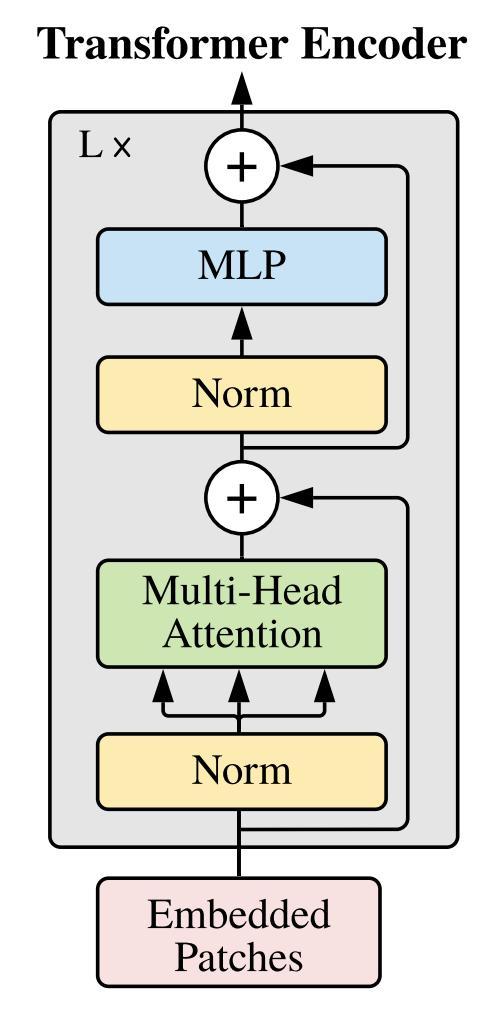
PyTorch实现Vision Transformer
ViT详解参见博客blog以下分别是模型代码和训练代码:ViT.py#!/usr/bin/envpython#-*- coding:utf-8 -*-import torchfromtorch import nn, einsumimport torch.nn.functional as Ffromeinops import rearrange, repeatclass Residual(nn.Mo
·
ViT详解参见博客blog
以下分别是模型代码和训练代码:
ViT.py
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential( nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout) )
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.scale = dim ** -0.5
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(nn.Linear(inner_dim, dim), nn.Dropout(dropout) )
def forward(self, x, mask = None):
# b, 65, 1024, heads = 8
b, n, _ = x.shape
h = self.heads
# self.to_qkv(x): b, 65, 64*8*3
# qkv: b, 65, 64*8
qkv = self.to_qkv(x).chunk(3, dim = -1) # 沿-1轴分为3块
# b, 65, 64, 8
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
# dots:b, 65, 64, 64
dots = torch.einsum('bhid,bhjd->bhij', q, k) * self.scale
mask_value = -torch.finfo(dots.dtype).max
if mask is not None:
mask = F.pad(mask.flatten(1), (1, 0), value = True)
assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions'
mask = mask[:, None, :] * mask[:, :, None]
dots.masked_fill_(~mask, mask_value)
del mask
# attn:b, 65, 64, 64
attn = dots.softmax(dim=-1)
# 使用einsum表示矩阵乘法:
# out:b, 65, 64, 8
out = torch.einsum('bhij,bhjd->bhid', attn, v)
# out:b, 64, 65*8
out = rearrange(out, 'b h n d -> b n (h d)')
# out:b, 64, 1024
out = self.to_out(out)
return out
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([ Residual(PreNorm(dim, Attention( dim, heads = heads, dim_head = dim_head, dropout = dropout))),
Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))) ]))
def forward(self, x, mask = None):
for attn, ff in self.layers:
x = attn(x, mask = mask)
x = ff(x)
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
# assert num_patches > MIN_NUM_PATCHES, f'your number of patches ({num_patches}) is way too small for attention to be effective (at least 16). Try decreasing your patch size'
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential( nn.LayerNorm(dim), nn.Linear(dim, num_classes) )
def forward(self, img, mask = None):
p = self.patch_size
# 图片分块
# print(img.shape)
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p) # 1,3,256,256 -> 1,64,3072
# 降维(b,N,d)
x = self.patch_to_embedding(x)
b, n, _ = x.shape
# 多一个可学习的x_class,与输入concat在一起,一起输入Transformer的Encoder。(b,1,d)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
# Positional Encoding:(b,N+1,d)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
# Transformer的输入维度x的shape是:(b,N+1,d)
x = self.transformer(x, mask)
# (b,1,d)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x) # (b,1,num_class)
if __name__ == '__main__':
v = ViT(image_size=256, patch_size=32, num_classes=10, dim=1024, depth=6, heads=16, mlp_dim=2048, dropout=0.1,
emb_dropout=0.1)
img = torch.randn(1, 3, 256, 256)
mask = torch.ones(1, 8, 8).bool() # optional mask, designating which patch to attend to
preds = v(img, mask=mask) # (1, 1000)
print(preds)
train.py
import os
import torchvision.transforms as transforms
from torchvision import datasets
import torch.utils.data as data
import torch
import numpy as np
import matplotlib.pyplot as plt
import torchvision.models as models
import ViT
BATCH_SIZE=32
DEVICE='cuda'
path='F:\\data\\flower_photos\\flower_photos'
flower_class=['daisy','dandelion','roses','sunflowers','tulips']
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
image_path = path
trainset = datasets.ImageFolder(root=image_path,
transform=transform["train"])
trainloader = data.DataLoader(trainset, BATCH_SIZE, shuffle=True)
print(trainset.classes) #根据分的文件夹的名字来确定的类别
print(trainset.class_to_idx) #按顺序为这些类别定义索引为0,1...
# print(trainset.imgs) #返回从所有文件夹中得到的图片的路径以及其类别
model = ViT.ViT(image_size=256, patch_size=32, num_classes=5, dim=1024, depth=6, heads=16, mlp_dim=2048, dropout=0.1,
emb_dropout=0.1)
model=model.to(DEVICE)
#img = torch.randn(1, 3, 256, 256)
#mask = torch.ones(1, 8, 8).bool() # optional mask, designating which patch to attend to
#preds = model(img, mask=mask) # (1, 1000)
#print(preds)
# 模型训练
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001)
epoch_n = 20
torch.cuda.empty_cache()
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch + 1, epoch_n))
print("-" * 10)
# 设置为True,会进行Dropout并使用batch mean和batch var
model.train(True)
running_loss = 0.0
running_corrects = 0
# enuerate(),返回的是索引和元素
for batch, data in enumerate(trainloader):
X, y = data
X, y=X.to(DEVICE), y.to(DEVICE)
y_pred = model(X)
# pred,概率较大值对应的索引值,可看做预测结果
_, pred = torch.max(y_pred.data, 1)
# 梯度归零
optimizer.zero_grad()
# 计算损失
loss = loss_f(y_pred, y)
loss.backward()
optimizer.step()
# 计算损失和
running_loss += float(loss)
# 统计预测正确的图片数
running_corrects += torch.sum(pred == y.data)
if batch%10==9:
print("loss=",running_loss/(BATCH_SIZE*10))
print("acc is {}%".format(running_corrects.item()/(BATCH_SIZE*10)*100.0))
running_loss=0
running_corrects=0
torch.save(model.state_dict(),'model.pkl')

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)