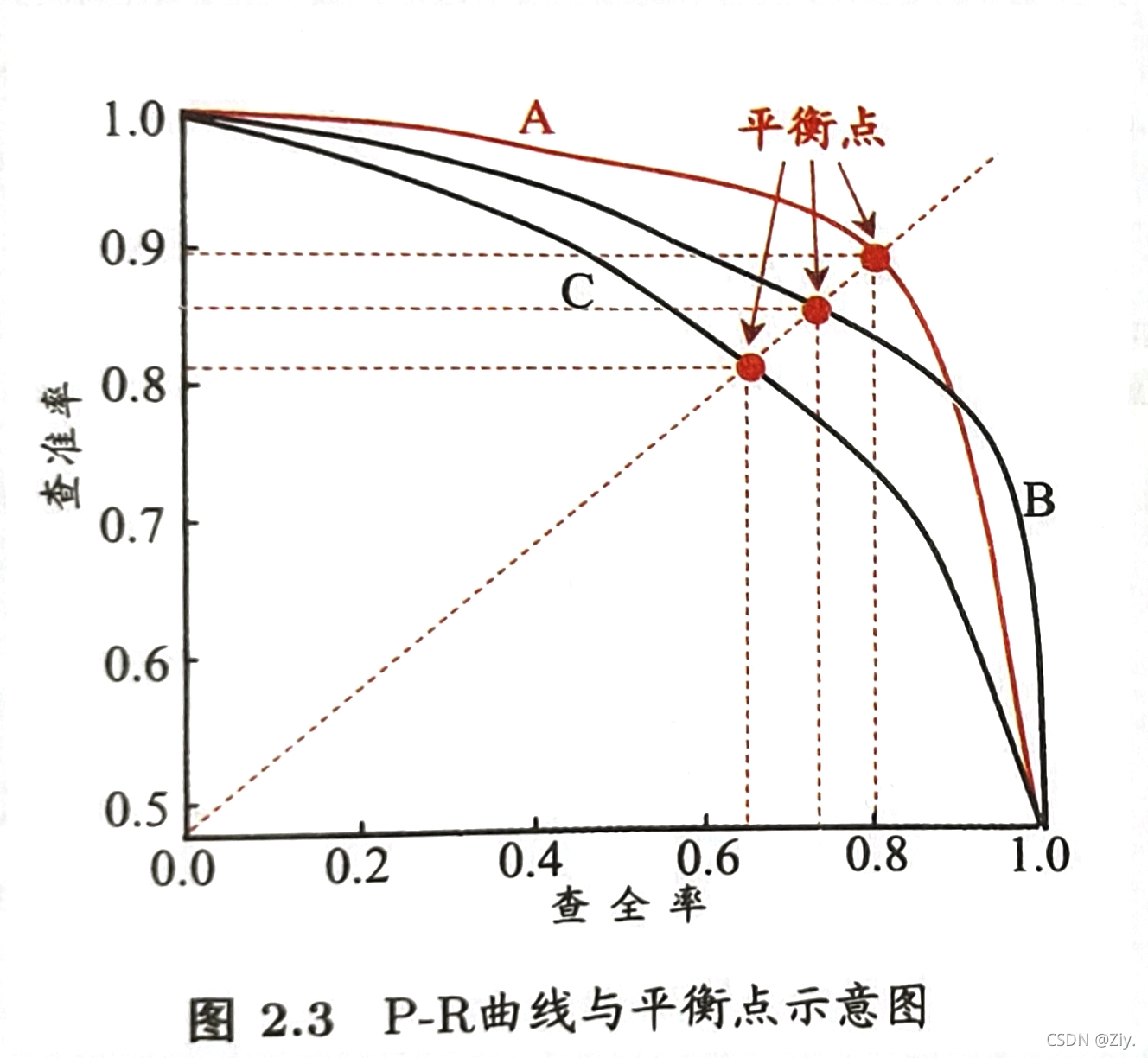
基于BEP的比较,可认为学习器A优于学习器B,学习器B优于学习器C
(2)使用F1度量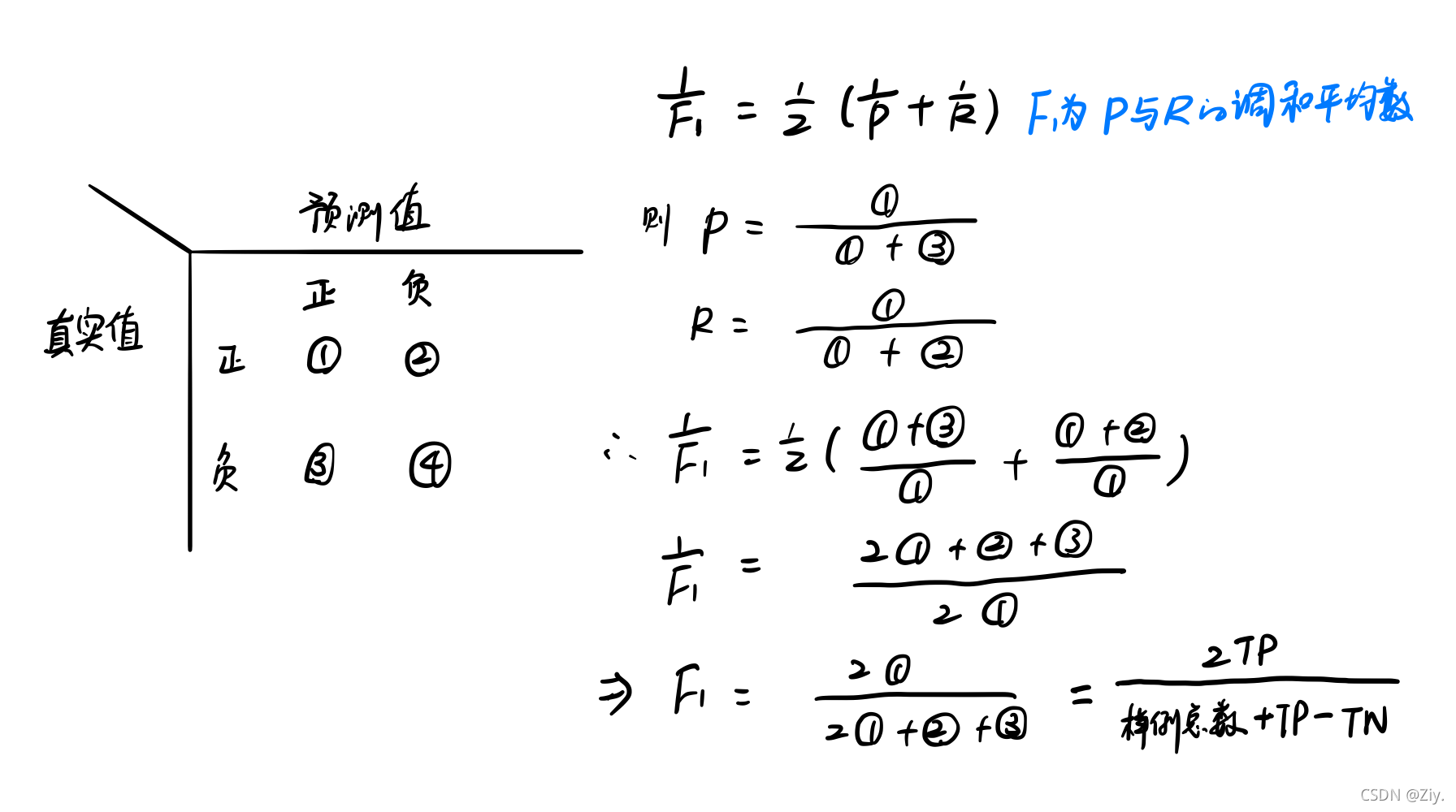
(3)FβF_{\beta}Fβ:F1度量的一般形式
n个二分类的多分类问题:
(4)先分别计算,再求平均值:宏查全率、宏查准率
(5)先平均再计算:微查全率、微查准率
2.3.3 ROC与AUC
- ROC曲线:TPR-FPR曲线,随着TPR增长,FPR曲线增长较缓慢的学习器性能较好
- 真正例率:TPR=TPTP+FNTPR ={TP \above{0.5pt} TP+FN}TPR=TP+FNTP
- 假正例率:FPR=FPTN+FPFPR={FP \above{0.5pt}TN+FP}FPR=TN+FPFP
- AUC:即为ROC曲线下的面积,通常用于评定ROC曲线交叉的两个学习器的性能的好坏
- 损失llossl_{loss}lloss:对应ROC曲线之上的面积,即 AUC=1−llossAUC = 1 - l_{loss}AUC=1−lloss
2.3.4 代价敏感错误率与代价曲线
- 非均等代价:不将错误简单地权衡为次数,而是赋予每种错误一个代价权重,最后最小化总体代价。
- 代价曲线:反映学习器的期望总体代价
2.4 比较检验
2.4.1 假设检验
先欠着,有点难
2.5 偏差与方差
- 偏差:预期结果与真实结果的偏离程度,刻画学习算法的拟合能力
- 方差:同样大小的训练集变动所导致的学习性能的变化,刻画数据扰动所造成的影响
- 噪声:在当前任务上任何学习算法所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
- 偏差-方差分解:解释学习算法泛化性能的一种重要工具
- 泛化误差可分解为偏差、方差和噪声之和
- “偏差-方差窘境”:说明偏差与方差的冲突
第三章 线性模型
3.1 基本形式
- 线性回归模型:f(x)=wTx+bf(x) = w^Tx+bf(x)=wTx+b(简写)
其中,x为特征值,而w为各特征值相对应的权重
3.2 线性回归
- 欧几里得距离:在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。

- 最小二乘法:基于均方误差最小化来进行模型求解的方法。
-
均方误差:(w∗,b∗)=arg min(w,b)∑i=1m(f(xi)−yi)2=arg min(w,b)∑i=1m(yi−wxi−b)2(w^*,b^*) = \argmin_{(w,b)}\displaystyle\sum_{i=1}^m(f(x_i)-y_i)^2=\argmin_{(w,b)}\displaystyle\sum_{i=1}^m(y_{i}-wx_i-b)^2(w∗,b∗)=(w,b)argmini=1∑m(f(xi)−yi)2=(w,b)argmini=1∑m(yi−wxi−b)2
-
而在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小
-
最小二乘“参数估计”:即求解w和b使得E(w,b)=∑i=1m(yi−wxi−b)2E_{(w,b)} = \displaystyle\sum_{i=1}^m(y_i-wx_i-b)^2E(w,b)=i=1∑m(yi−wxi−b)2最小,通过对E(w,b)E_{(w,b)}E(w,b)求导可得w和b的最优解
- 多元线性回归:数据集中涵盖多个属性(假设有d个),此时可求出多个w使得均方误差最小化,选择哪一个的最常见做法是引入正则化项。
- 形式:f(xi)=wTxi+bf(x_i) = w^Tx_i+bf(xi)=wTxi+b,使得f(xi)≃yif(x_i)\simeq y_if(xi)≃yi
- 对数线性回归:
- 形式:lny=wTx+b\ln y = w^Tx+blny=wTx+b
虽然在形式上仍是线性回归,但实质上已是在求取输入空间到输出空间的非线性函数映射,这里的对数函数起到了将线性回归模型的预测值于真实标记联系起来的作用。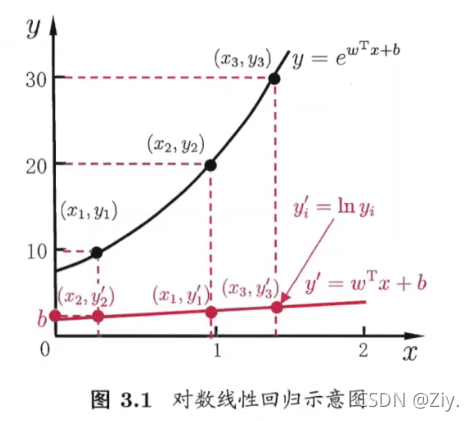
- 广义线性模型:
- 形式:y=g−1(wTx+b)y = g^{-1}(w^Tx+b)y=g−1(wTx+b),其中函数g(⋅)g(·)g(⋅)为单调可微函数,称为联系函数。
对数线性回归是广义线性模型在g(⋅)=ln(‘)g(·)=\ln(`)g(⋅)=ln(‘)时的特例。
3.3 对数几率回归(逻辑回归)
表达某种事件发生的可能性
- 原理:通过找一个单调可微函数将分类任务的真实标记yyy与线性回归模型的预测值联系起来,从而用回归的方法来做分类任务。其中对数几率函数正是可以将两者联系起来的一种“Sigmoid”函数,它将回归函数值zzz转化为接近0或1的yyy值
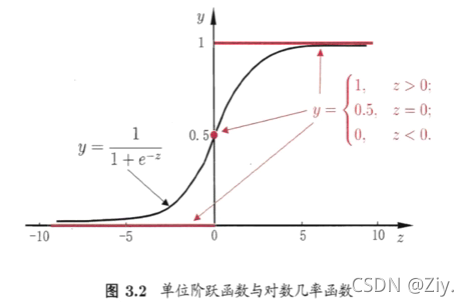
-
对数几率函数:y=11+e−z=11+e−(wTx+b)y = \dfrac{1}{1+e^{-z}} = \dfrac{1}{1+e^{-(w^Tx+b)}}y=1+e−z1=1+e−(wTx+b)1
上式变换后可得lny1−y=wTx+b\ln\dfrac{y}{1-y} = w^Tx+bln1−yy=wTx+b,其中,y1−y\dfrac{y}{1-y}1−yy为几率,而lny1−y\ln\dfrac{y}{1-y}ln1−yy为对数几率
-
该方法不仅可以预测“类别”,还可以得到近似概率。
- 最大似然估计:
- 根据最大可能性寻找最优解
- 每次猜对的可能性的乘积的最大值
例子: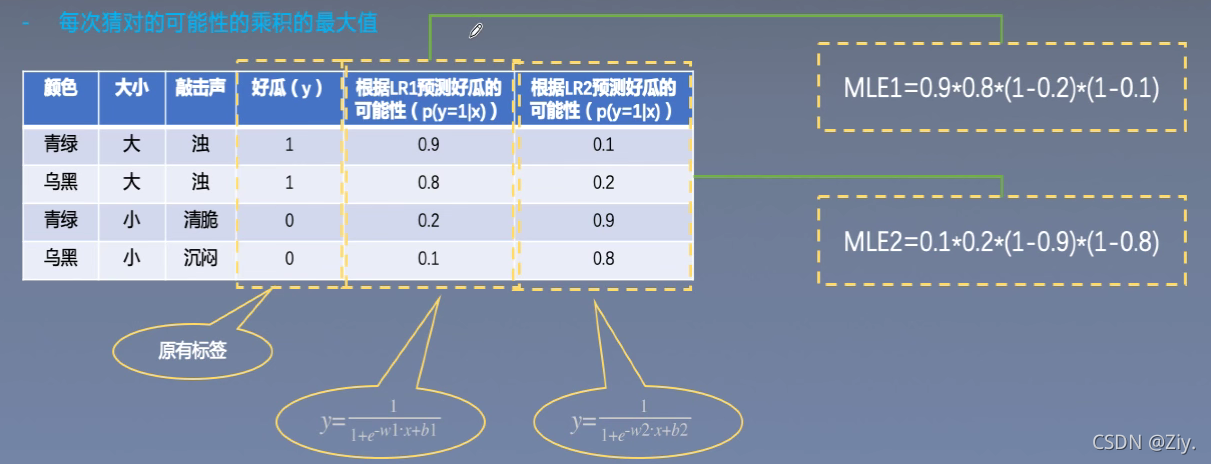
案例解释:有两个学习器LR1和LR2,其中MLE1为LR1学习器预测值趋于真实值的概率,MR2为LR2学习器预测值趋于真实值的概率,由上图的两种学习器表现结果及MLE1和MLE2的比较可知,LR1的效果比LR2好
参考资料:
拓展资料:
3.4 线性判别分析(LDA)
- 二分类
样本在坐标空间的对直线的投影点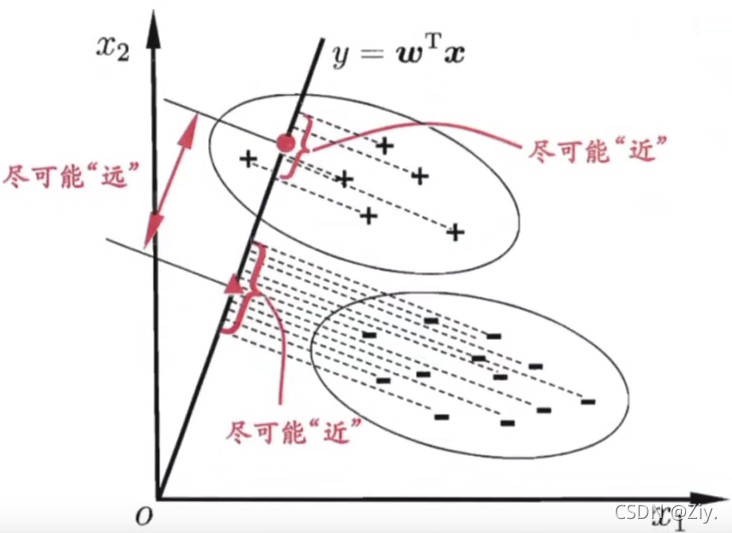
LDA可将样本投影到d维空间里(d小于数据原有属性数),通过投影来减小样本点的位数,且投影过程中使用了类别信息,因此LDA也常被视为一种经典的监督降维技术。
欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小。欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能大。同时考虑两者,得到LDA最大化目标为:
- 当两类数据同先验,满足高斯分布且协方差相等时,LDA可达最优分类
- 多分类:采用优化目标
3.5 多分类学习
“多分类”学习基本思路是“拆解法”,即将多分类任务拆为若干个二分类任务求解。
- 拆分策略
- “一对一”
- “一对其余”
- “多对多”
- 纠错输出码(ECOC):在多对多技术中,将编码思想引入类别拆分
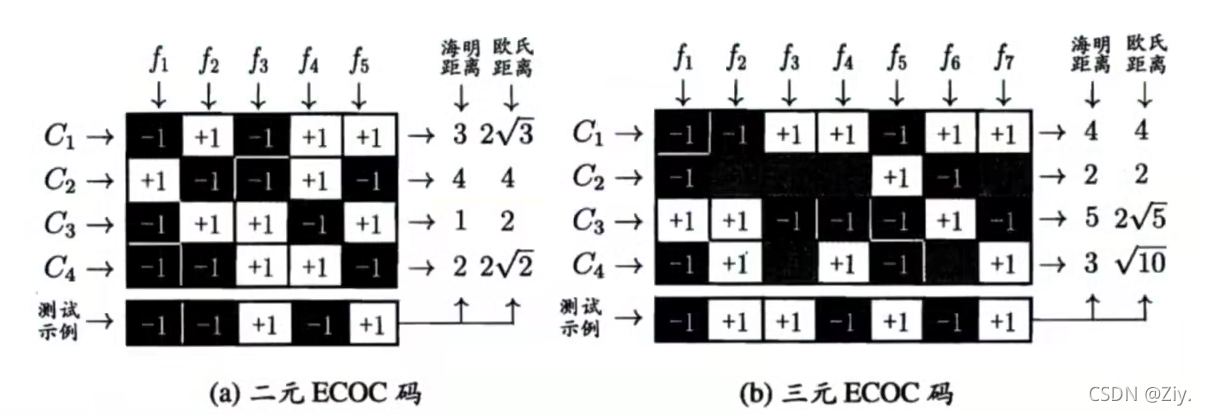
3.6 类别不平衡问题
- 类别不平衡:分类任务中不同类别的训练样例数目差别很大的情况
- 现行三种做法
假设条件:数据集中有928个反例,72个正例
- 欠采样:去除一些反例使得正反例数目接近。其代表性算法EasyEnsemble利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看不会丢失重要信息。
- 过采样:增加一些正例使得正反例数目接近。注意不能简单地对初始正例样本重复采样,否则会招致严重的过拟合
- 阈值移动:直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,在决策过程中使用“再缩放”策略。(“再缩放”是“代价敏感学习”的基础)
* 扩展阅读:《机器学习实战》第5章 Logistic回归
Logistic回归的定义,最优化算法
5.1 基于Logistic回归和Sigmoid函数的分类
-
Sigmoid函数
σ=11+e−z\sigma=\dfrac{1}{1+e^{-z}}σ=1+e−z1
x−>0x->0x−>0时,Sigmoid函数值为0.5;随着xxx增大,Sigmoid值将逼近于1;随着xxx的减小,Sigmoid值将逼近于0.若横坐标刻度足够大,Sigmoid函数看起来就像一个阶跃函数。
-
将大于0.5的数据分入1类,小于0.5的分为0类,则Logistic回归也可以被看成是一种概率估计。
5.2 基于最优化方法的最佳回归系数确定
将Sigmoid函数的输入记为z=w0x0+w1x1+...+wnxnz = w_0x_0+w_1x_1+...+w_nx_nz=w0x0+w1x1+...+wnxn,也可写成z=wTxz=w^Txz=wTx
5.2.1 梯度上升法
逐步移动,到达每个点后都会重新估计移动的方向,梯度算子总是指向函数值增长最快的方向,拟合效果较好,但其在每次更新回归系数时都需要遍历整个数据集,计算复杂度太高。
梯度上升算法用来求解函数的最大值,而梯度下降算法用来求解函数的最小值。
5.2.2 训练算法:使用梯度上升找到最佳参数(即拟合出Logistic回归模型的最佳参数)
5.2.3 分析数据:画出决策边界(即Logistic回归最佳拟合直线的函数)
第四章 决策树
4.1 基本流程
- 一般来说,一颗决策树包含一个根结点、若干内部结点和若干叶结点。叶结点对应决策结果,根结点包含样本全集。
- 决策树学习的基本流程遵循“分而治之”的策略,其生成为递归生成树的过程。
4.2 划分选择
决策树分支结点所包含的样本尽可能属于同一类别
4.2.1 信息增益( ID3ID3ID3 决策树学习算法)
- 一些概念
- 熵:一种事物的不确定性。比如说去买瓜,但是不知道该挑哪一个,这种不确定就叫熵
- 信息:用于消除不确定性,调整概率,排除干扰,最后确定情况。
- 噪音:对减小不确定性无用的信息。
- 数据:噪音+信息
-
熵的量化:用抛硬币的情景来解释,相当于猜一次抛硬币的不确定性,记为bit。抛硬币的次数于结果不确定性呈指数关系,抛一次,相当于熵为1bit,不确定性为2;抛三次相当于熵为3bit,不确定性为8。可推出求熵n(单位为bit)的公式为:
n=log2mn = \log_2mn=log2m,其中m为不确定性。 -
信息熵:度量样本集合纯度的常用指标,其定义为
Ent(D)=∑k=1∣y∣pklog2pkEnt(D) = \displaystyle\sum_{k = 1}^{|y|}p_k\log_2p_kEnt(D)=k=1∑∣y∣pklog2pk,
其中DDD为样本集合,pkp_kpk为DDD中第kkk类样本所占比例。Ent(D)Ent(D)Ent(D)的值越小,DDD的纯度越高。
- 信息增益:利用属性a来进行划分D所获得的“纯度提升”。信息增益越大,纯度提升越大。因此,我们可用信息增益来进行决策树的划分属性选择。(著名的 ID3ID3ID3 决策树学习算法就是以信息增益为准则来选择划分属性)。公式为:
Gain(D,a)=Ent(D)−∑v=1V∣Dv∣∣D∣Ent(Dv)Gain(D,a) = Ent(D) - \displaystyle\sum_{v=1}^{V}\dfrac{|D^v|}{|D|}Ent(D^v)Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
其中假定离散属性aaa有VVV个可能的取值{a1,a2,...,aV}\{a^1 ,a^2,...,a^V\}{a1,a2,...,aV},若使用aaa属性来对样本集DDD进行划分,则会产生VVV个分支结点,其中第vvv个分支结点包含了DDD中所有在属性aaa上取值为ava^vav的样本,记为DvD^vDv。Ent(Dv)Ent(D^v)Ent(Dv)为DvD^vDv的信息熵。
计算示例:P77P_{77}P77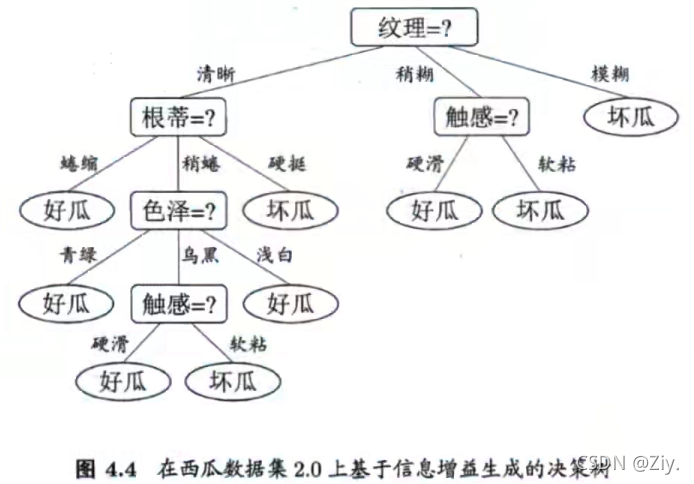
4.2.2 增益率(C4.5C4.5C4.5决策树算法)
C4.5C4.5C4.5决策树算法使用“增益率”来选择最优化分属性
-
信息增益对可取值数目较多的属性有所偏好。而增益率对可取值数目较少的属性有所偏好,公式入下:
Gain_ratio(D,a)=Gain(D,a)IV(a)Gain\_ratio(D,a) = \dfrac{Gain(D,a)}{IV(a)}Gain_ratio(D,a)=IV(a)Gain(D,a),其中IV(a)=−∑v=1V∣Dv∣∣D∣log2∣Dv∣∣D∣IV(a) = -\displaystyle\sum_{v = 1}^{V}\dfrac{|D^v|}{|D|}\log_2\dfrac{|D^v|}{|D|}IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣ -
应用:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
4.2.3 基尼指数(决策树CART训练算法)
Gini(D)Gini(D)Gini(D):反映从数据集DDD中随机抽取两个样本,其类别标记不一致的概率。Gini(D)Gini(D)Gini(D)越小,则数据集DDD的纯度越高。所以在候选属性集合时,要选择是的划分后基尼指数最小的属性作为最优化分属性。
- 分类树:基尼指数最小准则
- 回归树:平方误差最小准则,用于解决回归问题,用阈值来划分左右子树
4.3 剪枝处理
决策树学习中,应对“过拟合”的方法
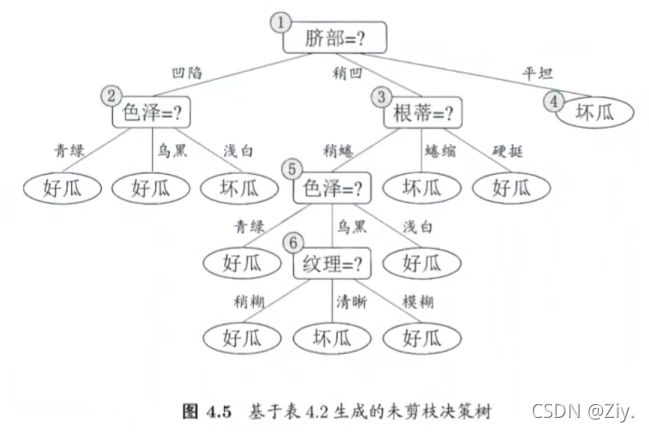
4.3.1 预剪枝(自上而下)
基于“贪心”算法来生成决策树,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升(包括泛化性能不变),则停止划分并将当前结点标记为叶结点。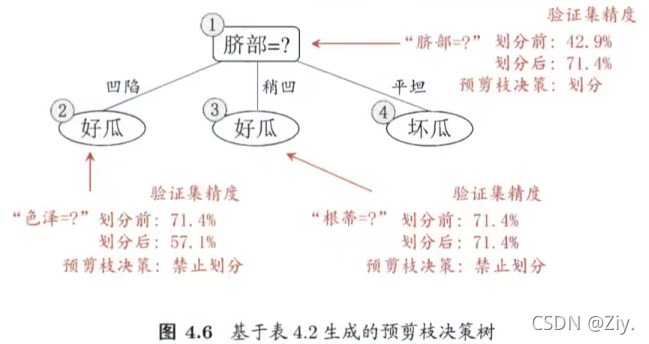
4.3.2 后剪枝(自下而上)
先从训练集生成一颗完整的决策树,之后“后序遍历”考察决策树中的划分结点(非叶结点),若剪枝后能够提高决策树泛化性能则剪枝,否则将它们保留。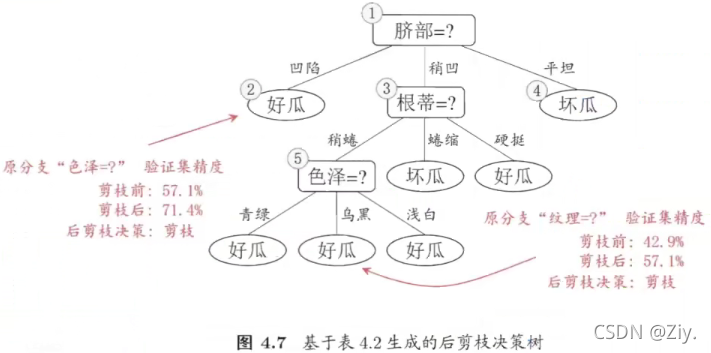
- 后剪枝通常比预剪枝得出的决策树保留更多的分支,一般情形下,后剪枝决策树“欠拟合”风险很小 ,泛化性能往往优于预剪枝决策树。
- 后剪枝要在生成决策树后对所有非叶结点逐一考察,因此其训练时间开销比预剪枝和未剪枝决策树都要大得多。
4.4 连续与缺失值
4.4.1 连续值处理
- 二分法:C4.5C4.5C4.5决策树算法采用的机制,使得信息增益最大的阈值
Ta={ai+ai+12∣1⩽i⩽n−1}T_a = \{\dfrac{a^i+a^{i+1}}{2}|1\leqslant{i}\leqslant{n-1}\}Ta={2ai+ai+1∣1⩽i⩽n−1} - 若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。
4.4.2 缺失值处理
- 离散值
- 众数填充
- 相关性最高的列填充
- 连续值
- 中位数
- 相关性最高的列做线性回归进行估计
4.5 多变量决策树
不只是对单个属性进行测试,而是对属性间的线性组合进行测试。
4.6 阅读材料
- ID3
- C4.5
- CART
- C4.5Rule
- OC1:贪心寻找每个属性的最优权值
- 线性分类器的最小二乘法
- 感知机树
- ID4
- ID5R
- ITI
第六章 支持向量机
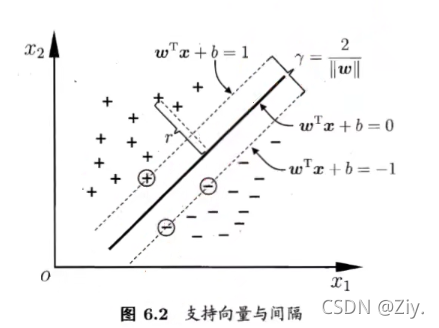
6.1 间隔与支持向量
- 在样本空间中,可用超平面划分类别,用线性方程来表述超平面可为:
wTx+b=0w^Tx+b = 0wTx+b=0
其中,x=(x1;x2;...;xd)x = (x_1;x_2;...;x_d)x=(x1;x2;...;xd)为样本空间维数;w=(w1;w2;...;wd)w = (w_1;w_2;...;w_d)w=(w1;w2;...;wd)为法向量,决定了超平面方向;b为位移项,决定超平面与原点距离。故超平面可被www和bbb确定,可将其记为(w,b)(w,b)(w,b).
- 支持向量:距离超平面最近的几个训练样本点,它们使得下式成立。
{wT+b⩾+1yi=+1(正例);wT+b⩽−1yi=−1(反例).\begin{dcases} w^T+b \geqslant +1& y_i = +1 \text{(正例);} \\ w^T+b \leqslant -1& y_i = -1 \text{(反例).} \end{dcases}{wT+b⩾+1wT+b⩽−1yi=+1(正例);yi=−1(反例).
而两个异类支持向量到超平面的距离之和为:
γ=2∣∣w∣∣\gamma = \dfrac{2}{||w||}γ=∣∣w∣∣2,被称为“间隔”
- 向量的内积指的是两个向量相乘,之后得到单个标量或者数值
- 支持向量的数目存在一个最优值,如果支持向量太少,就可能会得到一个很差的决策边界;如果支持向量太多,也就相当于每次都利用整个数据集进行分类,这种分类方法成为k近邻。
KNN需要保留所有的训练样本,而对于向量机,其需要保留的样本少了很多。
- 问题:找到最大间隔的划分超平面(鲁棒性最好,不易受样本波动干扰)。这样可得到支持向量机的基本型:
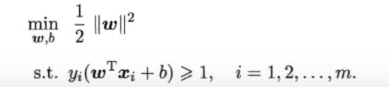
6.2 对偶问题
- 拉格朗日乘子法:极值点目标与约束相切
例:求曲线离原点最近的距离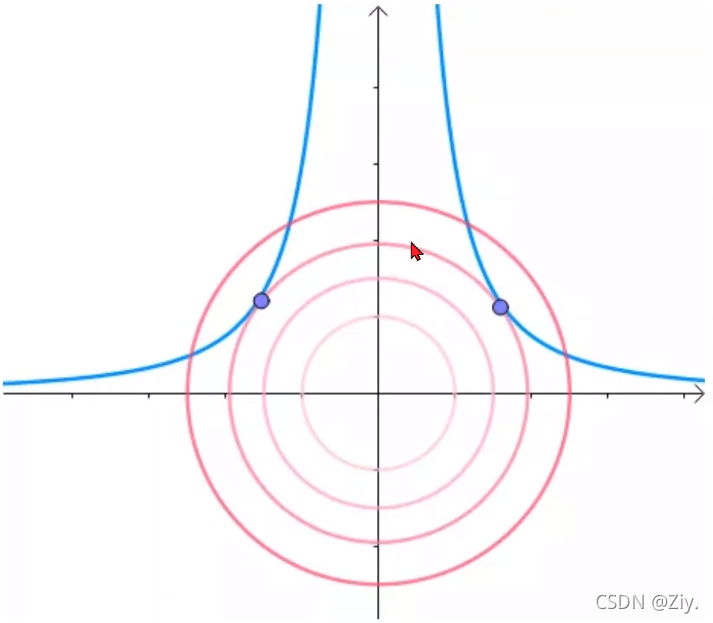 在极值点,曲线与圆相切:
在极值点,曲线与圆相切:
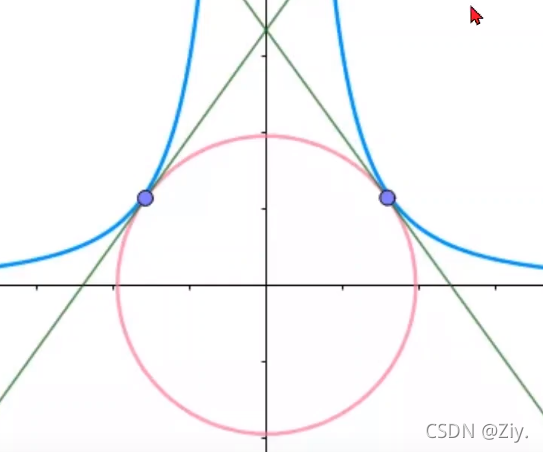
- 梯度与等高线的切线垂直
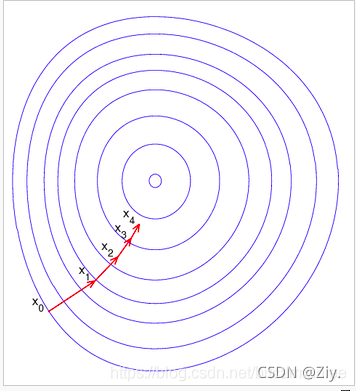

- 对偶问题思路:
- 引入拉格朗日函数
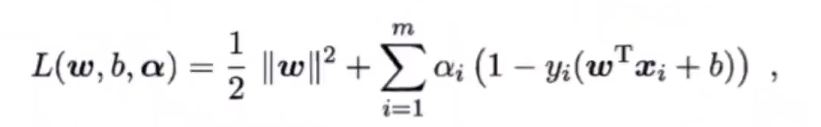
- KKT条件:
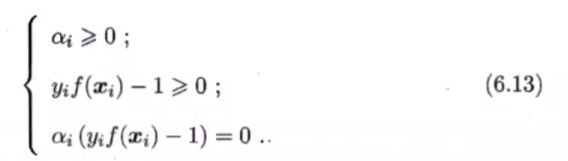
- 求导消元后得到变换结果
- SMO算法(序列最小优化):每次循环中选择两个alpha进行优化处理,使选取的两变量所对应样本之间的间隔最大。一旦找到一对合适的alpha,那么就增大其中一个同时减小另一个。
6.3 核函数
SVM本质上是二分类机。当样本并非线性可分时,需要将低维数据映射到高维,从而寻找一个平面(高维的对应超平面)能够正确划分两类样本。在高维中解决线性问题,等价于在低维中解决非线性问题。
- 径向基核函数(机器学习6.5.2)
- 常用核函数(西瓜书P128P_{128}P128)
6.4 软间隔与正则化
- 硬间隔:严格划分样本,不允许出错。(结果划分太严格可能是因为“过拟合”)
- 软间隔:允许向量机在一些样本上出错。但是在最大化间隔的同时,不满足约束的样本要尽可能少。最终模型只与支持向量有关。
软间隔与硬间隔唯一的差别就在于对偶变量的约束不同。
- l0/1l_{0/1}l0/1损失函数:数学性质不太好
- 替代损失函数:替代l0/1l_{0/1}l0/1损失函数,他们通常是凸的连续函数且是l0/1l_{0/1}l0/1的上界。
- hinge函数:可仍保持稀疏性
- 指数损失
- 对率损失
- 松弛变量:表征某一特定样本不满足约束条件的程度。
- 经验风险:描述模型与训练数据的契合程度。
- 正则化问题:降低最小化训练误差的过拟合风险。
6.5 支持向量回归
定义一个间隔带,在间隔带内假定损失全为0(即间隔带内被认为是预测正确的),间隔带之外再去计算损失值
- 定义的ϵ−不敏感损失函数\epsilon-不敏感损失函数ϵ−不敏感损失函数:
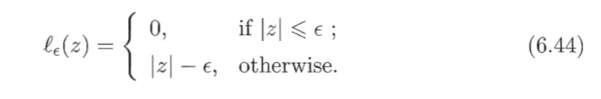
6.6 核方法
基于核函数的学习方法,统称为“核方法”
- 核线性判别分析
第七章 贝叶斯分类器
7.1 贝叶斯决策论
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)