
Flink基础及理论
1、Flink特点1)事件驱动(Event-driven)2)基于流处理一切皆由流组成,离线数据是有界的流;实时数据是一个没有界限的流。(有界流、无界流)3)分层API越顶层越抽象,表达含义越简明,使用越方便越底层越具体,表达含义越丰富,使用越灵活4)Flink 对比 SparkStreaming数据模型:Spark采用RDD模型,spark streaming的DStream实际上也就是一组组小
1、Flink特点
1)事件驱动(Event-driven)
2)基于流处理
一切皆由流组成,离线数据是有界的流;实时数据是一个没有界限的流。(有界流、无界流)
3)分层API
越顶层越抽象,表达含义越简明,使用越方便
越底层越具体,表达含义越丰富,使用越灵活
4)Flink 对比 SparkStreaming
数据模型:
Spark采用RDD模型,spark streaming的DStream实际上也就是一组组小批数据RDD的集合,flink基本数据模型是数据流,以及事件(Event)序列
运行时架构:
spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个,flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点处理
场景:
批处理=>几组或所有数据到达后才处理;
流处理=>有数据来就直接处理,不等数据堆叠到一定数量级;
不像批处理有groupBy => 所有数据统一处理,而是用流处理的keyBy => 每一个数据都对key进行hash计算,进行类似分区的操作,来一个数据就处理一次,所有中间过程都有输出!
2、关于Flink部署
2.1)Standalone模式
1、Flink 中每一个 TaskManager 都是一个JVM进程,它可能会在独立的线程上执行一个或多个 subtask
2、为了控制一个 TaskManager 能接收多少个 task, TaskManager 通过 task slot 来进行控制(一个 TaskManager 至少有一个 slot)
3、每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot(注:这里不会涉及CPU的隔离,slot仅仅用来隔离task的受管理内存)
4、可以通过调整task slot的数量去自定义subtask之间的隔离方式。如一个TaskManager一个slot时,那么每个task group运行在独立的JVM中。而当一个TaskManager多个slot时,多个subtask可以共同享同一个JVM,而在同一个JVM进程中的task将共享TCP连接和心跳消息,也可能共享数据集和数据结构,从而减少每个task的负载。


默认情况下,Flink 允许子任务共享 slot,即使它们是不同任务的子任务(前提是它们来自同一个job)。 这样的结果是,一个 slot 可以保存作业的整个管道。Task Slot 是静态的概念,是指 TaskManager 具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度parallelism是动态概念,即TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。 举例:如果总共有3个TaskManager,每一个TaskManager中分配了3个TaskSlot,也就是每个TaskManager可以接收3个task,这样我们总共可以接收9个TaskSot。但是如果我们设置parallelism.default=1,那么当程序运行时9个TaskSlot将只有1个运行,8个都会处于空闲状态,所以要学会合理设置并行度!具体图解如下:

conf/flink-conf.yaml配置文件中
taskmanager.numberOfTaskSlots
parallelism.default
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
注:Flink存储State用的是堆外内存,所以web UI里JVM Heap Size和Flink Managed MEM是两个分开的值。
提交方式分为Web UI 提交方式和命令行提交job
YARN模式
以Yarn模式部署Flink任务时,要求Flink是有 Hadoop 支持的版本,Hadoop 环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务
Flink ON Yarn
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式
1、Session-Cluster模式
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业
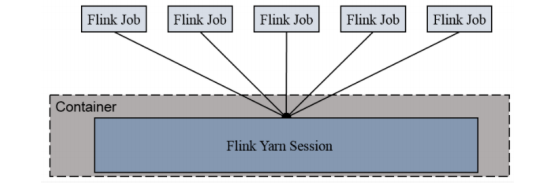
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止
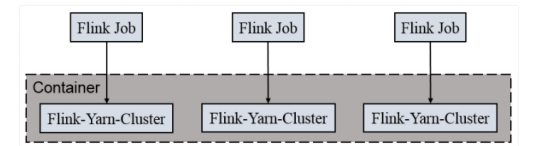
Per Job Cluster模式
一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失
Session-Cluster模式场景使用:
1.启动Hadoop集群
2.启动yarn-session ./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
-n(--container):TaskManager的数量
-s(--slots):每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余
-jm:JobManager的内存(单位MB)
-tm:每个taskmanager的内存(单位MB)
-nm:yarn 的appName(现在yarn的ui上的名字)
-d:后台执行
Kubernetes部署(略)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)