
FLOPs、FLOPS、Params的含义及PyTorch中的计算方法
FLOPs、FLOPS、Params的含义及PyTorch中的计算方法含义解释FLOPS:注意全大写,是floating point operations per second的缩写(S表second秒),表示每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。FLOPs:注意s小写,是floating point operations的缩写(s表复数),表示浮点运算数,理解为计算量。可以
FLOPs、FLOPS、Params的含义及PyTorch中的计算方法
含义解释
-
FLOPS:注意全大写,是floating point operations per second的缩写(这里的大S表示second秒),表示每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
-
FLOPs:注意s小写,是floating point operations的缩写(这里的小s则表示复数),表示浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
-
Params:没有固定的名称,大小写均可,表示模型的参数量,也是用来衡量算法/模型的复杂度。通常我们在论文中见到的是这样:# Params,那个井号是表示 number of 的意思,因此 # Params 的意思就是:参数的数量。
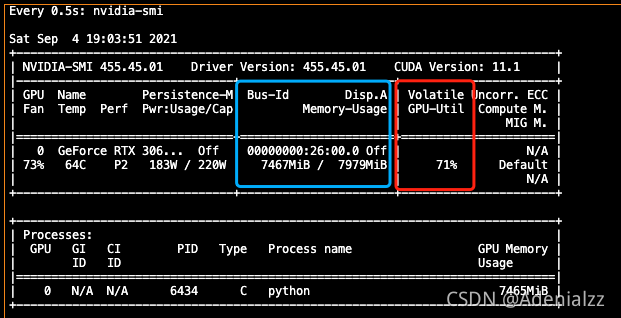
FLOPs与模型时间复杂度、GPU利用率有关,Params与模型空间复杂度、显存占用有关。即我们常见的nvidia-smi命令中的GPU利用率(红框)和显存占用(篮框)。
MAC
MAC:Multiply Accumulate,乘加运算。乘积累加运算(英语:Multiply Accumulate, MAC)是在数字信号处理器或一些微处理器中的特殊运算。实现此运算操作的硬件电路单元,被称为“乘数累加器”。这种运算的操作,是将乘法的乘积结果和累加器的值相加,再存入累加器:
a
←
a
+
b
×
c
a\leftarrow a+b\times c
a←a+b×c
使用MAC可以将原本需要的两个指令操作减少到一个指令操作,从而提高运算效率。
FLOPs的计算
以下不考虑激活函数的计算量。
卷积层
( 2 × C i × K 2 − 1 ) × H × W × C 0 (2\times C_i\times K^2-1)\times H\times W\times C_0 (2×Ci×K2−1)×H×W×C0
C i C_i Ci=输入通道数, K K K=卷积核尺寸, H , W H,W H,W=输出特征图空间尺寸, C o C_o Co=输出通道数。
一个MAC算两个个浮点运算,所以在最前面 × 2 \times 2 ×2。不考虑bias时有 − 1 -1 −1,有bias时没有 − 1 -1 −1。由于考虑的一般是模型推理时的计算量,所以上述公式是针对一个输入样本的情况,即batch size=1。
理解上面这个公式分两步,括号内是第一步,计算出输出特征图的一个pixel的计算量,然后再乘以 H × W × C o H\times W\times C_o H×W×Co 拓展到整个输出特征图。
括号内的部分又可以分为两步, ( 2 ⋅ C i ⋅ K 2 − 1 ) = ( C i ⋅ K 2 ) + ( C i ⋅ K 2 − 1 ) (2\cdot C_i\cdot K^2-1)=(C_i\cdot K^2)+(C_i\cdot K^2-1) (2⋅Ci⋅K2−1)=(Ci⋅K2)+(Ci⋅K2−1)。第一项是乘法运算数,第二项是加法运算数,因为 n n n 个数相加,要加 n − 1 n-1 n−1 次,所以不考虑bias,会有一个 − 1 -1 −1,如果考虑bias,刚好中和掉,括号内变为 2 ⋅ C i ⋅ K 2 2\cdot C_i\cdot K^2 2⋅Ci⋅K2。
全连接层
全连接层: ( 2 × I − 1 ) × O (2\times I-1)\times O (2×I−1)×O
I I I=输入层神经元个数 , O O O=输出层神经元个数。
还是因为一个MAC算两个个浮点运算,所以在最前面 × 2 \times 2 ×2。同样不考虑bias时有 − 1 -1 −1,有bias时没有 − 1 -1 −1。分析同理,括号内是一个输出神经元的计算量,拓展到 O O O了输出神经元。
NVIDIA Paper [2017-ICLR]
笔者在这里放上 NVIDIA 在 【2017-ICLR】的论文:PRUNING CONVOLUTIONAL NEURAL NETWORKS FOR RESOURCE EFFICIENT INFERENCE 的附录部分FLOPs计算方法截图放在下面供读者参考。

使用PyTorch直接输出模型的Params(参数量)
完整统计参数量
import torch
from torchvision.models import resnet50
import numpy as np
Total_params = 0
Trainable_params = 0
NonTrainable_params = 0
model = resnet50()
for param in model.parameters():
mulValue = np.prod(param.size()) # 使用numpy prod接口计算参数数组所有元素之积
Total_params += mulValue # 总参数量
if param.requires_grad:
Trainable_params += mulValue # 可训练参数量
else:
NonTrainable_params += mulValue # 非可训练参数量
print(f'Total params: {Total_params / 1e6}M')
print(f'Trainable params: {Trainable_params/ 1e6}M')
print(f'Non-trainable params: {NonTrainable_params/ 1e6}M')
输出:
Total params: 25.557032M
Trainable params: 25.557032M
Non-trainable params: 0.0M
简单统计可训练的参数量
通常,我们想知道的只是可训练的参数量,我们也可以简单地直接一行统计出可训练的参数量:
import torchvision.models as models
model = models.resnet50(pretrained=False)
Trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'Trainable params: {Trainable_params/ 1e6}M')
输出:
Trainable params: 25.557032M
统计每一层的参数量
倘若想要统计每一层的参数量,参考代码如下:
model = vgg16()
for name, parameters in model.named_parameters():
print(name, ':', np.prod(parameters.size()))
会打印出每一层的名称及参数量:
features.0.weight : 1728
features.0.bias : 64
features.2.weight : 36864
features.2.bias : 64
features.5.weight : 73728
...
使用thop库来获取模型的FLOPs(计算量)和Params(参数量)
安装
直接pypi安装即可
pip install thop
使用
我们使用thop库来计算vgg16模型的计算量和参数量。
import torch
from thop import profile
from archs.ViT_model import get_vit, ViT_Aes
from torchvision.models import resnet50
model = resnet50()
input1 = torch.randn(4, 3, 224, 224)
flops, params = profile(model, inputs=(input1, ))
print('FLOPs = ' + str(flops/1000**3) + 'G')
print('Params = ' + str(params/1000**2) + 'M')
输出:
FLOPs = 16.446058496G
Params = 25.557032M
Ref:
https://openreview.net/forum?id=SJGCiw5gl
https://www.zhihu.com/question/65305385/answer/451060549
https://www.cnblogs.com/chuqianyu/p/14254702.html

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)