
Deep Learning Applied to Steganalysis of Digital Images: A Systematic Review 深度学习在数字图像隐写分析中的应用:系统综述
Deep Learning Applied to Steganalysis of Digital Images: A Systematic Review (深度学习在数字图像隐写分析中的应用:系统综述)摘要隐写术包括将消息隐藏在被称为载体的对象内,以建立隐蔽的通信通道,从而使能够访问该通道的观察者不会注意到通信行为本身。隐写分析致力于使用隐写术检测隐藏消息;这些消息可以隐含在不同类型的媒体中,例如
Deep Learning Applied to Steganalysis of Digital Images: A Systematic Review (深度学习在数字图像隐写分析中的应用:系统综述)
摘要
隐写术包括将消息隐藏在被称为载体的对象内,以建立隐蔽的通信通道,从而使能够访问该通道的观察者不会注意到通信行为本身。隐写分析致力于使用隐写术检测隐藏消息;这些消息可以隐含在不同类型的媒体中,例如数字图像、视频文件、音频文件或纯文本。传统上,隐写分析分为两个独立的阶段,第一阶段包括人工提取复杂特征,第二阶段是使用集成分类器(Ensemble Classifiers)或支持向量机( Support Vector Machines)进行分类。近年来,深度学习的发展使得将这两个传统阶段统一并自动化成为端到端的方法成为可能,并取得了良好的效果。本文展示了近年来利用深度学习技术进行隐写分析的进展。这些技术的结果在空间和频率(JPEG)领域都超过了传统方法(使用集成分类器的丰富模型(Rich Models with Ensemble Classifiers))获得的结果。自2014年以来,研究人员使用卷积神经网络来解决这一问题,生成不同的体系结构和策略,以提高上一代算法(WOW、S-UNIW ARD、HUGO、J-UNIW ARD等)的隐写图像检测率。深入学习,正在应用于隐写分析,目前正在建设过程中,到目前为止的结果是令人鼓舞的研究人员感兴趣的主题。
导言
隐写术是将信息隐藏在数字多媒体文件(图像、声音和视频)中,任何接收器都无法察觉。描述这些技术使用的第一批文件可以追溯到古希腊希罗多德时代。有一个故事描述了他们如何向斯巴达发出信息,警告说薛西斯打算入侵希腊,这样希腊就不会被发现,也不会引起怀疑。当时它写在涂有蜡的木板上。所以,为了掩饰他们直接写在木头上的信息,他们用蜡覆盖它,然后再写在上面。乍一看,人们只能看到蜡上的文字,但如果把它去掉,人们就可以看到隐藏在木头里的信息。在第二次世界大战期间,最常用的系统是将一条信息缩微成胶卷,并将其缩小到一个极小的高度,这样它就可以在另一个文本中作为一个字符的标点符号传递。例如,元音“i”上的点可以是带有消息的缩微胶片[1]。这种技术已经成为隐藏信息的令人兴奋的替代方法,因为加密技术在所有国家都是不允许的[2]。隐写术过程的形成是由于[3]中解释的著名的西蒙斯囚犯问题,其中包括两名囚犯,爱丽丝和鲍勃,他们希望在被监狱长夏娃不断截获的同时交换信息。如果Eve认为Alice和Bob之间交换的消息可疑,她将不允许这些消息到达收件人。
工业隐写术已被用于控制数字材料的非法复制,因此版权协会通过将数字内容以一种不易察觉的方式修改到人眼来引入信息,目的是提供谁拥有图像或图像被出售或发送给谁的证据[4]。在军事层面上,这项技术已被广泛应用于传输重要信息而不被对方识别。人们还认为,隐写术甚至可以用于非法团体和恐怖分子的通信。
隐写术可以从两个领域完成:空间或频率。从空间域来看,这些算法的特点是直接改变人眼无法感知的图像的某些像素。实现此目标的一种方法是通过顺序或随机更改每个像素的最低有效位(LSB)来引入消息[5],[6]。目前,隐写术是自适应完成的,也就是说,它考虑了图像的内容,以便在隐写器更难检测到的区域引入消息。该领域最常用的算法是HUGO[7]、HILL[8]、MiPOD[9]、S-UNIWARD[10]和WOW[11]。图1显示了使用S-UNIW ARD算法,在有效负载(嵌入更改的数量)为0的情况下,将隐写图像与隐写过程后的封面图像进行比较。每像素4位(bpp)。在图的右侧,显示了图像中的差异,以说明算法对隐藏图像的影响。

有大量使用频域变换(JPEG-联合摄影专家组)来进行隐写术,如离散余弦变换(DCT)、离散小波变换(DWT)和奇异值分解(SVD),所有这些都在[13]中进行了解释。JPEG是数码相机、扫描仪和其他基于DCT的摄影捕获设备生成的图像最常见的丢失压缩格式。所用变换的某些系数被更改,以便在JPEG域中插入消息,从而使人眼无法看到。该领域中使用最多的算法是J-UNIWARD[10]、F5[14]、UED[15]和UERD[16]。
隐写分析包括检测图像是否有隐藏消息。在[13]中,对隐写术和隐写分析及其各自的分类进行了更深入的解释。隐写术传统上分为两个阶段。第一阶段包括手动提取特征,其中使用丰富模型(RM)获得了最佳结果[17]。第二阶段基于二值分类器(图像是否隐写),其中通常使用集成分类器(EC)[18]、支持向量机(SVM)[19]或感知器(perceptrons)[20]。由于深度学习(DL)[21]和图形处理单元(GPU)[22]的进步,研究人员已开始将这些技术应用于隐写术和隐写分析,以获得更好的隐写图像检测率。将DL用于隐写分析时,特征提取阶段和分类在同一架构下统一,同时优化参数,从而降低了手动特征提取引入的复杂性和维数[17]。图2显示了隐写分析的一般结构,其中手动提取特征(顶部)和隐写分析在相同架构下统一提取和分类(底部)。

A. BACKGROUND
2014年,Tan和Li[23]开发了DL在隐写分析中的第一个应用,他们的方法使用了从训练卷积神经网络(CNN)的自动编码器堆栈中的无监督学习。然后使用有监督学习,使用高通滤波器(HPF)对图像进行预处理,以增加嵌入过程引入的隐写噪声功率。隐写图像的检测百分比比通过空间丰富模型Spatial Rich Models (SRM)[17]获得的检测百分比低约17%,比通过减法像素邻接矩阵 Subtractive Pixel Adjacency Matrix(SPAM)[24]获得的检测百分比高约11%。
2015年,钱银龙等人[25]利用监督学习方法设计了第一个CNN(GNCNN),该方法由5个卷积层和一个称为高斯激活的特定激活函数组成。隐写图像的检测百分比比SRM获得的检测百分比低约4%[17],比SPAM获得的检测百分比高约10%[24]。
然后在2016年,Pibre,Chaumont等人[26]接管了钱的工作,提出了两个新的神经网络。第一个是两层CNN,第二个是由两层组成的全连接神经网络(FNN)。他们的实验的特点是使用相同的加密密钥。Xu,Shi等人[27]提出了一种类似于钱的CNN,具有5个卷积层。与该网络不同,Xu,Shi等人使用绝对值层(ABS)和1×1卷积核来加强统计建模并获得更好的结果。Xu,Shi等人将他们提出的网络作为基础学习器[28]来训练CNN集,以获得更好的训练参数并进一步改进其检测结果。同年,钱、谭等人使用迁移学习[29]将一个CNN的参数交换给另一个CNN,该CNN使用高有效载荷的隐写图像进行训练,而另一个CNN将接受训练以检测低有效载荷的图像。与不使用迁移学习的CNN相比,获得的结果有所改善,但仍不会超过传统算法。以前获得的所有改进都是在空间域中实现的。之后,研究人员将重点放在使用频域DL技术(JPEG)进行隐写分析上。
在2017年,Zeng,Huang等人[30],[31]提出了一种CNN方法,使用适用于ImageNet提供的大型图像集的RM启发的预处理对JPEG格式图像执行隐写分析[32]。所得结果与文献中记录的结果接近。同年,Chen、Fridrich等人利用受JPEG压缩过程启发的PhaseSplit构建了一个新网络[30]。使用CNN汇编程序获得的结果明显高于通过最新技术获得的结果。随后,Xu[33]根据ResNet[34]的启发,提出了一种新的CNN,该CNN由20个卷积层组成,然后是批量标准化(BN)过程[35],[36]。Tang,Li等人[37]建议将两个相互竞争的网络作为参考,在空间域对图像进行隐写。这种被称为生成性对抗网络(GAN)的方法利用隐写术和隐写分析(2个竞争网络)之间的竞争来自动学习在何处嵌入消息的最佳位置。Ye,Yi等人[38]提出了一种新的空间域CNN,具有8个卷积层,一种称为截断线性单元Truncation Linear Unit(TLU)的自激活函数,以及用于图像预处理的滤波器组。这些滤波器组初始化其基于SRM的权重,以获得剩余特征图,并避免使用所有先前CNN使用的静态滤波器。2017年的趋势是培训CNN组,并修改网络架构,以模拟SRM特征提取过程。另一个重要贡献是在不同卷积层之间跳转连接(ResNet[34],[39]),从而能够设计更深层次的CNN,确保网络收敛并提高检测精度;在此之前,与文献记录相比,检测结果提高了约10%。
2018年,Yedulodj、Chaumont等人在空间领域提出了一种新的CNN[40]。该CNN将其前辈的最佳特征(一组基于SRM特征提取的预处理输入滤波器、5个卷积层、BN、TLU激活单元和训练数据库的增加)结合在一起,以从文献报告的结果中获得更好的结果。在[41]Tsang,Fridrich,et al.takeYe的网络中,对其进行了修改,使其能够将CNN训练中的高分辨率隐写图像与低分辨率图像进行分类。Yedrodj、Chaumont等人[42]研究了丰富隐写分析中传统使用的数据库(称为BOSSBASE)[43]的效果。添加的图像属于Bows2[44]数据库,以及使用相机拍摄的图像,其特征与用于创建传统数据库的特征相似。最后,使用裁剪、调整大小、旋转和插值操作增加了两个数据库中的图像数量。他们得出结论,为了提高隐写分析的性能,建议使用类似的摄像机和尺寸获取大型数据库。Chen,Fridrich等人[45]建议使用DL技术进行定量隐写分析,以在空间域和频域(JPEG)中预测隐写图像中包含的有效载荷。Li等人[46]建议将3个CNN并联。每个网络使用不同的预处理层进行特征提取(GABO滤波器〔47〕、线性SRM〔17〕、非线性SRM〔17〕),同时使用3个激活函数(Relu〔48〕、SigMoid[49〕和TANH[ 49〕),以便考虑更多的预处理信息。Zeng等人[50]在彩色图像上做了一个与前一个类似的实验。Boroumand Fredrich等人[34]提出了一种新的CNN,它尽可能避免使用技巧,例如使用SRM滤波器进行预处理。该网络在空间域和频率域都工作。Zhang等人[51]提出了一种新的CNN,该CNN优化了预处理层滤波器的权重,以增加隐写噪声的功率并降低图像内容。它使用单独的卷积分别获得剩余通道相关性和空间相关性,以获得更好的特征表示,最后使用空间金字塔池(SPP)[52]添加局部特征,提高特征表示能力,并允许任意图像大小。
论文的其余部分按以下顺序进行:第二节解释了如何对文献进行系统回顾。第三节介绍了发现的结果和最新技术。第四节给出了一些结论和未来的工作。
二、文献系统综述
本文综述了近年来DL在隐写分析中的应用进展,重点介绍了最重要的结果和可能的未来工作。建议读者先浏览[53]中的综述,该综述详细解释了隐写术和隐写分析背后的基本方法。本文献综述使用了[54]中提出的阶段,如下所述。
省略查文献说明部分。
表3。文章的标题、作者和发表年份按时间顺序显示。对于本文件的其余部分,当需要这些条款中的一条时,本表中给出的列表将用作惯例。这些文章是通过门捷利的申请组织起来的。最后,选取所选的文章,并根据Gogle Scholar提取引文数量,结果如图5所示。


三、 学科发展
由于前代网络的贡献,这些网络得以发展。到目前为止,提出的CNN按时间顺序依次为Qiannet或GNCNN[25]、XuNet[27]、Yenet[38]、Yedroudj-Net[40]、ZhuNet[51]。
从表5和表6可以看出,第一个实验是通过实现自动编码器堆栈,使用无监督学习完成的。自隐写分析的3个基本原则之后,监督学习的工作一直在继续:通过固定高通滤波器增强隐写噪声,提取特征和分类;所有这些都统一在一个同时优化其参数的单一体系结构下。研究人员首先在空间领域取得了进展,然后进入了频域(JPEG)。
研究人员在实验中使用CNN测试了不同的想法,其中最重要的是:增加网络的高度或使用完全连接的网络[26];使用自定义激活功能确保网络融合并提高隐写图像检测率[25]、[38]、[40];使用卷积层(剩余网络或密集网络)之间具有跳跃的CNN,以设计非常深的网络(20层或更多层),实现网络收敛并提高检测百分比[33]、[34]、[62]–[66];训练CNN集,并将学习到的参数转移到其收敛复杂或检测率较低的CNN中[28]、[29]、[61];使用特定数据库训练CNN,并使用完全不同的数据库测试网络,以确定所设计CNN的可靠性(覆盖源不匹配)[26],[61];通过绝对值层(ABS)加强统计建模[27],[28], [40], [51]; 通过使用设计的过滤器改进隐写术噪声提取,并使用CNN进行特征提取和分类[30]、[38]、[40]、[51];使用真实世界的数据库,如ImageNet,查看CNN如何适应具有不同分辨率和捕获特征的任何数据集[25]、[30]、[33]、[34]、[62]、[63];放置两个CNN进行竞争。在这种情况下,第一个网络用于隐写术,第二个网络用于隐写分析,目的是通过学习这两个过程的特征来获得自动隐写术过程[36]、[37]、[67]–[72];训练网络,使其能够将高分辨率图像与低分辨率图像进行分类[41];在空间域和JPEG域中使用DL预测隐写图像的有效载荷(定量隐写分析)[45],[73];考虑到修剪、旋转和插值操作,以及使用具有类似或不同特征的摄像机进行图像采集,并注意调整[30]、[38]、[51]、[74]的大小,从而增加数据库;将3个CNN并联工作[46],每个网络使用激活函数(ReLU、Sigmoid和TanH)和预处理层中的不同滤波器,其灵感来自Gapo滤波器[47]和SRM(线性和非线性)[17];与前一个类似,但在彩色图像[50]等方面。
大多数建议的网络使用等式1的高通滤波器,在[17]中开发,并首次用于隐写分析[25]。在训练过程中,高通滤波器参数未得到优化。该滤波器对图像进行预处理,以增强隐写噪声,减少图像内容的影响。该滤波器有助于CNN训练收敛;如果不使用收敛,则收敛可能较慢或不存在。最后设计的CNN不使用此过滤器;他们使用SRM提出的一组滤波器来获得剩余特征图。
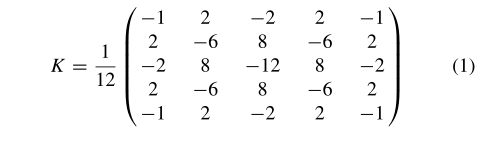
在CNN上执行的一般级别操作可以用等式2表示。其中,ml是第l层特征图之一,Mil−1是前一层特征的第i个映射,Kilis是第l层的第i个核,bl是第l层的偏差参数,∗ 是卷积运算,f()是称为激活函数的非线性运算,pool()是池运算,norm()是规范化运算。**卷积层中的操作顺序是卷积、规范化、激活函数和池。**最后一层获得的特征图被传递给分类模块,该模块由一个或多个完全连接的神经元层和一个Softmax层组成;最后一层负责规范化CNN在[0,1]之间的值,这些值依次是指示图像是覆盖还是隐藏的概率值。
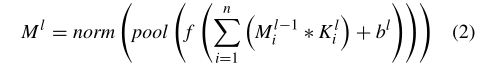
所研究的CNN中使用的非线性激活函数为整流线性单元(ReLU)[48]、正切双曲(TanH)[49]、高斯和TLU。最后一个激活函数不包括用于隐写分析的DL,其功能是限制值的范围并避免将网络建模为大值。通常tanh在第一层中使用,relu在最后一层中使用。
用于数据规范化的操作是BN,它总结为等式3[35]。BN包括规范化特征图中每个特征的分布,使平均值为零,方差为单位,并且可能(如有必要)允许重新缩放和重新转换分布。
给定一个随机变量x,其实现值为x∈特征图的R,该值x的BN为:
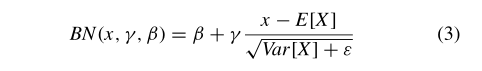
用e[X]表示期望值,用var[X]表示方差,用γ和β两个标量表示重缩放和重平移。每批更新期望值E[X]和方差Var[X],同时通过反向传播学习γ和β。实际上,BN降低了学习对参数初始化的敏感性[35],允许使用更高的学习速率,从而加快学习速度,并提高分类的准确性[61]。在第一个提议的CNN中,未使用BN。
平均池[75]操作通常用于所有CNN中的池,因为incrustation过程引入的隐写噪声非常弱,使用此操作有利于此类噪声的传播和保存,而在使用最大池[75]的情况下不会发生这种情况。通常使用的池是一个本地操作,由其邻居计算。
从研究中获得的最重要的CNN如下:QianNet或GNCNN(2015)[25],[76]、XuNet(2016)[27]、Yenet(2017)[38]、Yedroudjnet(2018)[40]和Zhunet(2018)[51],所有CNN最初都是在空间域中设计的,有些CNN适合在频域(JPEG)中工作。QianNet的特点是具有5个卷积层、高斯激活函数和每个卷积层后的平均池、2个完全连接层和1个Softmax。XuNet的特点是具有5个卷积层,第一个卷积层后有一个ABS层,前2个层使用TanH激活函数,后3个层使用ReLU,每个卷积层中有BN,2个完全连接层和1个Softmax。Yenet使用SRM滤波器组用噪声提取代替方程1的传统高通滤波器。该CNN由8个卷积层组成,在第一个卷积层之后使用TLU激活函数,对于其他层,使用TanH,它有1个完全连接层和1个Softmax。YedroodJnet使用SRM启发的滤波器组进行隐写噪声提取、5个卷积层、仅在第一个卷积层之后的ABS层、前2个层中的TLU激活函数、最后3个层中的ReLU、层2到5的平均池、2个完全连接的层和1个Softmax。CNN采用了XuNet和YeNet的最佳特性,并将它们统一在同一架构下。ZhuNet的特点是使用一个受SRM启发的滤波器组来初始化预处理层权重,该权重将在训练过程中进行优化,以增强隐写过程中引入的噪声并减少图像内容。ZhuNet使用单独的卷积来改进特征提取过程,最后使用称为空间金字塔池(SPP)[52]的多级平均池,以允许网络分析任意大小的图像,该CNN的结果优于Xunet、YeNet、YedroodJnet和SRM EC获得的结果。表4显示了上述CNN和SRM EC在有效载荷为0的空域(S-UNIW ARD和WOW)中检测两种算法的错误百分比。4bpp和0。2bpp。在[34]中,观察到一种称为SRNet的新网络设计,它减少了其他网络使用手动设备和启发式方法来捕获隐写噪声;该网络在空间和频率域中运行。
图6显示了迄今为止最重要的网络的体系结构。在紫色中,指定CNN的像素条目。在大多数实验中,由于处理限制和计算内存,图像大小为256×256。预处理层显示为黄色,其目的是增加隐写过程引入的噪声功率并减少图像内容。在绿色中,卷积层显示在完成分层特征提取的位置。在蓝色中,观察到激活、缩放、绝对值层和归一化的功能。白色显示减少特征映射维数和计算复杂性的池操作。由于隐写噪声的低功率,迄今为止设计的所有CNN都使用平均池操作,这使得有必要考虑池操作将发生的区域的所有像素,以便不丢失信息。红色和海蓝绿色表示分类模块,该模块由完全连接的神经元层和Softmax组成,Softmax负责为每个类别提供0到1之间的概率分布,定义图像是覆盖还是隐藏。
要正确阅读图6,必须考虑以下信息。框内的结构表示内核数×(内核的高度×宽度×作为内核项的特征映射数)。框外部的结构表示特征图的数量×(特征图的高度x宽度)。如果未指定步幅或填充,则假定步幅为1,填充为0。
图6。最常用的CNNs体系结构[25]、[27]、[38]、[40]、[51]。框中的数据具有以下结构:内核数x(高度x宽度x作为输入的特征贴图数)。框外数据具有以下结构:特征图数量×(高度×宽度)。如果未指定步幅或填充,则假定步幅为1,填充为0。


图7和图8显示了在0bpp到0.4bpp的范围内,根据有效载荷使用S-UNIWARD(图7)和WOW(图8)算法检测隐写图像的平均错误率。需要注意的是,随着有效载荷的增加,图像中引入的隐写噪声也会增加,这使得CNN能够从此类噪声中获得更多信息,从而提高检测百分比。对于S-UNIWARD算法(图7),无论有效载荷值是多少,ZhuNet都能获得最低的错误百分比,特别是0.4bpp(研究人员使用最多的有效载荷),ZhuNet设法将错误百分比降低了7。与YEDJnet(前身网络)相比,增长了5%,增长了9%。与SRM+EC(传统方法)相比为4%。YeNet在所有有效载荷期间获得了最高的错误率。

值得注意的是,SRM+EC、QianNet、XuNet、YeNe和YedroudjNet具有相似的行为,这使得ZhuNet成为第一个显著超过SRM+EC针对S-UNIWARD算法获得的检测百分比的CNN。对于WOW算法(图8),无论有效载荷值是多少,ZhuNet都获得了最低的错误百分比,特别是观察到0.4bpp,ZhuNet能够将错误百分比减少2。与去年同期相比增长了3%,比去年同期增长了13%。与SRM EC相比为7%。在所有有效载荷期间,QianNet获得了最高的错误率。需要指出的是,对于WOW算法,唯一未超过SRM+EC结果的CNN是QianNet(首次提出CNN),其他CNN已超过SRM+EC检测百分比。
研究文献中使用最多的速记算法是空间域的S-UNIW ARD、HUGO、HILL、WOW和频域的J-UNIW ARD、UED、UERD (JPEG),它们的有效载荷不同,通常,实验中最常用的有效载荷是0.4bpp(空间域)或0.4bpnzAC(每非零覆盖AC DCT系数的位)(JPEG域)。
四、结论与未来工作
除了CNN YuNet的一种自适应结构,即应用ResNet在频域(JPEG)中进行隐写分析外,还提出了不同的CNN体系结构来进行隐写分析,如上述的QianNet、YUnit、YeNet、YeNet、ZhuNet,所有这些结构都在空间域中。据观察,CNN-ZhuNet在空间域提供了最佳的检测结果,也改进了SRM提供的结果。SRNet是一种网络方案,它尽可能避免在隐写噪声提取过程中使用技巧或启发式方法,并在空间域和JPEG中工作。
根据目前的文献综述,我们设想未来可能的工作如下:
•生成新的CNN,统一现有网络的优势,或生成全新的架构(密集、浅层和/或深层架构),以提高空间域和频域的检测百分比。
•使用不同的数字图像数据库,例如考虑到不同相机的使用,以测试更多的实验并更深入地研究Cover Source失配效应通过测试。
•JPEG域中的更多隐写算法来执行隐写分析。
•采用GAN方法在空间域进行隐写分析,并使用它在JPEG域进行自动隐写调整进行定量隐写分析的CNN,以改善有效负载预测结果。
•将DL应用于定量隐写分析,以预测频域(JPEG)中的图像隐写有效载荷使用大型数据库和更大的图像大小培训现有CNN。为此,有必要在CPU和GPU集群架构下进行培训,以满足处理和内存需求使用给定的隐写算法训练CNN,并在另一个算法上进行测试,以研究从一个算法到另一个算法的传输量。
…

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)