
云计算学习笔记7——分布式存储及计算
Hadoop生态系统2005年,雅虎工程师,分布式计算系统Hadoop,后开源。采用MapReduce分布式计算框架,并根据GFS开发了HDFS分布式文件系统。核心组件:HDFSMapReduce1. 分布式文件系统——GFS1.1 GFS超大规模分布式文件系统,即以文件系统的方式来组织海量数据。代表工作:Goole的文件系统——GFSGFS提供了海量非结构化信息的存储平台,提供数据的冗余备份,成
Hadoop生态系统
2005年,雅虎工程师,分布式计算系统Hadoop,后开源。采用MapReduce分布式计算框架,并根据GFS开发了HDFS分布式文件系统。
核心组件:
- HDFS
- MapReduce
1. 分布式文件系统——GFS
1.1 GFS
超大规模分布式文件系统,即以文件系统的方式来组织海量数据。
代表工作:Goole的文件系统——GFS
- GFS提供了海量非结构化信息的存储平台,提供数据的冗余备份,成千台服务器的自动负载均衡以及失效服务器检测等各种完备的分布式存储功能。
1.2 GFS设计原则
- 大量商业PC来构建存储及存储集群。部件错误不再被当作异常,而是将其作为常见的情况加以处理。
- 针对大文件的读写操作进行了优化。小文件不作为重点。
- 系统中存在大量的“追加写”操作。很少“随机写”。
- 大多是“顺序读”,少量“随机读”。
- 往往一次读较大量数据,而非不断定位到某个位置读少量数据。
1.3 GFS整体架构
主要3个部分组成:
- 唯一的主控服务器(Master):负责整体系统的管理工作;
- 众多的Chunk服务器:负责实际的数据存储并响应客户端的读/写请求;
- GFS客户端:用户操作。
GFS文件存储:
- 由目录和存放在目录下的文件构成树形结构,这个树形结构被称为GFS命名空间。
- 实际存储时,GFS会将不同大小的文件切割成固定大小的数据块,每一块作为一个Chunk,通常大小为64MB。
- 每个文件由若干个固定大小的Chunk构成。
- 在Chunk服务器内部,回对Chunk进一步切割,切割为更小的数据块Block。
- GFS命名空间由众多的目录和GFS文件构成;
- 一个文件由众多固定大小的Chunk构成;
- 每个Chunk又由更小的粒度Block构成。
- Chunk是基本存储单元,Block是基本读取单元。

1.4 GFS主控服务器
主控服务器主要从事系统元数据存储管理以及整个分布式系统的管理。
如负载均衡,数据迁移,新节点及失效节点的检测等。
元数据包括以下三种:
- GFS命名空间和Chunk命名空间:主要用来对目录文件以及Chunk的增删改等信息进行记录。
- 从文件到其所属Chunk之间的映射关系
- Chunk在Chunk服务器上的存储信息:每个Chunk会被复制多个备份,并存储在不同的服务器上。
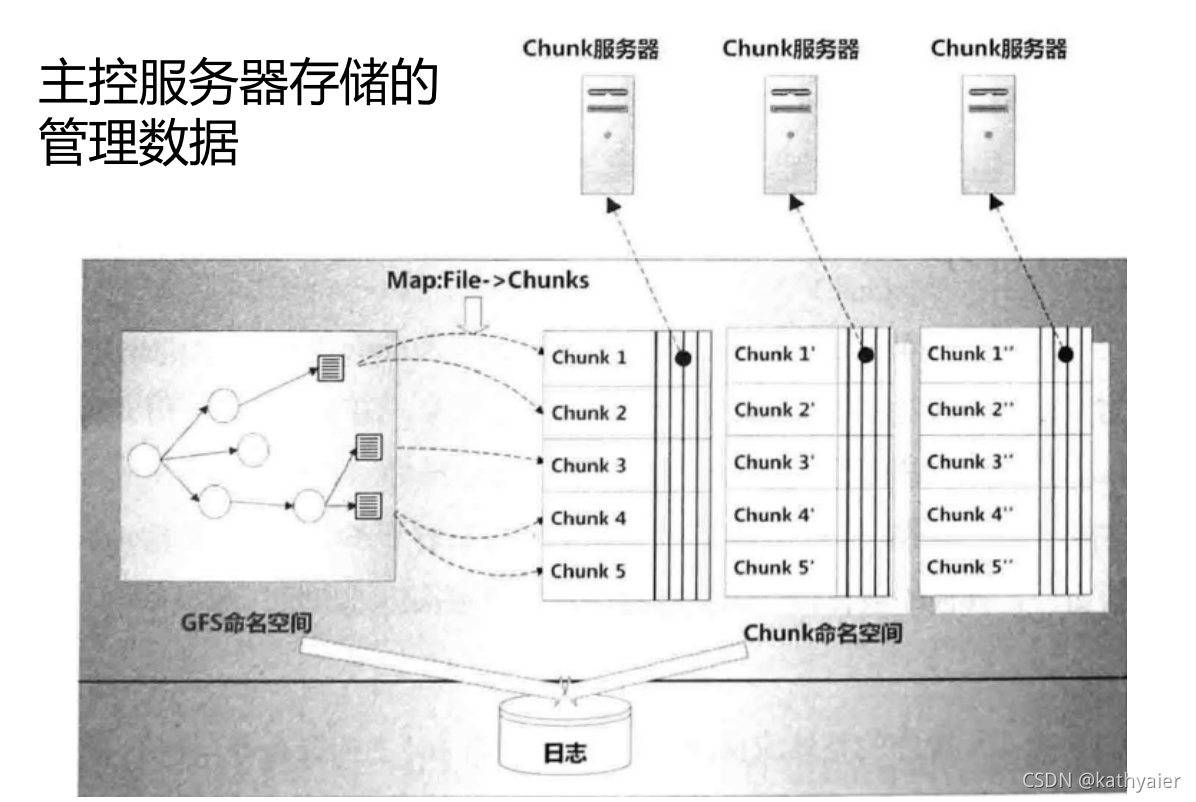
主控服务器安全性保障:
- GFS将前两类管理信息(命名空间,文件到Chunk的映射)记录在系统日志文件内,并分别存储在多台机器,避免信息丢失。
- 第三类管理信息(Chunk存储信息)通过主控服务器定期询问Chunk服务器来维护。
主控服务器所承担的管理工作:
- 不同Chunk服务器之间的负载均衡。
- 创建新Chunk。
- 垃圾回收。
数据备份及迁移时需要考虑:
- Chunk数据的可用性;Chunk数据不可用时,及时重新备份。
- 尽可能减少网络传输压力。
2. Hadoop分布式文件系统——HDFS
- 模仿GFS开发的开源系统。
- 适合存储大文件并为之提供高吞吐量的顺序读/写访问。
- 不太适合大量随机读写。
- 也不适合存储大量小文件。
2.1 HDFS整体架构
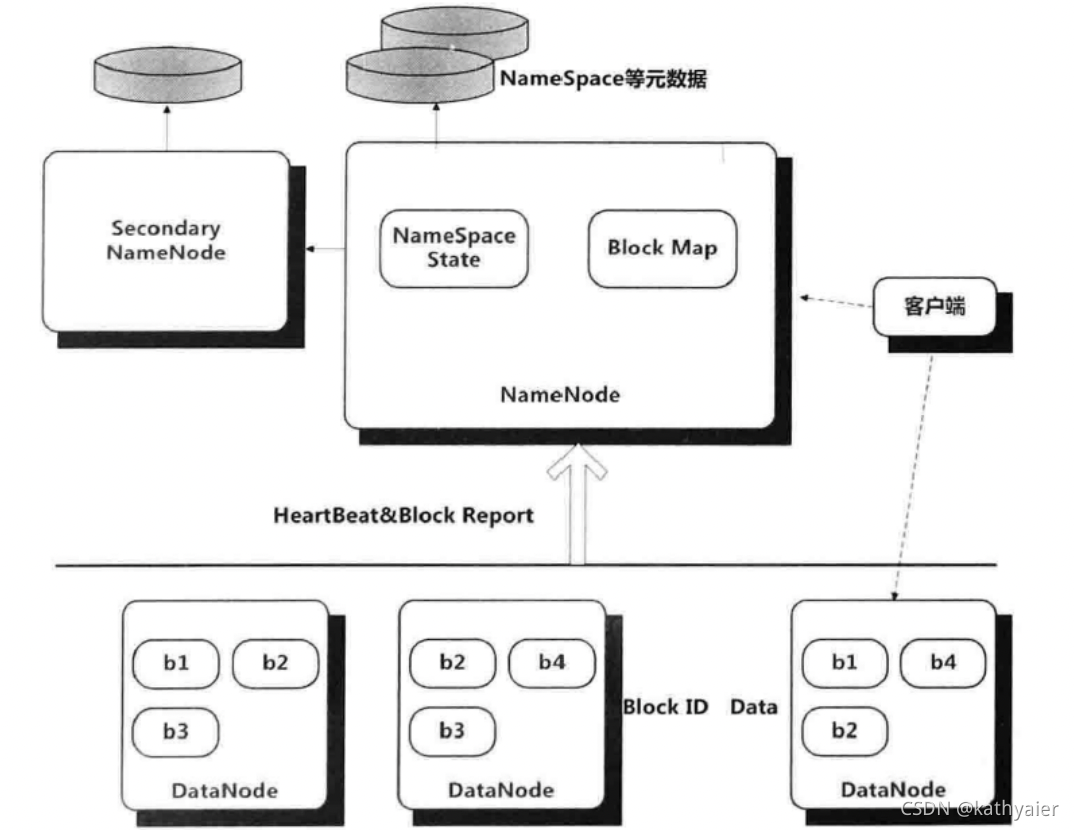
2.2 NameNode
NameNode管理整个分布式文件系统的元数据。
HDFS元数据包括:
- 文件目录树结构。
- 文件到数据块Block的映射关系。
- Block副本及其存储位置等各种管理数据。
管理数据保存在内存的同时,在磁盘保存两个元数据管理文件:
- fsimage
- editlog
NameNode还负责DataNode的状态监控,通过短时间间隔的心跳来传递管理信息和数据信息。
NameNode可以获知每个DataNode保存的Block信息、DataNode的健康状况,命令DataNode启动停止等。
2.3 Secondary NameNode
定期从NameNode拉取fsimage和editlog文件,并合并生成新的fsimage并传给NameNode。
减轻其工作压力。
本质上Secondary NN是个提供检查点功能服务的服务器。
2.4 DataNode
DataNode负责数据块的实际存储和读写工作。
HDFS语境下一般将数据块称为Block而非Chunk。默认大小64MB。
Block会以多备份的形式存储,默认备份个数为3。
2.5 客户端
客户端和NameNode联系获取所需读写文件的元数据,实际的读写都是和DataNode直接通信完成。
其读写流程与GFS读写流程基本一致,不同点在于不支持客户端对同一文件的并发写操作,同一时刻只能有一个客户端在文件末尾进行追加写操作。
3. 分布式计算框架——MapReduce
3.1 MapReduce
- 不仅仅是一种分布式计算模型,同时也是一整套构建在大规模普通商业PC之上的批处理计算框架。
- 该计算框架可以处理以PB计的数据,并提供了简易应用接口,将系统容错及任务调度等负责实现很好地封装在内,是的应用开发者只需关注应用逻辑。
3.2 计算模型
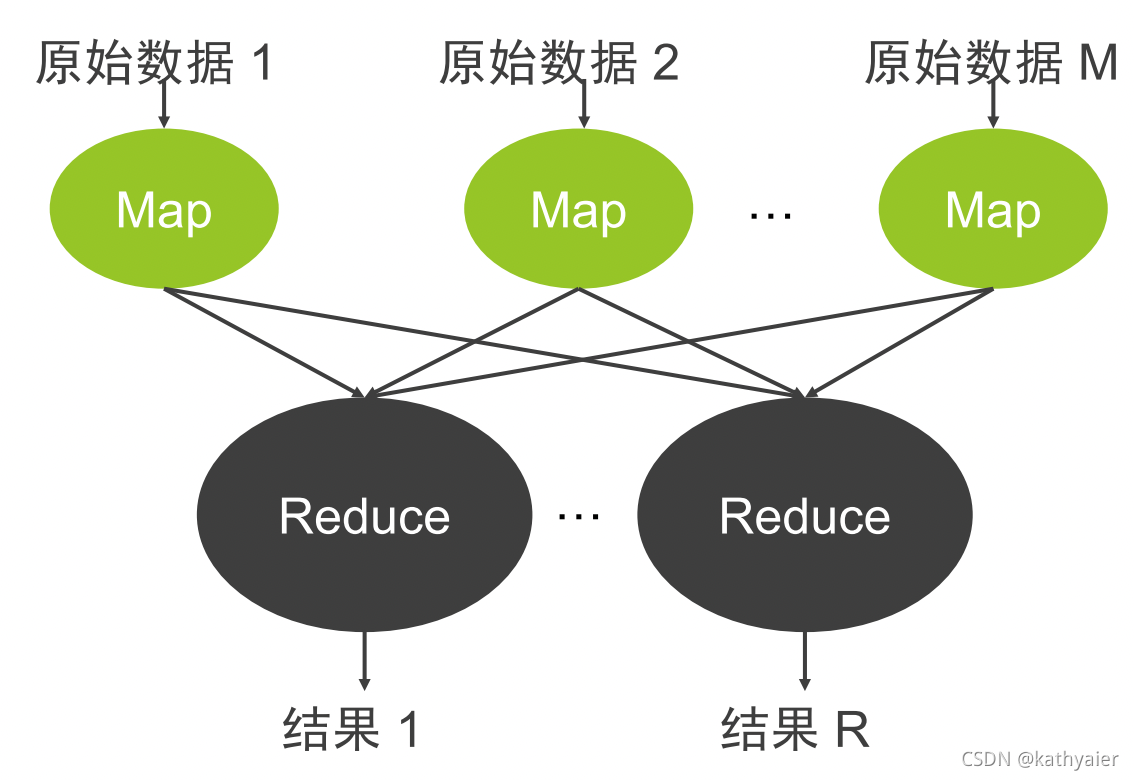
3.3 MapReduce执行过程

3.4 MapReduce示例——数值求和
单词统计:假设给定10亿个互联网网页内容,如何统计每个单词总出现的次数?

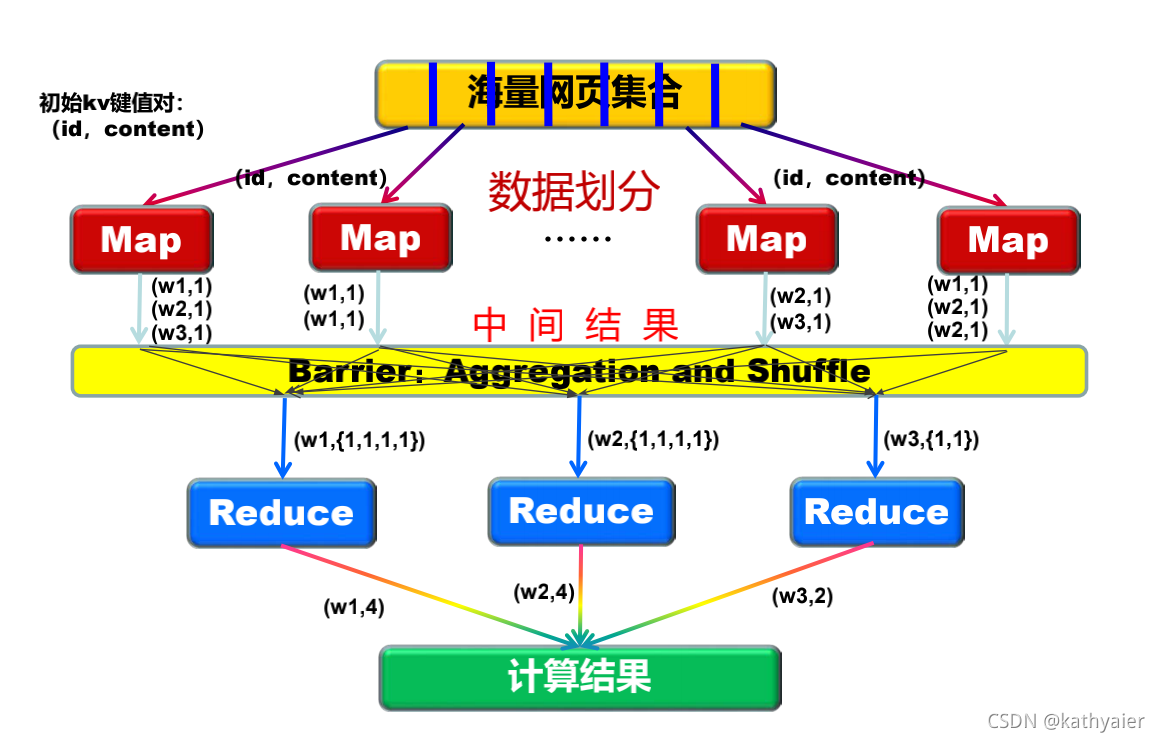
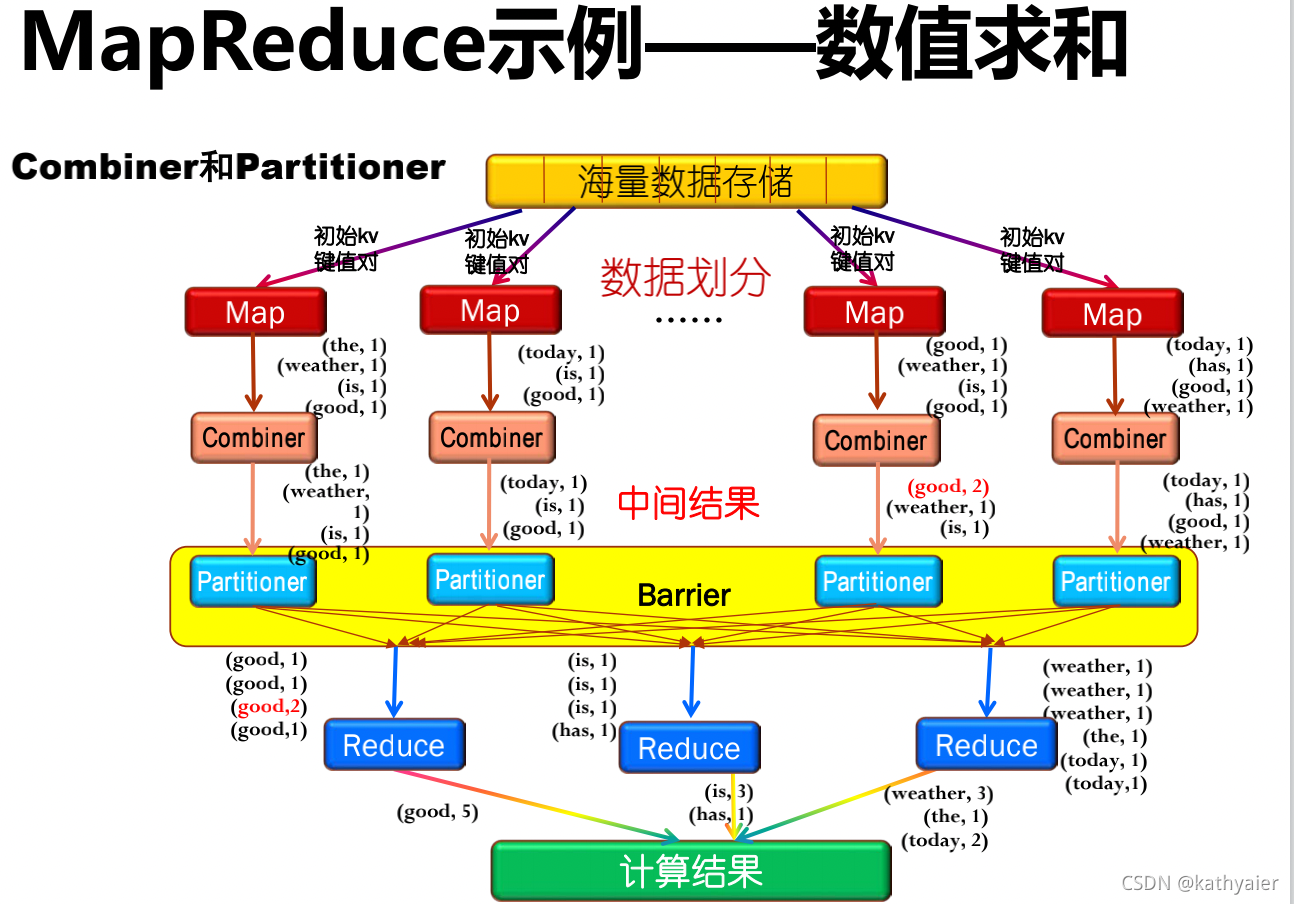 3.5 MapReduce中的重要概念
3.5 MapReduce中的重要概念
3.5.1 Combiner
- 可以看作局部的Reducer。
- 作用是合并相同的key对应的value。
- 优势是能够减少Map Task输出的数据量(磁盘IO)。
- 但是并不是所有的场景都可以使用Combiner。
3.5.2 Partitioner
- 决定了Map Task输出的每条数据交给哪个Reduce Task来处理。
有两个功能:
- (1)尽量将工作均匀地分配给不同的Reduce。
- (2)效率。跟配速度一定要非常快。
Partitioner的默认实现:hash(key)mode R,R代表Reduce Task的数目。
3.5.3 Shuffle
- 从Map输出到Reduce的整个过程可以广义地称为Shuffle。
- Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程。
- copy是从相应的Map节点中拉取需要的结果到Reduce中计算。
- 一般Reduce是一边copy一边sort。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)