
中文文本生成知识图谱
1.工具1.1 Jiagu 自然语言处理工具Jiagu使用大规模语料训练而成。将提供中文分词、词性标注、命名实体识别、情感分析、知识图谱关系抽取、关键词抽取、文本摘要、新词发现、情感分析、文本聚类等常用自然语言处理功能。Jiagu 详细内容参考:https://github.com/ownthink/Jiagu1.2 Neo4jubuntu 安装 neo4j安装服务端wget -O - https
一键AI生成摘要,助你高效阅读
问答
·
1.工具
1.1 Jiagu 自然语言处理工具
Jiagu使用大规模语料训练而成。将提供中文分词、词性标注、命名实体识别、情感分析、知识图谱关系抽取、关键词抽取、文本摘要、新词发现、情感分析、文本聚类等常用自然语言处理功能。
Jiagu 详细内容参考:https://github.com/ownthink/Jiagu
1.2 Neo4j
ubuntu 安装 neo4j
- 安装服务端
wget -O - https://debian.neo4j.org/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.org/repo stable/' | sudo tee /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
- 安装社区版:
sudo apt-get install neo4j
- 安装企业版
sudo apt-get install neo4j-enterprise
- 安装客户端
sudo add-apt-repository ppa:cleishm/neo4j
sudo apt-get update
sudo apt-get install neo4j-client libneo4j-client-dev
1.3 py2neo
- 安装 py2neo
pip install py2neo
1.4 pandas
将 python List 转为 pandas.DataFrame 进而存储为 csv 文件
2.数据处理
2.1 知识图谱关系抽取
import jiagu
text = '姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。'
knowledge = jiagu.knowledge(text)
print(knowledge)
[['姚明', '出生日期', '1980年9月12日'],
['姚明', '出生地', '上海市徐汇区'],
['姚明', '祖籍', '江苏省苏州市吴江区震泽镇']]
2.2 list 存储为 csv
data = pd.DataFrame(data=knowledge)
data
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 姚明 | 出生日期 | 1980年9月12日 |
| 1 | 姚明 | 出生地 | 上海市徐汇区 |
| 2 | 姚明 | 祖籍 | 江苏省苏州市吴江区震泽镇 |
data.to_csv('input.csv', encoding='utf-8')
至此,中文文本经过了知识图谱关系抽取形成List,并将 List 存储为 csv 格式。接下来,就可以使用 py2neo API 实现知识图谱的构建。
2.3 py2neo
graph = Graph('http://localhost:7474', user='neo4j', password='neo4j')
graph.delete_all()
with open('input.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for item in reader:
if reader.line_num == 1: # 过滤掉 csv 第 1 列, 0, 1, 2
continue
print("当前行数: ", reader.line_num, "当前内容: ", item)
start_node = Node("姓名", name=item[1])
end_node=Node("属性值", value=item[3])
relation=Relationship(start_node, item[2], end_node)
graph.merge(start_node, "姓名", "name")
graph.merge(end_node, "属性值", "value")
graph.merge(relation, "值", "属性")
当前行数: 2 当前内容: ['0', '姚明', '出生日期', '1980年9月12日']
当前行数: 3 当前内容: ['1', '姚明', '出生地', '上海市徐汇区']
当前行数: 4 当前内容: ['2', '姚明', '祖籍', '江苏省苏州市吴江区震泽镇']
3. Neo4j 数据展示
Neo4j 图数据库已经启动,在浏览器中输入: http://loaclhost:7474 即可访问。
中文文本经过关系抽取之后构建出来的知识图谱如下图所示:
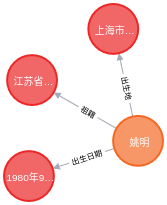
完整代码
import jiagu
import csv
import pandas as pd
import py2neo
from py2neo import Graph, Node, Relationship
# 中文文本导入
text = '姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。'
# 关系抽取
knowledge = jiagu.knowledge(text)
# 将抽取到的关系转为 pandas.DataFrame 进而存储为 csv 文件
data = pd.DataFrame(data=knowledge)
data.to_csv('input.csv', encoding='utf-8')
# 连接本地 Neo4j 图数据库
graph = Graph('http://localhost:7474', user='neo4j', password='1991')
graph.delete_all()
# 构建知识图谱
with open('input.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for item in reader:
if reader.line_num == 1: # 过滤掉第 1 列(0, 1, 2)
continue
print("当前行数: ", reader.line_num, "当前内容: ", item)
start_node = Node("姓名", name=item[1])
end_node=Node("属性值", value=item[3])
relation=Relationship(start_node, item[2], end_node)
graph.merge(start_node, "姓名", "name")
graph.merge(end_node, "属性值", "value")
graph.merge(relation, "值", "属性")

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)