4. Python实现VRP常见求解算法——蚁群算法(ACO)
参考笔记https://github.com/PariseC/Algorithms_for_solving_VRP1. 适用场景求解CVRP车辆类型单一车辆容量不小于需求节点最大需求单一车辆基地2. 问题分析CVRP问题的解为一组满足需求节点需求的多个车辆的路径集合。假设某物理网络中共有10个顾客节点,编号为1~10,一个车辆基地,编号为0,在满足车辆容量约束与顾客节点需求约束的条件下,此问题的一
参考笔记
https://github.com/PariseC/Algorithms_for_solving_VRP
1. 适用场景
- 求解CVRP
- 车辆类型单一
- 车辆容量不小于需求节点最大需求
- 单一车辆基地
2. 问题分析
CVRP问题的解为一组满足需求节点需求的多个车辆的路径集合。
假设某物理网络中共有10个顾客节点,编号为1~10,一个车辆基地,编号为0,在满足车辆容量约束与顾客节点需求约束的条件下,此问题的一个可行解可表示为:[0-1-2-0,0-3-4-5-0,0-6-7-8-0,0-9-10-0],即需要4个车辆来提供服务,车辆的行驶路线分别为0-1-2-0,0-3-4-5-0,0-6-7-8-0,0-9-10-0。
由于车辆的容量固定,基地固定,因此可以将上述问题的解先表示为[1-2-3-4-5-6-7-8-9-10]的有序序列,然后根据车辆的容量约束,对序列进行切割得到若干车辆的行驶路线。因此可以将CVRP问题转换为TSP问题进行求解,得到TSP问题的优化解后再考虑车辆容量约束进行路径切割,得到CVRP问题的解。这样的处理方式可能会影响CVRP问题解的质量,但简化了问题的求解难度。
3. 数据格式
以xlsx文件储存网络数据,其中第一行为标题栏,第二行存放车辆基地数据。在程序中车辆基地seq_no编号为-1,需求节点seq_id从0开始编号。可参考github主页相关文件。
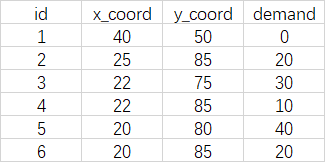
4. 分步实现
(1)数据结构
为便于数据处理,定义Sol()类,Node()类,Model()类,其属性如下表:
- Sol()类,表示一个可行解
| 属性 | 描述 |
|---|---|
| nodes_seq | 需求节点seq_no有序排列集合,对应TSP的解 |
| obj | 优化目标值 |
| routes | 车辆路径集合,对应CVRP的解 |
- Node()类,表示一个网络节点
| 属性 | 描述 |
|---|---|
| id | 物理节点id,可选 |
| name | 物理节点名称,可选 |
| seq_no | 物理节点映射id,基地节点为-1,需求节点从0编号 |
| x_coord | 物理节点x坐标 |
| y_coord | 物理节点y坐标 |
| demand | 物理节点需求 |
- Model()类,存储算法参数
| 属性 | 描述 |
|---|---|
| best_sol | 全局最优解,值类型为Sol() |
| node_list | 物理节点集合,值类型为Node() |
| node_seq_no_list | 物理节点映射id集合 |
| depot | 车辆基地,值类型为Node() |
| number_of_nodes | 需求节点数量 |
| opt_type | 优化目标类型,0:最小车辆数,1:最小行驶距离 |
| vehicle_cap | 车辆容量 |
| popsize | 蚁群规模 |
| alpha | 信息启发式因子 |
| beta | 期望启发式因子 |
| Q | 信息素总量 |
| rho | 信息素挥发系数 |
| tau | 网络弧信息素 |
(2)文件读取
def readXlsxFile(filepath,model):
node_seq_no = -1
df = pd.read_excel(filepath)
for i in range(df.shape[0]):
node=Node()
node.id=node_seq_no
node.seq_no=node_seq_no
node.x_coord= df['x_coord'][i]
node.y_coord= df['y_coord'][i]
node.demand=df['demand'][i]
if df['demand'][i] == 0:
model.depot=node
else:
model.node_list.append(node)
model.node_seq_no_list.append(node_seq_no)
try:
node.name=df['name'][i]
except:
pass
try:
node.id=df['id'][i]
except:
pass
node_seq_no=node_seq_no+1
model.number_of_nodes=len(model.node_list)
(3)初始化参数
在初始化参数时计算网络弧距离,同时对网络弧上的信息素浓度进行初始化,这里默认为10,也可取其他值。
def initParam(model):
for i in range(model.number_of_nodes):
for j in range(i+1,model.number_of_nodes):
d=math.sqrt((model.node_list[i].x_coord-model.node_list[j].x_coord)**2+
(model.node_list[i].y_coord-model.node_list[j].y_coord)**2)
model.distance[i,j]=d
model.distance[j,i]=d
model.tau[i,j]=10
model.tau[j,i]=10
(4)位置更新
在更新蚂蚁位置时,调用 " searchNextNode "函数,依据网络弧信息素浓度及启发式信息搜索蚂蚁下一个可能访问的节点。
def movePosition(model):
sol_list=[]
local_sol=Sol()
local_sol.obj=float('inf')
for k in range(model.popsize):
#Random ant position
nodes_seq=[int(random.randint(0,model.number_of_nodes-1))]
all_nodes_seq=copy.deepcopy(model.node_seq_no_list)
all_nodes_seq.remove(nodes_seq[-1])
#Determine the next moving position according to pheromone
while len(all_nodes_seq)>0:
next_node_no=searchNextNode(model,nodes_seq[-1],all_nodes_seq)
nodes_seq.append(next_node_no)
all_nodes_seq.remove(next_node_no)
sol=Sol()
sol.nodes_seq=nodes_seq
sol.obj,sol.routes=calObj(nodes_seq,model)
sol_list.append(sol)
if sol.obj<local_sol.obj:
local_sol=copy.deepcopy(sol)
model.sol_list=copy.deepcopy(sol_list)
if local_sol.obj<model.best_sol.obj:
model.best_sol=copy.deepcopy(local_sol)
def searchNextNode(model,current_node_no,SE_List):
prob=np.zeros(len(SE_List))
for i,node_no in enumerate(SE_List):
eta=1/model.distance[current_node_no,node_no]
tau=model.tau[current_node_no,node_no]
prob[i]=((eta**model.alpha)*(tau**model.beta))
#use Roulette to determine the next node
cumsumprob=(prob/sum(prob)).cumsum()
cumsumprob -= np.random.rand()
next_node_no= SE_List[list(cumsumprob > 0).index(True)]
return next_node_no
(5)信息素更新
这里采用蚁周模型对网络弧信息素进行更新,在具体更新时可根据可行解的nodes_seq属性(TSP问题的解)对所经过的网络弧信息素进行更新;也可根据可行解的routes属性(CVRP问题的解)对所经过的网络弧信息素进行更新。
def upateTau(model):
rho=model.rho
for k in model.tau.keys():
model.tau[k]=(1-rho)*model.tau[k]
#update tau according to sol.nodes_seq(solution of TSP)
for sol in model.sol_list:
nodes_seq=sol.nodes_seq
for i in range(len(nodes_seq)-1):
from_node_no=nodes_seq[i]
to_node_no=nodes_seq[i+1]
model.tau[from_node_no,to_node_no]+=model.Q/sol.obj
#update tau according to sol.routes(solution of CVRP)
# for sol in model.sol_list:
# routes=sol.routes
# for route in routes:
# for i in range(len(route)-1):
# from_node_no=route[i]
# to_node_no=route[i+1]
# model.tau[from_node_no,to_node_no]+=model.Q/sol.obj
(6)目标值计算
目标值计算依赖 " splitRoutes " 函数对TSP可行解分割得到车辆行驶路线和所需车辆数, " calDistance " 函数计算行驶距离。
def splitRoutes(nodes_seq,model):
num_vehicle = 0
vehicle_routes = []
route = []
remained_cap = model.vehicle_cap
for node_no in nodes_seq:
if remained_cap - model.node_list[node_no].demand >= 0:
route.append(node_no)
remained_cap = remained_cap - model.node_list[node_no].demand
else:
vehicle_routes.append(route)
route = [node_no]
num_vehicle = num_vehicle + 1
remained_cap =model.vehicle_cap - model.node_list[node_no].demand
vehicle_routes.append(route)
return num_vehicle,vehicle_routes
def calDistance(route,model):
distance=0
depot=model.depot
for i in range(len(route)-1):
from_node=model.node_list[route[i]]
to_node=model.node_list[route[i+1]]
distance+=math.sqrt((from_node.x_coord-to_node.x_coord)**2+(from_node.y_coord-to_node.y_coord)**2)
first_node=model.node_list[route[0]]
last_node=model.node_list[route[-1]]
distance+=math.sqrt((depot.x_coord-first_node.x_coord)**2+(depot.y_coord-first_node.y_coord)**2)
distance+=math.sqrt((depot.x_coord-last_node.x_coord)**2+(depot.y_coord - last_node.y_coord)**2)
return distance
def calObj(nodes_seq,model):
num_vehicle, vehicle_routes = splitRoutes(nodes_seq, model)
if model.opt_type==0:
return num_vehicle,vehicle_routes
else:
distance=0
for route in vehicle_routes:
distance+=calDistance(route,model)
return distance,vehicle_routes
(7)绘制收敛曲线
def plotObj(obj_list):
plt.rcParams['font.sans-serif'] = ['SimHei'] #show chinese
plt.rcParams['axes.unicode_minus'] = False # Show minus sign
plt.plot(np.arange(1,len(obj_list)+1),obj_list)
plt.xlabel('Iterations')
plt.ylabel('Obj Value')
plt.grid()
plt.xlim(1,len(obj_list)+1)
plt.show()
(8)输出结果
def outPut(model):
work=xlsxwriter.Workbook('result.xlsx')
worksheet=work.add_worksheet()
worksheet.write(0,0,'opt_type')
worksheet.write(1,0,'obj')
if model.opt_type==0:
worksheet.write(0,1,'number of vehicles')
else:
worksheet.write(0, 1, 'drive distance of vehicles')
worksheet.write(1,1,model.best_sol.obj)
for row,route in enumerate(model.best_sol.routes):
worksheet.write(row+2,0,'v'+str(row+1))
r=[str(i)for i in route]
worksheet.write(row+2,1, '-'.join(r))
work.close()
(9)主函数
def run(filepath,Q,alpha,beta,rho,epochs,v_cap,opt_type,popsize):
"""
:param filepath:Xlsx file path
:param Q:Total pheromone
:param alpha:Information heuristic factor
:param beta:Expected heuristic factor
:param rho:Information volatilization factor
:param epochs:Iterations
:param v_cap:Vehicle capacity
:param opt_type:Optimization type:0:Minimize the number of vehicles,1:Minimize travel distance
:param popsize:Population size
:return:
"""
model=Model()
model.vehicle_cap=v_cap
model.opt_type=opt_type
model.alpha=alpha
model.beta=beta
model.Q=Q
model.rho=rho
model.popsize=popsize
sol=Sol()
sol.obj=float('inf')
model.best_sol=sol
history_best_obj = []
readXlsxFile(filepath,model)
initParam(model)
for ep in range(epochs):
movePosition(model)
upateTau(model)
history_best_obj.append(model.best_sol.obj)
print("%s/%s, best obj: %s" % (ep,epochs, model.best_sol.obj))
plotObj(history_best_obj)
outPut(model)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)