《机器学习》周志华课后习题答案——第五章(1-7已完结)
第五章课后习题答案文章目录第五章课后习题答案一、试述将线性函数f(x) = wTx用作神经元激活函数的缺陷?二、试述使用图5.2(b)激活函数的神经元与对率回归的联系三、对于图5.7中的Vih,试推导出BP算法中的更新公式(5.13).一、试述将线性函数f(x) = wTx用作神经元激活函数的缺陷?使用线性函数作为激活函数时,因为在单元层和隐藏层,其单元值仍是输入值X的线性组合。若输出层也用线性函
第五章课后习题答案
文章目录
一、试述将线性函数f(x) = wTx用作神经元激活函数的缺陷?
使用线性函数作为激活函数时,因为在单元层和隐藏层,其单元值仍是输入值X的线性组合。
若输出层也用线性函数作为激活函数,达不到“激活”与“筛选”的目的,这样相当于整个的线性回归。

二、试述使用图5.2(b)激活函数的神经元与对率回归的联系
对率回归,是使用Sigmoid函数作为联系函数时的广义线性模型。
对于单位阶跃函数(如左图所示):
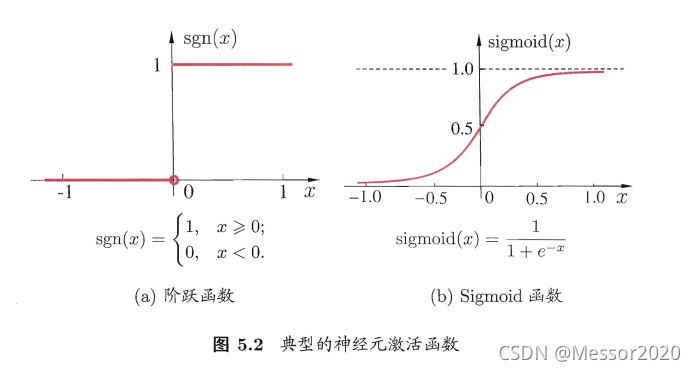
单位阶跃函数不连续,难以求导,所以用对数几率函数代替。
对于对率函数(如以上右图所示):

使用Sigmoid激活函数,每个神经元几乎和对率回归相同,只不过对率回归在 [sigmoid(x)>0.5] 时输出为1,而神经元直接输出 [sigmoid(x)] 。
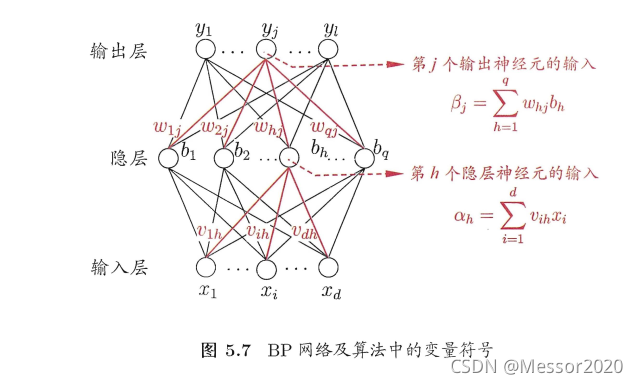
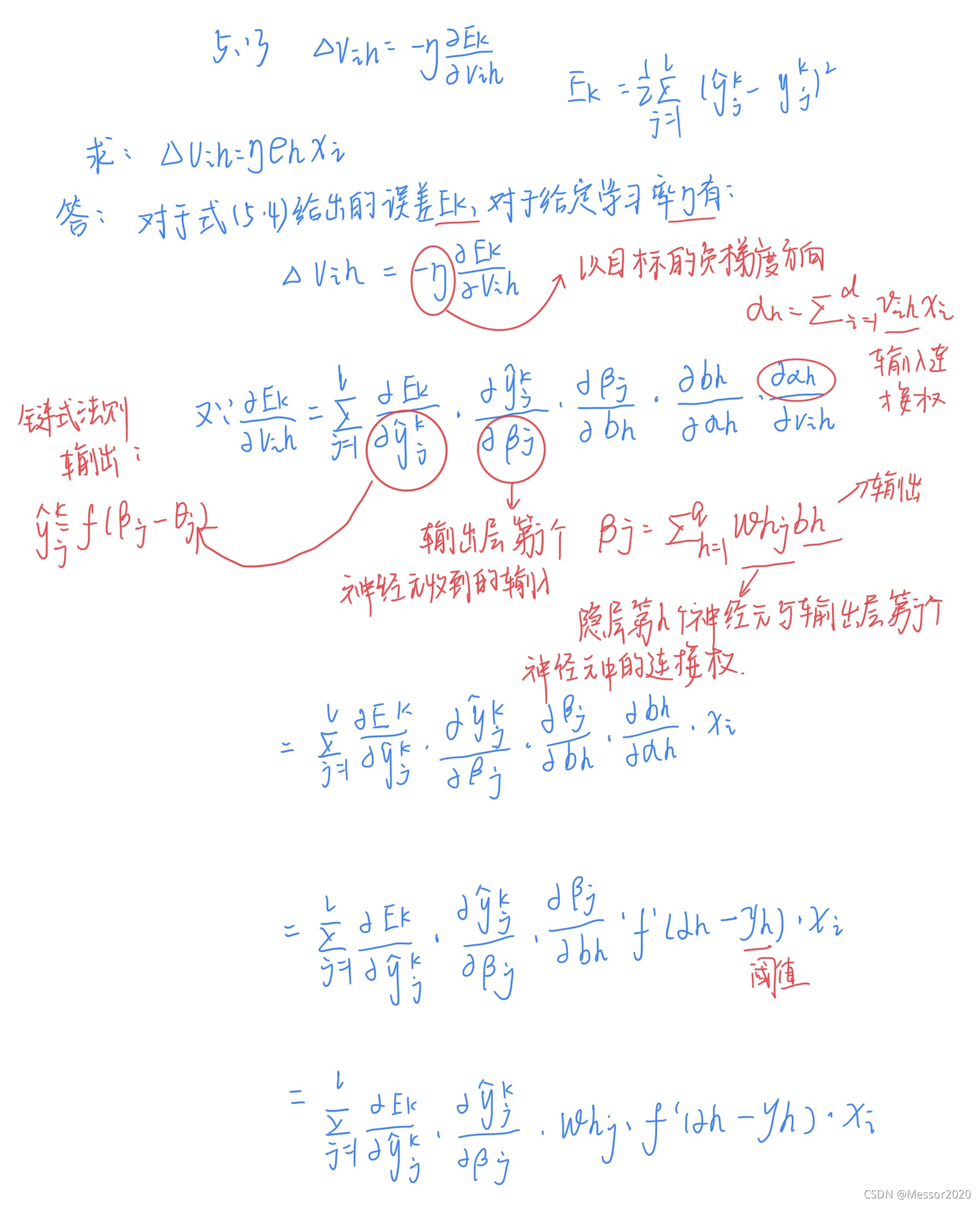
三、对于图5.7中的Vih,试推导出BP算法中的更新公式(5.13).

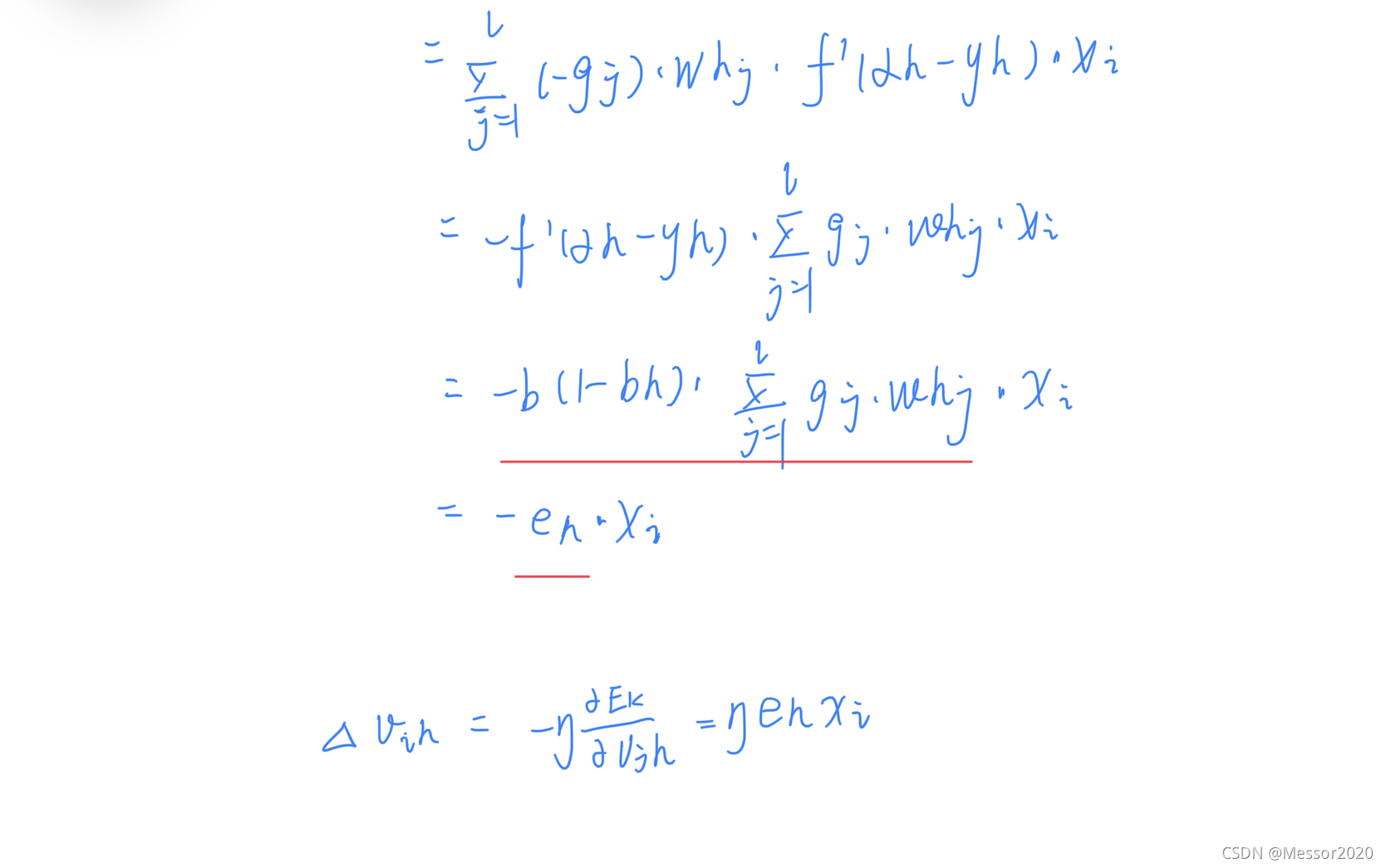
四、试述式(5.6)中学习率的取值对神经网络训练的影响.
学习率太低,每次下降得很慢,使得迭代次数增多,各种开销增大。
学习率太高,会在梯度下降最低点来回震荡,难以得到想要的结果。
五、试编程实现标准BP算法和累积BP算法,在西瓜数据集3.0上分别用这两个算法训练一一个 单隐层网络,并进行比较.
假设一个单隐层BP网络中,d个输入节点,隐层有q个神经元,输出层l个神经元。
BP算法要训练的参数有
输入层与隐层全连接的权值vijvij dq个
隐层神经元阀值θiθi q个
隐层与输出层全连接的权值wijwij q|个
输出层神经元阀值yiyi l个
BP算法每次迭代依次计算每一个样本, 最小化该样本输出值与真实值的差距,然后将修改过参数传给下一个样本,直到达到收敛条件。这样做参数更新频繁,也可能出现参数更改相互抵销的情况,于是便有了ABP。
ABP算法每次迭代会先算出所有样本的输出,然后最小化整个样本输出与真实值的最小平方和,修改参数后进行下一-次迭代。ABP参数更新次数比BP算法少的多,但是当累计误差降到-定程度时,进-步下降会非常缓慢。
迭代终止条件:这里设置的终止条件是相邻一百次迭代的累计误差的差值不超过0.001.
BP算法结果:
在西瓜数据集3上迭代1596次迭代,使得累计误差达到0.0013,此时对比表为



ABP:与BP算法最大的不同是参数在计算完全部样本才更改,由于ABP后期下降很慢,所以ABP的终止条件是经过1660次迭代。累计误差达到0.0015.





六、试设计一个BP改进算法,能通过动态调整学习率显著提升收敛速度.编程实现该算法,并选择两个UCI数据集与标准BP算法进行实验比较.
太难了,不会。
七、根据式(5.18)和(5.19),试构造一个能解决异或问题的单层RBF神经网络.

①构造数据集
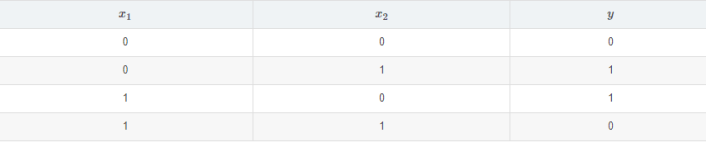
由此设计RBF网络
●输入层:由于有2个输入,所以输入层2个神经元
●隐层:隐层神经元越多拟合的越好,设为可变的t个,但至少要比输入层多1个。
●输出层: 1个神经元.
该网络的参数有:
●xy:样本参数
●wi:隐层第i个神经元与输出神经元的权值
●ci:隐层第i个神经元的中心
●βi:样本与第i个神经元的中心的距离的缩放系数
Ci通过对x聚类或者随即采样获得。
下面使用ABP算法来确定参数wi, βi;(由于是基于ABP来改的)

迭代次数:144
累计误差:0.000088
结果如下:




分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)