Conformer: Convolution-augmented Transformer for Speech Recognition翻译
摘要最近,在自动语音识别(ASR)领域,Transformer和卷积神经网络(CNN)的模型已经显示出较好的结果,且优于循环神经网络(RNN)。变压器模型擅长捕获基于内容的全局交互,而CNNS有效利用本地特征。在这项工作中,我们通过研究如何将卷积神经网络和变换器组合起来以以参数有效的方式建模音频序列的本地和全局依赖性来实现两全其美。为此,我们提出了卷积增强的变压器,用于语音识别,名为Conform
摘要
最近,在自动语音识别(ASR)领域,Transformer和卷积神经网络(CNN)的模型已经显示出较好的结果,且优于循环神经网络(RNN)。Transformer模型擅长捕获基于内容的全局交互,而CNNS有效利用局部特征。在这项工作中,我们通过研究如何以参数高效的方式,将卷积神经网络和Transformer组合起来,来建模音频序列的局部和全局依存,从而充分利用两者优势。为此,我们提出了用于语音识别的卷积增强的Transformer,称为Conformer。Conformer显着优于以前的Transformer和基于CNN的模型,达到了最先进的精度。在广泛使用的LibriSpeech基准test/testother中,我们的模型在不使用语言模型的情况下实现2.1%/4.3%,在使用外部语言模型时达到1.9%/ 3.9%。当模型参数仅为10M时,我们同样观察到可竞争的性能:2.7%/ 6.3%。
1.介绍

近年来,基于神经网络的端到端自动语音识别(ASR)系统已经看到了很大的改进。循环神经网络(RNNS)一直是ASR的优先选择对象,因为它们可以有效地建模音频序列中的时间依赖性。最近,由于捕获远距离相互作用和高训练效率的能力,基于自注意力的Transformer架构对序列建模也被广泛的采用。另外,卷积网络也已经成功地应用到ASR,其通过逐层的局部感受野来捕获局部上下文信息。
然而,具有自注意力或卷积的模型具有一些限制。 虽然Transformer擅长建模远距离全局上下文信息,但它们不擅长提取细粒度的局部特征。另一方面,卷积神经网络(CNNS)利用局部信息作为视觉中的计算块,这些计算块在一个局部窗口中学习基于共享的位置核,这些窗口维护转换等因素,并且能够捕获边缘和形状等特征。使用局部连接的一个限制是需要更多的层或参数来捕获全局信息。为了解决这个问题,现有工作 ContextNet采用每个残差块中的squeeze和excitation模块来捕获更长的上下文。但是,在捕获动态全局上下文时仍然有限,因为它仅在整个序列上应用全局平均的值。
最近的工作表明,结合卷积和自注意力要由于单独使用它们。它们可以一起学习位置的局部特征,并使用基于内容的全局交互。同时,像[15,16]这些的论文使用基于相对位置的信息来增强自注意力。Wu et al. 提出了一种多分支架构,将输入分成两个分支:自注意力和卷积,并拼接他们的输出。他们的工作主要针对移动端应用,并显示了在机器翻译任务上的改进。
在这项工作中,我们研究了如何在ASR模型中有效地结合自注意力和卷积。我们假设全局和局部交互对于参数高效都非常重要。为实现这一目标,我们提出了一种新的自注意力和卷积结合方式,并在两大方面都表现最好:自注意力学习全句交互,同时卷积有效地捕获基于相对偏移的局部相关性。受 Wu et al.的启发,我们引入一种新的自注意力和卷积结合方式,位于两个Feed Fowrard模块之间,如图1所示。
我们所提出的模型,称为Conformer,实现了LibrisPeech的最新结果,在 testother dataset 上使用一个外部语言模型,与前一个最佳的Transformer Transducer相比相对提升了15%。我们提出了三种尺寸模型:10m,30m和118m。与相似大小的同期工作相比,我们的10M模型在 test/testother datasets上显示出了2.7%/ 6.3%的改进。我们的中等30M参数大小的模型已经优于[7]中发布的transformer transducer,它使用了139M大小参数。使用大型118M参数模型,我们能够在不使用语言模型的情况下实现2.1%/ 4.3%,在使用外部语言模型后则为1.9%/ 3.9%。
我们进一步仔细研究了注意力头数,卷积核大小,激活函数,前馈层的放置位置以及将卷积模块添加到基于Transformer的网络不同位置,对准确率提升的影响。
2.Conformer Encoder
我们的音频编码器首先使用卷积下采样层处理输入,然后再使用多个conformer blocks进行处理,如图1所示。我们的模型的特点是在Transformer blocks的位置使用Conformer blocks,如[7, 19]中一样。
conformer block由堆叠在一起的四个模块组成,即前馈模块,自注意力模块,卷积模块和第二个前馈模块。第2.1, 2.2和2.3节分别介绍了自注意力,卷积和前馈模块。最后,2.4描述了这些块如何组合。
2.1 Multi-Headed Self-Attention Module

我们采用了多头自注意力机制(MHSA),同时集成了来自Transformer-XL的重要技术,相对正弦位置编码方案。相对位置编码允许自注意力模块在不同的输入长度上更好地归一化概率,并且所得到的编码器对序列长度的方差更鲁棒。我们使用具有dropout的prenorm的残差单元,从而有助于训练和正则化更深的模型。图3说明了多头自注意力块结构。
2.2 Convolution Module
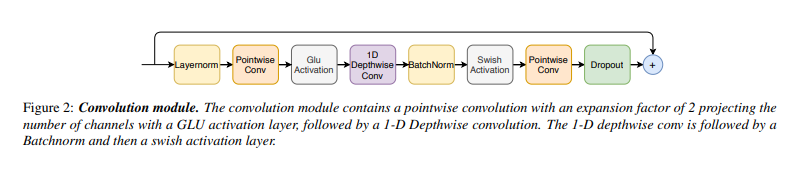
受 [17] 中工作的启发,使用一个具有门控机制的卷积模块 - pointwise卷积和门控线性单元(GLU)。接下来是单个1-D深度卷积层。在卷积后部署Batchnorm以帮助训练深层模型。图2示出了卷积块结构。
2.3 Feed Forward Module
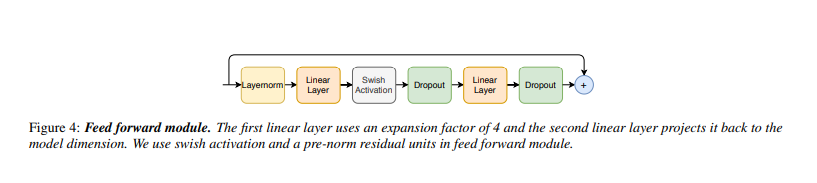
如[6]中提出的Transformer架构中,其在MHSA层之后使用了一个前馈模块,并且由两个线性变换和之间的非线性激活组成。在前馈层上添加残差连接,然后进行层标准化。该结构也由Transformer ASR模型采用。
我们遵循pre-norm residual units,使用具有残差单元的层归一化,并在第一个线性层的输入前也应用层归一化。我们还应用Swish激活和dropout,这有助于正则化网络。图4示出了前馈(FFN)模块。
2.4 Conformer Block
我们所提出的Conformer block包含两个前馈模块,位于多头自注意力模块和卷积模块前后,如图1所示。
这种结构受Macaron-Net工作的启发,该工作提出将Transformer block中的原始前馈层替换为两个half-step前馈层,一个在注意力层之前,一个在其后。与Macaron-Net一样,我们在前馈(FFN)模块中使用half-step残差权重。第个二前馈模块之后紧接一个final layernorm层。因此,给定一个输入
x
i
x_i
xi和一个Conformer block
i
i
i,块的输出
y
i
y_i
yi是:
x
~
=
x
i
+
1
2
F
F
N
(
x
i
)
x
i
′
=
x
~
i
+
M
H
S
A
(
x
~
i
)
x
i
′
′
=
x
i
′
+
C
o
n
v
(
x
i
′
)
y
i
=
L
a
y
e
r
n
o
r
m
(
x
i
′
′
+
1
2
F
F
N
(
x
i
′
′
)
)
(1)
\begin{array} {ll} \tilde x=x_i + \frac{1}{2}FFN(x_i) \\ x'_i=\tilde x_i+MHSA(\tilde x_i)\\ x''_i=x'_i+Conv(x'_i)\\ y_i=Layernorm(x''_i+\frac{1}{2}FFN(x''_i)) \end{array}\tag{1}
x~=xi+21FFN(xi)xi′=x~i+MHSA(x~i)xi′′=xi′+Conv(xi′)yi=Layernorm(xi′′+21FFN(xi′′))(1)
其中FFN指的是前馈模块,MHSA是指多头自注意力模块,并且CONV指的是如前一节所述的卷积模块。
我们在3.4.3节中讨论了我们的消融实验,将MacaronFFN与先前工作中使用的Vanilla FFN进行比较。我们发现,具有两个带有半步残差连接的Macaron-Net风格的前馈层,并在两层之间包裹注意力和卷积模块,与具有单个前馈模块的Conformer结构相比,性能具有显著提升。
在之前研究过卷积和自注意力的组合中,人们想象了多种可能实现的方法。3.4.2节中研究了具有自注意力的增强卷积的不同选择。我们发现在自注意力模块后堆叠的卷积模块最适合语音识别。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)