
CNN+Transformer算法总结(持续更新)
CNN与Transformer融合的视觉框架介绍
系列文章目录
本文总结了2021年以来,所有将CNN与Transformer框架结合的CV算法
如有疑问与补充,欢迎评论
CNN+Transformer系列算法
前言
在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但在捕获全局特征表示方面还是有一定的局限性。在Vision Transformer中,级联自注意力模块可以捕获长距离的特征依赖,但会忽略局部特征的细节。
提示:以下是本篇文章正文内容,下面案例可供参考
在图像分类、目标检测和实例分割等计算机视觉任务中,CNN具有非常良好的性能。这在很大程度上归因于卷积操作,它以分层的方式收集局部特征以获得更好的图像表示。尽管在局部特征提取方面具有优势,但CNN捕获全局表示的能力还是不足,这对很多high-level的计算机视觉任务又是非常重要的。一个最直观的解决方案是扩大感受野,但是这就会破坏池化层的操作。
最近Transformer结构被用到了视觉任务中,ViT方法通过将每个图像分割为具有位置嵌入的Patch来构建一系列token,然后用Transformer Block来提取参数化向量作为视觉表示。由于自注意力机制(Self-Attention)和多层感知机(MLP)结构,Vision Transformer能够反映了复杂的空间变换和长距离特征依赖性,从而获得全局特征表示。然而,Vision Transformer会忽略了局部特征细节,这降低了背景和前景之间的可辨别性(如上图©和(g)所示)。因此,一些工作提出了一个tokenization模块或利用CNN特征图作为输入token来捕获特征的邻近信息。然而,这些方法依旧没有从根本上解决好局部建模和全局建模之间的关系。
一、Conformer(国科大&华为&鹏城)
本文提出了一种混合网络结构,称为Conformer,将(卷积操作)和(自注意力机制)结合增强特征表示的学习。Conformer依靠特征耦合单元(FCU),以交互的方式在不同分辨率下融合局部特征表示和全局特征表示。此外,Conformer采用并行结构,以最大限度地保留局部特征和全局表示。
作者通过实验证明,在相似的参数和复杂度下,Conformer在ImageNet上比DeiT-B好2.3%。在MS-COCO数据集上,它在目标检测和实例分割任务上,分别比ResNet-101高出3.7%和3.6%的mAP。
论文地址:https://arxiv.org/abs/2105.03889
代码地址:https://github.com/pengzhiliang/Conformer
1.框架概述
双网络结构Conformer,能够将基于CNN的局部特征与基于Transformer的全局表示相结合,以增强表示学习。Conformer由一个CNN分支和一个Transformer分支组成,这两个分支由局部卷积块、自我注意模块和MLP单元的组合而成。在训练过程中,交叉熵损失函数被用于监督CNN和Transformer两个分支的训练,以获得同时具备CNN风格和Transformer风格的特征。
考虑到CNN与Vision Transformer特征之间的不对称性,作者设计了特性耦合单元(FCU)作为CNN与Vision Transformer 之间的桥接。一方面,为了融合两种风格的特征,FCU利用1×1卷积对齐通道尺寸,用下/上采样策略对齐特征分辨率,用LayerNorm和BatchNorm对齐特征值 。另一方面,由于CNN和Vision Transformer分支倾向于捕获不同级别的特征(局部和全局),因此将FCU插入到每个block中,以 连续 交互的方式消除它们之间的语义差异 。这种融合过程可以极大地提高局部特征的全局感知能力和全局表示的局部细节。

从上图可以看出,Conformer每个分支的特征表示都比单独使用CNN或者单独使用Transformer结构的特征表示要更好。传统的CNN倾向于保留可区分的局部区域,而Conformer的CNN分支还可以激活完整的物体范围。Vision Transformer的特征很难区分物体和背景,Conformer的分支对局部细节信息的捕获更好。
2.方法
局部特征和全局特征在计算机视觉任务中得到了广泛的研究。局部特征是局部图像邻域的紧凑向量表示,一直是许多计算机视觉算法的组成部分。全局表示包括轮廓表示、形状描述符和长距离上的对象表示等等。在深度学习中,CNN通过卷积操作分层收集局部特征,并保留局部线索作为特征。Vision Transformer被认为可以通过级联的Self-Attention模块以一种soft的方式在压缩的patch embedding之间聚合全局表示。
为了利用局部特征和全局表示,作者设计了一个并发网络的结构Conformer,如上图(c)所示。考虑两种特征的互补性,作者将来自Vision Transformer分支的全局特征送入CNN中,以增强CNN分支的全局感知能力。类似的,将来自CNN分支的局部特征送入到Vision Transformer中,以增强Vision Transformer分支的局部感知能力。这样的过程构成了interaction的作用。

具体实现上,Conformer由一个stem模块、双分支、桥接双分支的FCU和每个分支上的分类器(FC)组成。Stem模块是一个步长为2的7×7卷积和步长为2的3×3 max pooling,用于提取初始局部特征,然后分别送入到两个分支中。CNN分支和Transformer分支分别由N个重复卷积和Transformer块组成(具体设置如上表所示)。这种并发结构意味着CNN和Transformer分支分别可以最大限度地保留局部特征和全局表示。FCU被提出作为一个桥接模块,将CNN分支的局部特征与Transformer分支的全局表示融合,如上图(b)所示。沿着这些分支结构,FCU会以交互式的方式逐步融合feature map和patch embedding。
最后,对于CNN分支,所有的特征被合并之后输入给一个分类器。对于Transformer分支,取出[cls] token之后送入给另一个分类器进行分类。在训练过程中,作者使用两个交叉熵损失来分别监督这两个分类器。损失函数的重要性权重被设置为是相同的。在推理过程中,作者将这两个分类器的输出简单地相加作为预测结果。

3.CNN分支
如上图(b)所示,CNN分支采用特征金字塔结构,其中特征图的分辨率随着网络深度的增加而降低,而通道数随着网络深度的增加而增加。作者将整个CNN分支分为4个阶段(如上表所示)。每个阶段由多个卷积块组成,每个卷积块包含个bottleneck。在实验中,在第一个卷积块中被设置为1,并在随后的N−1卷积块中设置为。
Vision Transformer通过一个简单的patch embedding步骤将一个图像patch投影到一个特征向量中,导致局部细节的丢失。而在CNN中,卷积核在具有重叠的特征映射上滑动,最大程度的保留了局部特征。因此,CNN分支能够连续地为Transformer分支提供局部的特征细节。
代码如下(示例):
代码如下(示例):
4.Transformer分支
代码如下(示例):在Transformer分支中,包含N个重复的Transformer块。从上图(b)可以看出,每个Transformer块由一个Multi-head Self-Attention模块和一个MLP模块组成,在每一层的Self-Attention层和MLP块都用了LayerNorm进行归一化。为了tokenization,作者将CNN中的stem模块生成的特征映射压缩为14×14的无重叠的patch embedding(通过一个步长为4的4x4卷积),然后在加入一个[cls] token用于分类。由于CNN分支(3×3卷积)同时编码局部特征和空间位置信息,这里就不再需要position encoding。
5.FCU单元(Feature Coupling Unit
示例:给定CNN分支中的特性映射和Transformer分支中的patch embedding,如何消除它们之间的特征错位 是一个重要的问题。
为了解决这个问题,作者提出了FCU以交互式的方式连续地结合局部特征和全局表示。
一方面,作者认识到CNN和Transformer的特征维度是不一致的。CNN特征的维度是C×H×W(C、H、W分别为通道、高度和宽度),但是Transformer的patch embedding维度是(K + 1) × E(K、1和E分别表示图像patch的数量、[cls] token的数量和embedding维度)。当输入给Transformer分支时,首先需要通过1×1卷积来对齐通道维度,然后进行下采样(如上图(a)所示)。当从Transformer分支送入到CNN分支时,也是需要通过1×1卷积来对齐通道维度,进行上采样(如上图(a)所示)。此外LayerNorm和BatchNorm用于归一化特征。
另一方面,CNN特征和Patch Embedding之间存在显著的语义差距,因为CNN特征映射通过局部卷积运算得到,而Patch Embedding则是通过全局自注意力机制进行聚合的。因此,FCU应用于每个block中以逐步填补语义信息的差距。
6.实验结果
1.Image Classification
如表所示,在类似的参数量和计算量下,Conformer的性能均优于CNN和Vision Transformer。

2.目标检测与分割。
如表所示,Conformer显著提高了和。

3.参数量
表展示了不同参数量下的性能。可以看出,通过增加CNN或Vision Transformer分支的参数量,可以提高精度。

4.位置编码Positional Embeddings
当去除Positional Embedding时,DeiT-S的精度降低了2.4%,而Conformer-S的精度略有下降。

5:采样策略

展示了不同的上/下采样策略,包括max-pooling、mean-pooling、卷积和基于注意力采样的结果。
6.全体模型比较。
如图所示,CNN支路、Transformer支路、Conformer-S的精度分别达到83.3%、83.1%和83.4%。而CNN和Transformer集成模型的精度也只有81.8%。

7.总结
示例:在本文中,作者提出了第一个将CNN与Vision Transformer相结合的双主干网络Conformer。在Conformer中,作者利用卷积算子来提取局部特征、利用自注意力机制来捕获全局表示。此外,作者设计了特征耦合单元(FCU)来融合局部特征和全局表示,以交互的方式增强了视觉表示的能力。实验表明,Conformer在相似的参数和计算量下,优于传统的CNN和Vision Transformer。在各种下游任务中,Conformer也展现出了成为一个简单而有效的主干网络的巨大潜力。
二、Mobile-Former(微软)
MobileNet和Transformer的并行设计,可以实现局部和全局特征的双向融合,在分类和下游任务中,性能远超MobileNetV3等轻量级网络
1.梗概
代码如下(示例):
作者将设计范式从串联向并联转变,提出了一种新的MobileNet和Transformer并行化,并在两者之间建立双向桥接(见图)。其中Mobile指MobileNet, Former指transformer。Mobile以图像为输入堆叠mobile block(或inverted bottleneck)。它利用高效的depthwise和pointwise卷积来提取像素级的局部特征。前者以一些可学习的token作为输入,叠加multi-head attention和前馈网络(FFN)。这些token用于对图像的全局特征进行编码。

Mobile-Former是MobileNet和Transformer的并行设计,中间有一个双向桥接。这种结构利用了MobileNet在局部处理和Transformer在全局交互方面的优势。并且该桥接可以实现局部和全局特征的双向融合。与最近在视觉Transformer上的工作不同,Mobile-Former中的Transformer包含非常少的随机初始化的token(例如少于6个token),从而导致计算成本低。

结合提出的轻量级交叉注意力对桥接进行建模,Mobile-Former不仅计算效率高,而且具有更强的表示能力,在ImageNet分类上从25M到500MFLOPs的低 FLOPs机制下优于MobileNetV3。例如,它在294M FLOPs下实现了77.9%的top-1准确率,比MobileNetV3提高了1.3%,但节省了17%的计算量。在转移到目标检测时,Mobile-Former 比MobileNetV3高8.6 AP。
2.MobileNet3
mobilenet提出了一种在inverted bottleneck结构中使用depthwise和pointwise卷积对局部处理建模的有效方法。使用group卷积和channel shuffle来简化pointwise卷积的shuffle。此外,MicroNet提出了micro-factorized 卷积,优化了inverted bottleneck和group卷积的组合,在极低的FLOPs下实现了可靠的性能。其他有效的操作包括傅里叶变换、GhostNet中的线性变换,以及在AdderNet中使用廉价的加法替代大规模乘法。此外,还研究了不同的体系结构。MixConv探索了混合多个核大小,Sandglass inverted residual block的结构。EfficientNet和TinyNet研究深度、宽度和分辨率的复合缩放。
3. Vision Transformers
最近,ViT及其后续在多个视觉任务上取得了令人印象深刻的表现。原始的ViT需要在大型数据集(如JFT-300M)上进行训练才能表现良好。后来,DeiT通过引入几个重要的训练策略,证明了在较小的ImageNet-1K数据集上可以获得良好的性能。为实现高分辨率图像的ViT,提出了几种分层Transformer。
例如,Swin提出了在局部窗口内计算自注意力的移位窗口方法,CSWin通过引入十字形窗口自注意力进一步改进了该方法。T2T-ViT通过递归聚合相邻的token逐步将图像转换为token从而可以很好地建模局部结构。HaloNet开发了两种注意力扩展(blocked local attention和attention downsampling)从而提高了速度、内存使用以及准确性。
4.CNNs与ViT结合
近研究结果表明,卷积与Transformer相结合在预测精度和训练稳定性上都有提高。
通过在ResNet的最后3个bottleneck block中使用全局自注意力替换空间卷积,BoTNet在实例分割和目标检测方面有了显著的改进。
通过引入门控位置自注意力(GPSA),ConViT通过soft卷积归纳偏差改进了ViT。
CvT在每个multi-head attention之前引入了depthwise/pointwise卷积。
LeViT和ViTC使用convolutional stem (stacking convolutions)代替patchify stem。LeViT和ViTC在低FLOP状态下有明显改善。在本文中作者提出了一个不同的设计,并行MobileNet和Transformer之间的双向交叉注意力。本文的方法既高效又有效,在低FLOP状态下优于高效CNN和ViT变种。
Mobile-Former将MobileNet和transformer并行化,并通过双向交叉注意力将两者连接起来(见图1)。Mobile-former中,Mobile(简称MobileNet)以一幅图像作为输入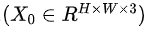
,采用inverted bottleneck block提取局部特征。前者(指transformer)以可学习参数(或token)作为输入,记为Z0∈R(M*D),其中d和M分别为token的维数和数量。这些token被随机初始化,每个token表示图像的全局先验。这与Vision Transformer(ViT)不同,在ViT中,token线性地投射局部图像patch。这种差异非常重要,因为它显著减少了token的数量从而产生了高效的Former。
5.低消耗的双向桥
作者利用cross attention的优势融合局部特性(来自Mobile)和全局token(来自Former)。这里为了降低计算成本介绍了2个标准cross attention计算:


6.Mobile-Former Block
Mobile-Former可以解耦为Mobile-Former块的堆栈(见图1)。每个块包括Mobile sub-block、Former sub-block和双向桥接(MobileFormer和MobileFormer)。Mobile-Former块的细节如图3所示。



6 计算复杂度
Mobile-Former块的4个支柱有不同的计算成本。Mobile sub-block消耗的计算量最多(O(2LEC^2 + 9LEC)),它与空间位置数L呈线性增长,与局部特征c中通道数呈二次增长。Former sub-block和双向Bridge具有较高的计算效率,消耗小于所有Mobile-Former模型总计算量的20%。

7.架构
表1显示了在294M FLOPs上的Mobile-Former架构,它以不同的输入分辨率堆叠11个Mobile-Former块。所有Mobile-Former区块都有6个维度为192的全局token。它以3x3卷积作为stem开始,随后是lite bottleneck block在stage-1。lite bottleneck block使用3x3深度卷积来扩展channel数量,并使用pointwise卷积来压缩channel数量。分类head对局部特征应用平均池化,与第一个全局token连接,然后通过2个完全连接的层(层之间使用h-swish)。

staget 2-5有一个Mobile-Former块的downsample变体(表示为Mobile-Former)来处理空间下采样。在Mobile-former中,只有Mobile sub block中的卷积层从3层(点向!深度向!点向)改变为4层(pointwise->depth->pointwise),其中第一个深度卷积层有stride=2。channel的数量在每个深度卷积中扩展,并压缩在接下来的pointwise卷积中。这节省了计算,因为2个代价高昂的pointwise卷积在下采样后以较低的分辨率执行。
8.Mobile-Former 变体
Mobile-Former有7个不同计算成本的模型,从26M到508M FLOPs。它们的结构相似,但宽度和高度不同。作者遵循[36]来引用我们的模型的FLOPs,例如Mobile-Former-294M, Mobile-Former-96M。这些Mobile-Former模型的网络架构细节如下表。

9.可解释性
为了理解Mobile和Former之间的协作,作者将cross attention形象化在双向桥上(Mobile->Former和Mobile,<-Former)(见图4、5、6)。使用ImageNet预训练的MobileFormer-294M,其中包括6个全局token和11个Mobile-Former块。作者观察到3种有趣的现象:
第1点:
lower level token的注意力比higher level token更多样化。如图4所示,每一列对应一个token,每一行对应相应的多头交叉注意中的一个头。注意,在Mobile->Former(左半部分)中,注意力是在像素上标准化的,显示每个token的聚焦区域。相比之下,Mobile<-Former中的注意力是在token上标准化的,比较不同token在每个像素上的贡献。显然,第3和第5区块的6个token在Mobile->Former和Mobile<-Former中都有不同的cross attention模式。在第8块中可以清楚地观察到token之间类似的注意力模式。在第12区块,最后5个token的注意力模式非常相似。注意,第1个token是进入分类器头部的class token。最近关于ViT的研究也发现了类似的现象。

第2点:
全局token的重点区域从低到高级别逐渐变化。图5显示了MobileFormer中第1个token的像素交叉注意力。这个token开始关注局部特性,例如边缘/角(在第2-4块)。然后对像素连通区域进行了更多的关注。有趣的是,聚焦区域在前景(人和马)和背景(草)之间转换。最后,定位识别度最高的区域(马身和马头)进行分类。

第3点:
Mobile<—Former的中间层(例如第8块)出现了前景和背景的分离。图6显示了特征图中每个像素在6个token上的cross attention。显然,前景和背景被第一个token和最后一个token分开。这表明,一些全局token学习有意义的原型,聚类相似的像素。

局限性与实验
Mobile-Former的主要限制是模型大小。这有2个原因:
首先,由于Mobile,Former和bridge都有各自的参数,因此并行设计在参数共享方面效率不高;虽然Former由于token数量少,计算效率高,但它并不节省参数的数量。
其次,在执行ImageNet分类任务时,Mobile-Former在分类头(2个全连接层)中消耗了很多参数。例如,Mobile-Former-294M在分类头中花费了40% (11.4M中的4.6M)参数。当从图像分类切换到目标检测任务时,由于去掉了分类头,模型大小问题得到了缓解。


目标检测

三、CMT(华为诺亚&悉尼大学)
MobileNet和Transformer的并行设计,可以实现局部和全局特征的双向融合,在分类和下游任务中,性能远超MobileNetV3等轻量级网络
论文:https://arxiv.org/abs/2106.14881
1.梗概与总体结构
做法总结如下:
1.提出混合模型(串行),通过利用Transformers来捕捉长距离的依赖关系,并利用CNN来获取局部特征。
2.引入depth-wise卷积,获取局部特征的同时,减少计算量
3.使用类似R50模型结构一样的stageblock,使得模型具有下采样增强感受野和迁移dense的能力。
4.使用conv-stem来使得图像的分辨率缩放从VIT的1/16变为1/4,保留更多的patch信息。

(a)表示的是标准的R50模型,具有4个stage,每个都会进行一次下采样。最后得到特征表达后,经过AvgPool进行分类
(b)表示的是标准的VIT模型,先进行patch的划分,然后embeeding后进入Transformer的block,这里,由于Transformer是long range的,所以进入什么,输出就是什么,引入了一个非image的class token来做分类。
©表示的是本文所提出的模型框架CMT,由CMT-stem, downsampling, cmt block所组成,整体结构则是类似于R50,所以可以很好的迁移到dense任务上去。
2.CMT Stem
使用convolution来作为transformer结构的stem,这个观点FB也有提出一篇paper,Early Convolutions Help Transformers See Better。
CMT&Conv stem共性
1.使用4层conv3x3+stride2 + conv1x1 stride 1 等价于VIT的patch embeeding,conv16x16 stride 16.
2.使用conv stem,可以使模型得到更好的收敛,同时,可以使用SGD优化器来训练模型,对于超参数的依赖没有原始的那么敏感。好处那是大大的多啊,仅仅是改了一个conv stem。
CMT&Conv stem异性
本文仅仅做了一次conv3x3 stride2,实际上只有一次下采样,相比conv stem,可以保留更多的patch的信息到下层。
3.CMT Block
每一个stage都是由CMT block所堆叠而成的,CMT block由于是transformer结构,所以没有在stage里面去设计下采样。每个CMT block都是由Local Perception Unit, Ligntweight MHSA, Inverted Residual FFN这三个模块所组成的,下面分别介绍:
Local Perception Unit(LPU)

本文的一个核心点是希望模型具有long-range的能力,同时还要具有local特征的能力,所以提出了LPU这个模块,很简单,一个3X3的DWconv,来做局部特征,同时减少点计算量,为了让Transformers的模块获取的longrange的信息不缺失,这里做了一个shortcut,公式描述为:

Lightweight MHSA(LMHSA)


Inverted Resdiual FFN(IRFFN)

FFN的这个模块,其实和mbv2的block基本上就是一样的了,不一样的地方在于,使用的是GELU,采用的也是DW+PW来减少标准卷积的计算量。很简单,就不多说了,公式如下:

4.patch aggregation
每个stage都是由上述的多个CMTblock所堆叠而成, 上面也提到了,这里由于是transformer的操作,不会设计到scale尺度的问题,但是模型需要构造下采样,来实现层次结构,所以downsampling的操作单独拎了出来,每个stage之前会做一次卷积核为2x2的,stride为2的卷积操作,以达到下采样的效果。
所以,整体的模型结构就一目了然了,假设输入为224x224x3,经过CMT-STEM和第一次下采样后,得到了一个56x56的featuremap,然后进入stage1,输出不变,经过下采样后,输入为28x28,进入stage2,输出后经过下采样,输入为14x14,进入stage3,输出后经过最后的下采样,输入为7x7,进入stage4,最后输出7x7的特征图,后面接avgpool和分类,达到分类的效果。
5.实验
paper里面采用的Position Embeeding和Swin是类似的,都是Relation Position Bias,但是和Swin不相同的是,我们的Q,K,V尺度是不一样的。这里我考虑了两种实现方法,一种是直接bicubic插值,另一种则是切片,切片更加直观且embeeding我设置的可BP,所以,实现里面采用的是这种方法。
在SGD优化器的情况下,使用1.6的LR,训练300个epoch,warmup5个epoch,是用cosine衰减学习率的策略,用randaug+colorjitter+mixup+cutmix+labelsmooth,设置weightdecay为0.1的配置下,使用QKV的bias以及相对位置偏差,可以达到比baseline高11%个点的结果,所有的实验都是用FP16跑的。
使用AdamW的情况下,对学习率的缩放则是以512的bs为基础,所以对于4k的bs情况下,使用的是4e-3的LR,但是实验发现增大到6e-3的时候,还会带来一些提升,同时放大一点weightsdecay,也略微有所提升,最终使用AdamW的配置为,6e-3的LR,1e-1的weightdecay,和sgd一样的增强方法,然后加上了随机深度失活设置,最后比baseline高了16%个点,比SGD最好的结果要高0.8%个点。
ImageNet效果:

coco2017

6.总结
本文提出了一种名为CMT的新型混合架构,用于视觉识别和其他下游视觉任务,以解决在计算机视觉领域以粗暴的方式利用Transformers的限制。所提出的CMT同时利用CNN和Transformers的优势来捕捉局部和全局信息,促进网络的表示能力。在ImageNet和其他下游视觉任务上进行的大量实验证明了所提出的CMT架构的有效性和优越性。
本文亮点总结
1.CMT&Conv stem共性:
使用4层conv3x3+stride2 + conv1x1 stride 1 等价于VIT的patch embeeding,conv16x16 stride 16.
使用conv stem,可以使模型得到更好的收敛,同时,可以使用SGD优化器来训练模型,对于超参数的依赖没有原始的那么敏感。好处那是大大的多啊,仅仅是改了一个conv stem。
2.本文的一个核心点是希望模型具有long-range的能力,同时还要具有local特征的能力,所以提出了LPU这个模块,很简单,一个3X3的DWconv,来做局部特征,同时减少点计算量。
代码复现repo:
https://github.com/FlyEgle/CMT-pytorch
四、CoTNet(京东AI:Res变体)
本文(Contextual Transformer Networks for visual recognition )创造性的将Transformer中的自注意力机制的动态上下文信息聚合与卷积的静态上下文信息聚合进行了集成,提出了一种新颖的Transformer风格的“即插即用”CoT模块,它可以直接替换现有ResNet架构Bottleneck中的3✖️3卷积并取得显著的性能提升。
paper: https://arxiv.org/abs/2107.12292
code: https://github.com/JDAI-CV/CoTNet
1.梗概
本文是京东AI研究院梅涛团队在自注意力机制方面的探索,不同于现有注意力机制仅采用局部或者全局方式进行上下文信息获取,他们创造性的将Transformer中的自注意力机制的动态上下文信息聚合与卷积的静态上下文信息聚合进行了集成,提出了一种新颖的Transformer风格的“即插即用”CoT模块,它可以直接替换现有ResNet架构Bottleneck中的3x3卷积并取得显著的性能提升。无论是ImageNet分类,还是COCO检测与分割,所提CoTNet架构均取得了显著性能提升且参数量与FLOPs保持同水平。比如,相比EfficientNet-B6的84.3%,所提SE-CoTNetD-152取得了84.6%同时具有快2.75倍的推理速度。
Transformer极大的促进了NLP领域的发展,Transformer风格的网络架构近期在CV领域也掀起了一波浪潮并取得了极具竞争力的结果。尽管如此,现有的架构直接在2D特征图上执行自注意力并得到注意力矩阵,但是关于近邻丰富的上下文信息却并未得到充分探索。
本文设计了一种新颖的Transformer风格模块CoT(Contextual Transformer, CoT)用于视觉识别,该设计充分利用输入的上下文信息并引导动态注意力矩阵的学习,进而提升了视觉表达能力。技术上来讲,CoT模块首先通过卷积对输入keys进行上下文信息编码得到关于输入的静态上下文表达;进一步将编码keys与输入query进行拼接并通过两个连续卷积学习动态多头注意力矩阵;所得注意力矩阵与输入values相乘即可得到关于输入的动态上下文表达。静态上下文表达与动态上下文表达的融合结果作为该模块的输出。所提CoT模块可以作为“即插即用”模块替换ResNet中的卷积并得到Transformer风格的架构,故而称之为CoTNet(Contextual Transformer Network)。
多个领域(包含图像分类、目标检测、实例分割)的充分实验结果表明:CoTNet是一种更强的骨干网络。比如,在ImageNet分类任务中,相比ResNeSt101,CoTNet取得了0.9%的性能提升;在COCO目标检测与实例分割任务中,相比ResNeSt,CoT分别取得了1.5%与0.7%mAP指标提升。
2.多头注意力 in Vision Backbones


3.Contextual Transformer Block
传统的自注意力仅在空域进行信息交互,依赖于输入自身,即相关性通过独立的方式学习所得,而忽视了近邻间丰富的上下文信息。这无疑会严重限制2D特征图的自注意力学习能力。为缓解该问题,我们构建了一种新的Transformer风格的模块CoT(见上面的Figure2-b),它将上下文信息挖掘与自注意力学习集成到统一架构中。本文的出发点:充分探索近邻间的上下文信息以一种高效方式提升自注意力学习,进而提升输出特征的表达能力。
4.Contextual Transformer Networks
所提CoT的设计是一种统一的注意力模块,它可以作为ConvNet中标准卷积的替代。因此,我们可以将其替换现有ConvNet中的卷积进而提升其表达能力。
接下来,我们简要介绍一下如何将CoT模块嵌入到现有ResNet架构中且不会显著提升参数量。下表给出了将CoT模块嵌入到ResNet与ResNeXt中的信息示意,并将所得模型称之为CoTNet-50、CoTNeXt-50。当然,还可以将CoT模块嵌入到ResNet101中,更详细的嵌入方式可参考官方code。
5.实验
本文是京东AI研究院梅涛团队在自注意力机制方面的探索,不同于现有注意力机制仅采用局部
这里写自定义目录标题
五、ViTDet(何恺明团队:2022.04)
创新点主要为:去掉了检测的PFN部分,直接用一种尺度特征图,通过上下采样,得到四种尺度特征图(如下图)。该网络训练硬件要求较大,吃显存
paper: https://arxiv.org/abs/2203.16527
《Exploring Plain Vision Transformer Backbones for Object Detection》
code: https://github.com/已开源
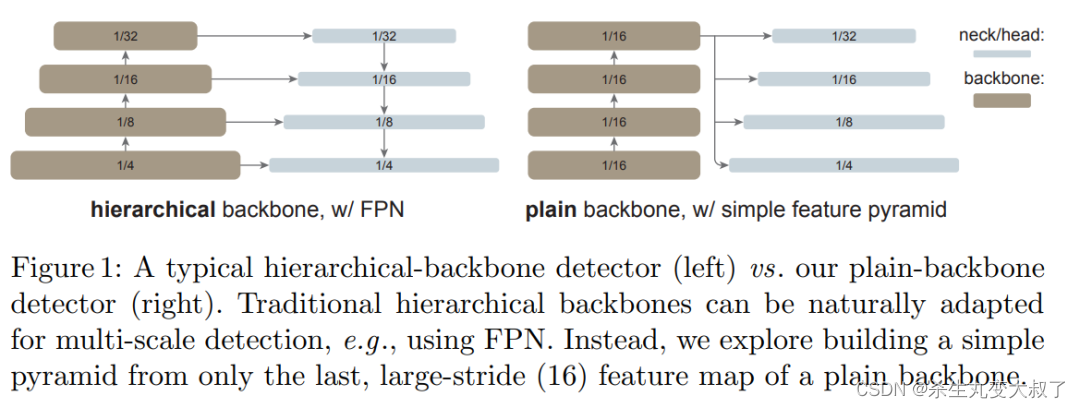
backbone共分为三阶段,前两个阶段主要用简单的CNN与Transformer融合,最后阶段几乎全部为深层的swin transformer,去掉了window shift操作。为了允许信息传播,该研究使用了极少数(默认为 4 个)可跨窗口的块。研究者将预训练的主干网络平均分成 4 个块的子集(例如对于 24 块的 ViT-L,每个子集中包含 6 个),并在每个子集的最后一个块中应用传播策略。研究者分析了如下两种策略:
全局传播。该策略在每个子集的最后一个块中执行全局自注意力。由于全局块的数量很少,内存和计算成本是可行的。这类似于(Li et al., 2021 )中与 FPN 联合使用的混合窗口注意力。
卷积传播。该策略在每个子集之后添加一个额外的卷积块来作为替代。卷积块是一个残差块,由一个或多个卷积和一个 identity shortcut 组成。该块中的最后一层被初始化为零,因此该块的初始状态是一个 identity。将块初始化为 identity 使得该研究能够将其插入到预训练主干网络中的任何位置,而不会破坏主干网络的初始状态。
1.前两个阶段(浅层cnn与Transformer并联,下图CB与TB应为并联)
cnn可以提取高频信息,空洞cnn扩大卷积感受野,Transfor提取低频信息。三者并联,融合信息

2.第三阶段:大量自注意力操作
六、Next-ViT(字节跳动:2022.06工业轻量化)
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
论文:https://arxiv.org/abs/2207.05501
三大亮点:Next Convolution Block(NCB)、Next-ViT(NTB)、混合范式
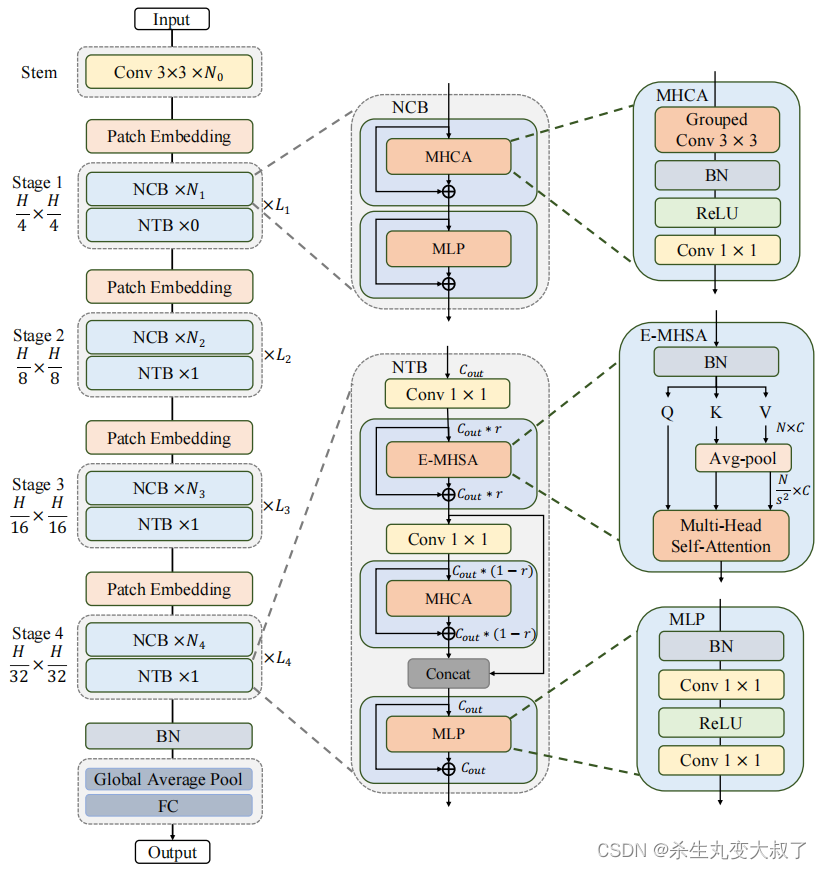
6.1 Next Convolution Block(NCB)
ResNet 提出的 BottleNeck 块因其固有的归纳偏差和部署而在视觉神经网络中长期占据主导地位。大多数硬件平台的友好特性。
不幸的是,与 Transformer 模块相比,BottleNeck 模块的有效性并不能令人满意。ConvNeXt 模块通过模仿 Transformer 模块的设计使 BottleNeck 模块现代化。虽然 ConvNeXt 块部分提高了网络性能,但它在 TensorRT/CoreML 上的推理速度受到低效组件的严重限制,例如 7×7深度卷积、LayerNorm 和 GELU。Transformer blocks在各种视觉任务中取得了优异的成绩,其内在优势是由 MetaFormer 的范式和基于注意力的token mixer模块共同赋予的。然而,Transformer blocks的推理速度比 TensorRT 和 CoreML 上的 BottleNeck 块要慢得多,因为其注意力机制复杂,这在大多数现实工业场景中是难以承受的。
为了克服上述Block的失败,作者引入了 Next Convolution Block (NCB),它在保持 BottleNeck 块的部署优势的同时获得了作为 Transformer 块的突出性能。如图 3(f) 所示,NCB 遵循 MetaFormer 的一般架构,经验证对 Transformer Block 至关重要。与此同时,一个高效的基于注意力的token mixer同样重要。这里作者设计了一种新颖的多头卷积注意力(MHCA)作为具有部署友好卷积操作的高效token mixer。最后,在 MetaFo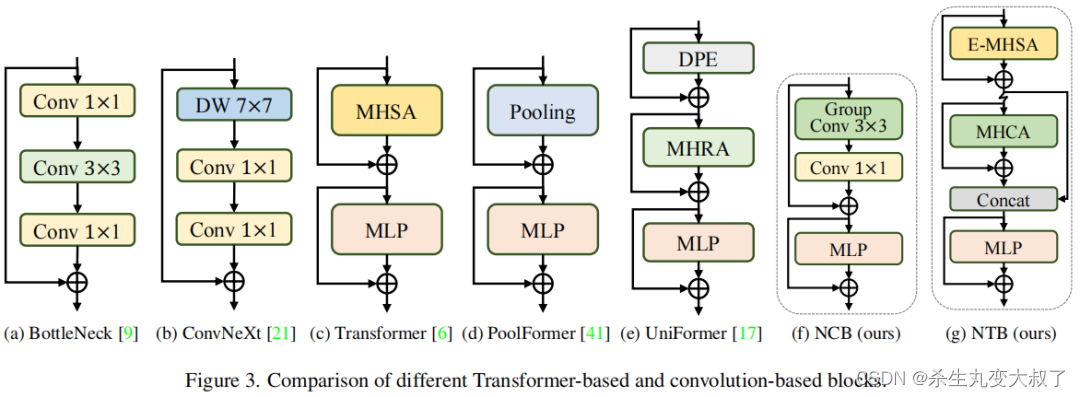
多头卷积 :Multi-Head Convolutional Attention(MHCA)
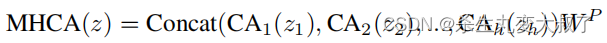
受 MHSA 中有效多头设计的启发,这里采用多头范式构建卷积注意力机制,该范式联合关注来自不同位置的不同表示子空间的信息,以实现有效的局部表示学习。(其实就是组卷积)
MHCA从h个并行表示子空间中捕获信息。为了促进多个头部之间的信息交互,还为MHCA配备了一个投影层(WP)。z(i)表示将输入特征z在通道维度上划分为多头形式。CA是一种单头卷积注意力
6.2 Next Transformer Block (NTB)
虽然通过NCB已经有效地学习了局部表示,但全局信息的捕获迫切需要解决。Transformer Block具有较强的捕获低频信号的能力,从而提供全局信息(例如全局形状和结构)。然而,相关研究观察到,Transformer Block可能会在一定程度上恶化高频信息,如局部纹理信息。不同频率段的信号在人类视觉系统中是不可缺少的,并将以某种特定的方式融合,提取更基本和明显的特征。
基于这些观察结果,作者开发了Next Transformer Block(NTB)来捕获轻量级机制中的多频信号。此外,NTB 作为一种有效的多频信号混频器,进一步提高了整体建模能力。如图2所示,NTB首先采用高效的多头自注意力(E-MHSA)捕获低频信号,可以描述为:
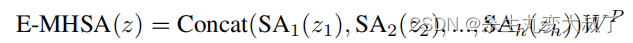
其中,z(i) 表示将输入特征z在通道维数上划分为多头形式。SA是一种空间缩减自注意力算子,其灵感来自于线性SRA,其表现为:
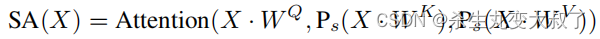
Ps是一种具有Stride的Avg-pool操作,用于在注意力操作前对空间维度进行降采样,以降低计算成本。具体来说,作者观察到E-MHSA模块的时间消耗也很大程度地受到其通道数量的影响。因此,NTB在E-MHSA模块之前使用点卷积进行通道降维,以进一步加速推理。引入了一个收缩比r来减少通道。作者还在E-MHSA模块中使用BN来实现非常高效的部署。
此外,NTB还配备了一个MHCA模块,与E-MHSA模块合作,以捕获多频信号。之后,来自E-MHSA和MHCA的输出特征被连接起来,以混合高低频信息。最后,最后借用MLP层来提取更基本和明显的特征。
6.3 Next Hybrid Strategy (NHS)
最近的一些工作已经付出了巨大的努力,以结合CNN和 Transformer 的有效部署。如图4(b)©所示,几乎所有它们在浅阶段都单调地采用卷积块,在最后一两个阶段只堆栈Transformer Block,在分类任务中得到了有效的效果。不幸的是,作者观察到,这些传统的混合策略在下游任务(如分割和检测)上可以轻松地达到性能饱和。原因是,分类任务只使用最后一阶段的输出来进行预测,而下游任务(如分割和检测)通常依赖于每个阶段的特征来获得更好的结果。然而,传统的混合策略只是在最后几个阶段堆叠Transformer Block。因此,浅层阶段无法捕获全局信息,例如物体的全局形状和结构,这对分割和检测任务至关重要。
为了克服现有混合策略的失败,作者提出了一种新的混合策略 (NHS),它创造性地将卷积块 (NCB) 和Transformer Block (NTB) 与 (N+1)* L 混合范式堆叠在一起。NHS在控制 Transformer Block的比例的情况下,显著提升下游任务中的模型性能,以实现高效部署。
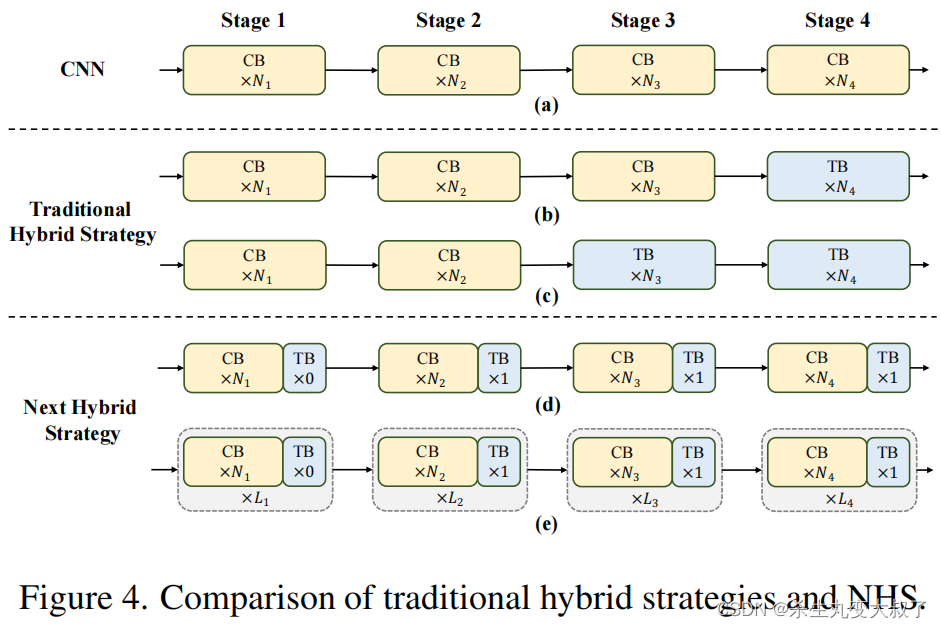
将 NCB 和 NTB 与上面的 Next Hybrid Strategy 进行叠加来构建 Next-ViT,可以正式定义为:
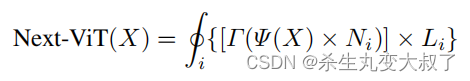
其中 i ∈ (1, 2, 3, 4) 表示阶段索引。Ψ 表示 NCB。Γ 表示当 i = 1 时的id层,否则为 NTB。最后,H 表示顺序堆叠阶段的操作。
详细实验结果:
https://mp.weixin.qq.com/s/iwTrK8gdB9c9GNIyiMfnMA
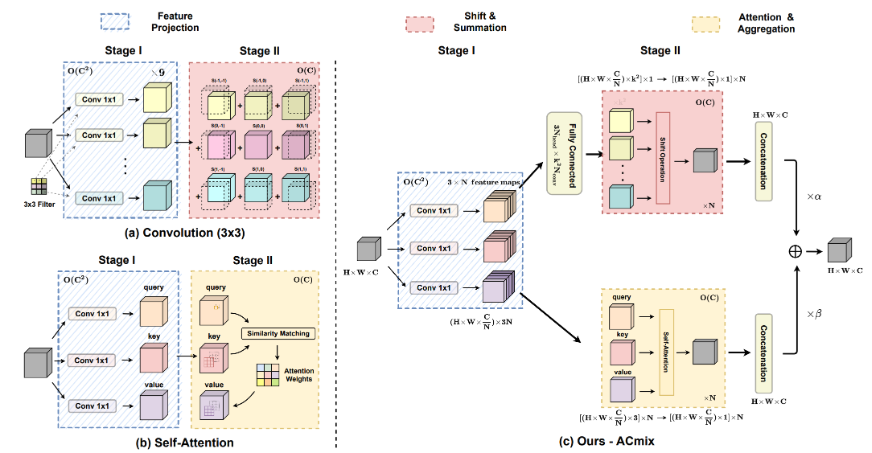
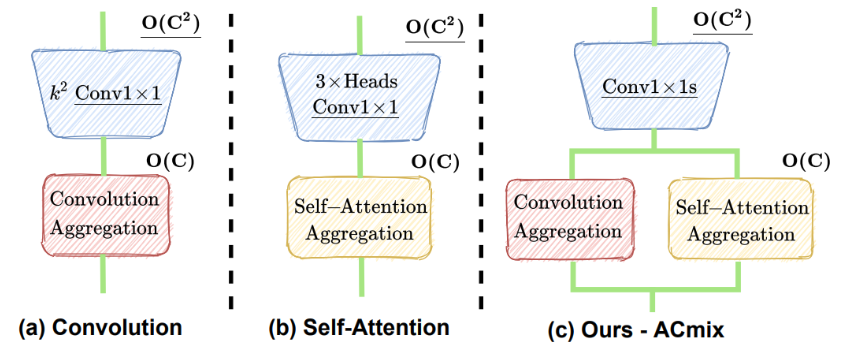
七、ACMix:Integration of convolution and attention(清华:深度融合模块)
出发点:
CNN and transformers are not as diffrenrt as their name;
论文主要考虑到:一个33 CNN相当于9个11卷积,Trans的最原始映射也相当于1*1卷积。因此,两个模块的第一阶段都包含了类似的操作。更重要的是,与第二阶段相比,第一阶段的计算复杂度(通道的平方)占主导地位。
八、Tiny-Transformers(北大CVPR2022:CNN指导ViT在小数据集训练)
论文:Locality Guidance for Improving Vision Transformers on Tiny Datasets
链接:https://arxiv.org/pdf/2207.10026.pdf
代码:https://github.com/lkhl/tiny-transformers
主要思想是采用CNN生成的伪标签,来指导vit在小数据集上训练。在缺显卡,又要从头训一个新的Transformer结构非常实用。
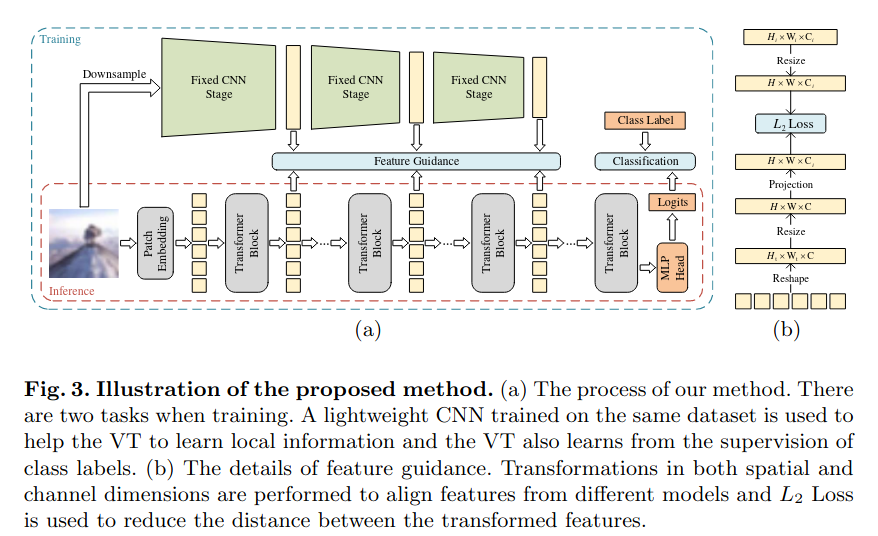
九、ConvNet(基于vit的全新卷积 CVPR2022)
论文:a ConvNet for the 2020s
ArXiv:https://arxiv.org/abs/2201.03545
Github:https://github.com/facebookresearch/ConvNeXt
1.摘要
最近很多网友咨询我CNN与 Transformer区别,专门案例最新的一篇文章,来探讨他们之间的 性能gap在哪。
2020s,Transformer开始引入视觉,即ViT,它能快速超过CNN并取得SOTA的识别性能。而原始的ViT架构,在通用的计算机视觉任务上如目标检测和语义分割等面临不少困难。直到 具有分层架构的Transformer如Swin Transformer ,通过重新引入ConvNet一些设计,它作为一种通用的视觉backbone并在多个视觉任务上取得优良的表现,才让Transformer变得实用。但是,这种混合架构的有效性,在很大程度归功于Transformer的内在优势,而不是卷积固有的归纳偏差(inductive biases)。这篇文章重新审视设计的空间,并测试一个纯CNN网络能取得什么样的上限。作者通过逐渐将一个标准的ResNet模型,不断往ViT的设计中改造,并发现了几个关键的成分导致了性能的差异。构造的纯ConvNet系列模型,能够取得超过Swin Transformer的性能,在ImageNet-1K上取得了超过87.8%的Top1精度。
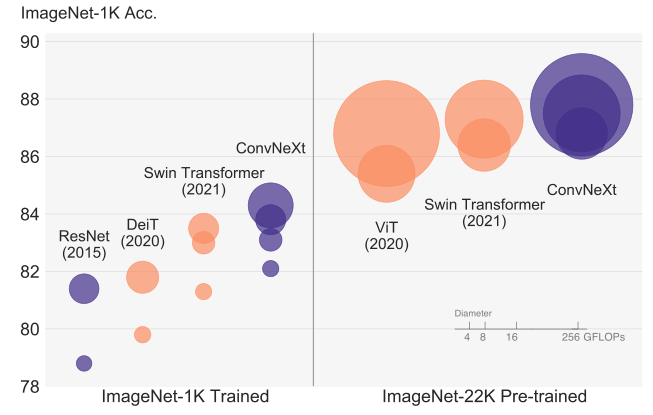
2、ConvNet 的现代化路线图
滑窗”策略(如局部窗口内的注意力)被重新引入到Transformers中,使得他们的行为与ConvNets相似,Swin Transformer是朝着这个方向发展的里程碑式的工作,它首次证明了Transformer可以用作通用的视觉主干,并在图像分类之外的一系列计算机视觉任务上实现了SOTA的性能。从这个角度来看,swin Trans在计算机视觉方面的许多进步都旨在恢复卷积。然而,这些尝试有代价的:滑窗自注意力的朴素实现可能很昂贵;使用循环移位等先进方法,可以优化速度但在系统设计上更加复杂。另一方面,ConvNets已经满足了许多所需要的属性,尽管是以一种直接、简洁的方法。ConvNets失去动力(性能差异)的唯一原因是分层的ViT有卓越的可扩展性,其中关键组件是多头注意力。
本文从标准的ResNet开始,以一种渐进式的改进过程。作者逐渐将架构“现代化”,朝着分层Transformer如SwinT去构建。该探索由一个关键的问题引导:Transformer中的设计决策如何影响ConvNet的性能?作者发现了几个关键组件导致了该性能的差异。
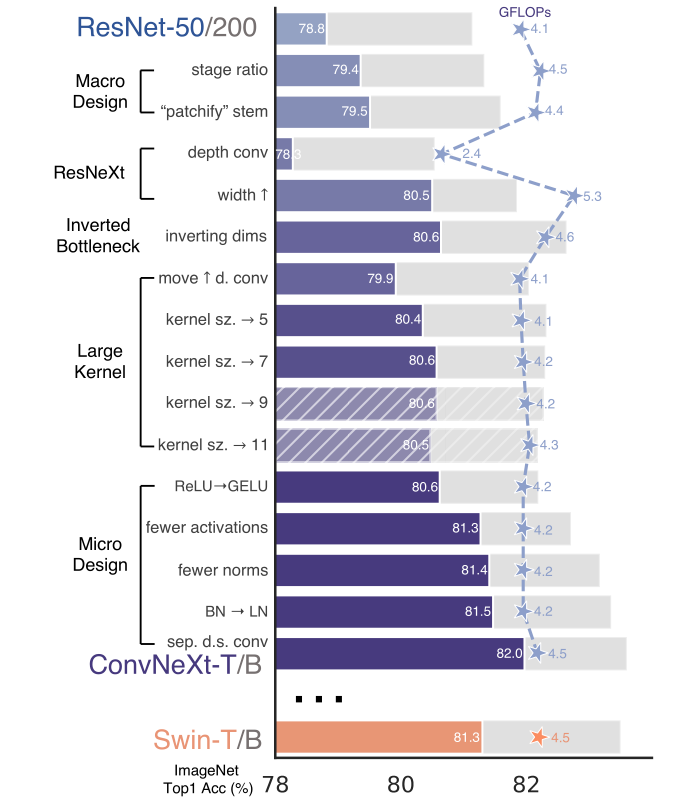
以上实验不引入任何基于注意力的模块。作者根据FLOP考虑两种模型大小,一种是ResNet50、Swin-Tiny体,其FLOPs约为4.5G;另一种是ResNet200、Swin-Base体,其FLOPs为15.0G。前景条是ResNet50、Swin-Tiny在FLOPs上的精度。ResNet200、Swin-Base方法的结果用灰色条显示。阴影线表示未采用修改。
2.1 训练技巧
作者使用了接近Deit和Swin Transformer相近的训练方法。训练ResNet从原始的90个epoch到300个epoch,使用AdamW优化器、数据增强技术如Mixup、Cutmix、RandAugment、Random Erasing等,随机深度、标签平滑等正则化方法。就其本身而言,这种提升的训练方案将ResNet50性能从76.1%提高到78.8%,这意味着传统ConvNet和Transformer之间的很大一部分性能差异可能来自训练技巧。 作者在整个“现代化”过程中使用这种固定超参的训练方法。ResNet50报告的精度是通过三种不同的随机种子进行训练获得的平均值。
2.2 宏观设计
Swin Transformer遵循ConvNet使用多阶段设计,其中每个阶段具有不同的分辨率。有两个有趣的设计因素考虑:阶段计算比例,和 输入stem结构。
(1) 改变阶段计算比例。
ResNet跨阶段计算分布的原始设计在很大程度上经验性的。res4阶段旨在与目标检测等下游任务兼容,其中检测头网络在14 × 14 特征图上运行。另一方面,Swin Transformer遵循相同的设计原则,但阶段计算比例略有不同,为1 : 1 : 3 : 1。对于较大的Swin Transformer,比例是1 : 1 : 9 : 1 。按照设计,作者将每个阶段的块数从ResNet50中的3 : 4 : 6 : 3 调整为3 : 3 : 9 : 3,这也使FLOPs与Swin-Tiny对齐。这将模型准确率从78.8%提升到79.4%。
(2) 输入stem Patch化。
通常,输入stem设计关注的是在网络开始时如何处理输入图像。由于自然图像固有的冗余性,一个常见的输入stem 在标准的ConvNet和ViT中积极地将输入图像下采样到合适的特征图大小。标准ResNet模型中的干细胞包含有一个7 × 7 步长为2的卷积层,然后跟着一个最大池化层,这导致了输入图像的4倍下采样。在ViT中,干细胞采用了更激进的“patchify”策略,相当于对应较大的内核大小(核大小为14或16)和非重叠卷积。Swin Transformer采用类似的patchify层,但使用了更小的4 × 4 补丁大小来适应架构的多阶段设计。作者将ResNet风格的干细胞替换为使用4 × 4、步长为4的卷积层实现补丁化层。准确率从79.4提升到79.5。
2.3 ResNeXt-ify(分组卷积)
本ResNeXt比原始的ResNet取得了更好的FLOPs/Accuracy均衡,核心组件是分组卷积,其中卷积滤波器被分为不同的组。在较高的层面上,ResNeXt的指导原则是“使用更多的组,扩大宽度”。更精确地说,ResNeXt对BottleNeck中的3 × 3卷积采用分组卷积。这显著降低FLOPs,因此扩展了网络宽度以补偿容量损失。
在作者的案例中,使用深度卷积DW-CNN,这是分组卷积的一种特殊情况,每一组只有一个通道。DW-CNN已经被MobileNet和Xception推广。作者注意到,DW-CNN类似于self-attention中的加权求和操作,它在每个通道的基础上操作,即仅在空间维度上融合信息。DW-CNN和Point-wise CNN的组合导致了空间与通道混合的分离,这是ViT共享的属性,其中每个操作要么混合空间维度或通道维度的信息,而不能同时混合两者。DW-CNN的使用有效地降低了FLOPs,预期地一样,和准确度。按照ResNeXt提到的策略,作者将网络宽度增加到Swin-Tiny相同的通道数(从64到96),FLOPs增加到5.3G,识别率也达到了了80.5%。
2.4 倒置BottleNeck
每个Transformer块的重要设计是它创造了一个倒置的BottleNeck,即MLP块的隐藏维度是输入维度的四倍。有趣的是,Transformer这种设计与ConvNets中使用的扩展比为4的倒置BottleNeck设计有关联。这个想法被MobileNet-v2推广,随后在几个先进的ConvNets网络中获得关注。
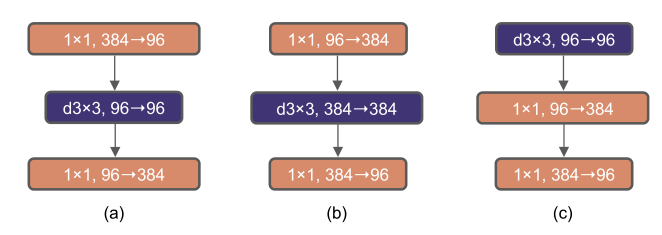
模块修改和对应的规格:(a) ResNeXt的一个块;(b) 作者创建的反转维度后的BottleNeck块;(c)将DW-CNN层上移后的模块。
作者探索了倒置BottleNeck的设计。比较有意思的是,网络的FLOPs减少到4.6G,但精度从80.5提升到80.6,在ResNet200和Swin-Base中,这一步带来了更大的收益,从81.9增加到82.6,运算量反而减低。
2.5 大核的尺寸
ViT最显著的方面之一是它们的非局部注意力,它使每一层都具有全局感受野。虽然过去ConvNets也使用大卷积核,但黄金标准(VGG普及)是堆叠小卷积核(3 × 3)的卷积层,在现代GPU上具有高效的硬件实现。尽管Swin Transformer将局部窗口重新引入自注意力模块中,但窗口大小至少为7 × 7 ,明显大于3 × 3 的ResNe(X)t等。
(1) 上移DW-CNN层
为了探索大内核,一个先决条件是向上移动DW-CNN的位置,上图c。这在ViT设计中也很明显:MSA模块放置在MLP层前。这是一个自然的设计选择:即复杂而低效率的模块(如MSA、大内核)具有更少的通道,而高效率的1 × 1将完成繁重的工作。这个中间步骤将FLOPs降低到4.1G,性能也暂时下降到79.9%。
(2) 扩大卷积核尺寸
采用更大内核的好处是明显的,作者尝试了几个内核大小,包括3 , 5 , 7 , 9 , 11 。网络的性能从79.9(3×3)增加到80.6(7×7),而网络的FLOPs大致保持不变。此外,作者观察到大核的好处在(7×7)出达到饱和。因此,默认采用核大小为7的卷积层。
2.6 微观设计
这里大部分探索都是在层级完成的,重点关注激活函数和归一化层的选择。
(1) 使用GELU替代ReLU
ReLUctant即整流线性单元由于其简单性和效率,仍然在ConvNets中广泛使用。ReLU也被用在原始Transformer论文中。高斯误差线性单元GELU,可以看作是ReLU的一个平滑变体,被用于最先进的Transformer中,包括谷歌的BERT,OpenAI的GPT2,和大多数最近的ViT中。作者发现ReLU可以用GELU代替,尽管精度保持不变,都为80.6%。
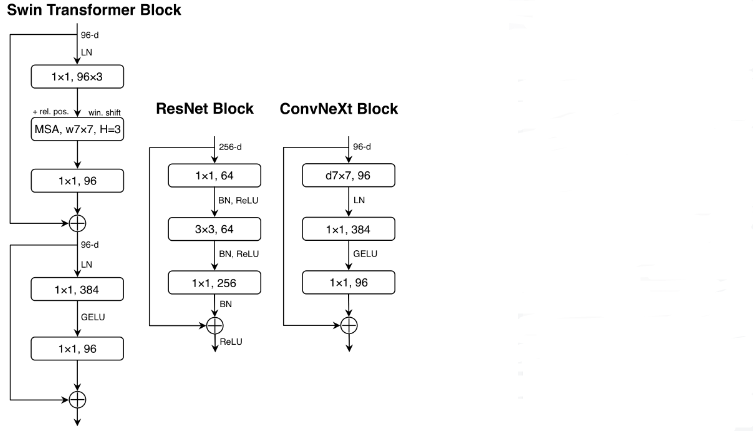
(2) 更少的激活函数
小区别:Transformer的激活层更少。考虑一个带有QKV的线性嵌入层、投影层和MLP块中的两个线性层的Transformer块,在MLP块中只有一个激活函数。相比之下,通常的做法是在每个卷积层(包括1×1)后附件一个激活函数。如图,作者从残差块中消除了所有的GELU层,除了两个1 × 1层之间的一个,复制了Transformer块的样式。这个过程将结果提高了0.7%到81.3%,与Swin-Tiny性能相当。因此,作者在每个模块中使用单个GELU激活。
(3) 更少的归一化层
Transformer块通常具有更少的归一化层。这里,作者删除了两个BN层,在conv 1 × 1层之前只留有一个BN层。这进一步将性能提升到81.4%,超过Swin-Tiny的效果。注意,作者设计的模块的归一化层比Transformer还要少,因为根据经验作者发现在模块的开头添加一个额外的BN层并不能提高性能。
(4) 用LN替代BN
BatchNorm是ConvNets的重要组成部分,因为它提高了收敛性并减少过拟合。但是,BN可能会对模型的性能产生一些不利的影响。尽管有很多尝试去开发可替代的归一化技术,但BN在多数视觉任务中仍然是首先。另一方面,Transformer中更简单的层归一化即Layer Norm,在不同的应用场景中实现良好的性能。
在原始的ResNet中直接用LN替换BN,将导致性能欠佳。随着网络架构和训练技术的修改,作者重新审视了使用LN替代BN的影响。观察到,作者的ConvNet模型使用LN训练没有任何困难;实际上,性能稍好一点,达到了81.5%。因此,作者在每个残差块中采用LN作为归一化。
(5) 单独的下采样层
ResNet中下采样是在每一层中通过残差块来实现的,即使用3 × 3、步长为2的卷积(在shortcut中是1 × 1 、步长为2的卷积)。在Swin Transformer中,一个单独的下采样层被添加到各个阶段之间。作者探索了一个类似的策略,采用使用2 × 2、步长为2的卷积进行空间下采样。这种修改,出乎意料地导致了不同的训练。进一步调查表明,在空间分辨率发生变化的地方,添加归一化层有利于稳定训练。其中包括Swin Transformer中也使用的几个LN层:每个下采样层前有一个,主干细胞之后有一个,和全局池化层之后的一个。作者将性能提升到82.0%,明显超过了Swin-Tiny的81.3%。
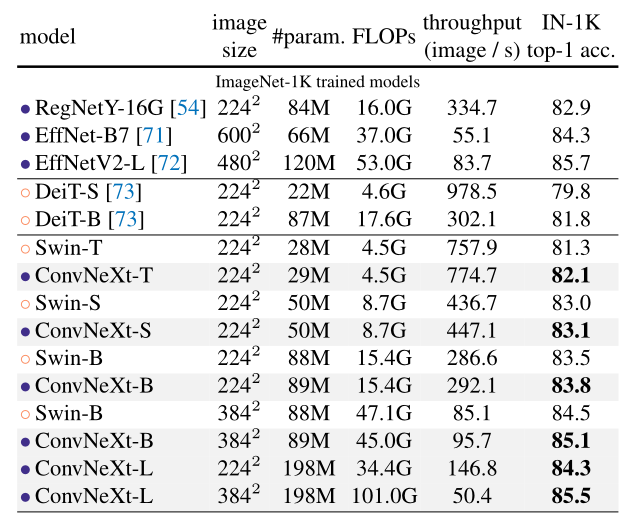
在ImageNet-1K上,与各大深度网络的性能对比。不难发现,ConvNeXt-Tiny相比较于同等运算量的Swin-Tiny,取得了超过0.8%到82.1%的Top1 acc。在更大输入图像分辨率即384下,更大容量的ConvNext-Base也比Swin-Base取得更好的性能。
3.核心代码
ConvNeXt 基本构造块:
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return
ConvNeXt整体结构:
stem:将图像分块
downsample_layers:单独从BottleNeck中剥离,在分辨率发生变化后添加归一化层
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 128
128 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)