
图像分类-KNN
KNN算法原理及实践,py38代码附上github地址
一键AI生成摘要,助你高效阅读
问答
·
图像分类-KNN
前言
KNN算法原理及实践
github地址
一、KNN算法原理
1.1 基本理论
K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
1.2 距离度量
1.2.1欧式距离
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离。
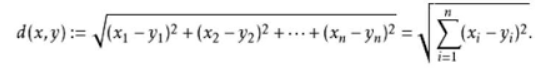
1.2.2曼哈顿距离
欧氏距离有一个局限是度量两点之间的直线距离。但实际上,在现实世界中,我们从原点到目标点,往往直走不能到达的。曼哈顿距离加入了一些这方面的考虑。
两个n维向量x(x1;x2;…;xn)与 y(y1;y2;…;yn)间的曼哈顿距离:
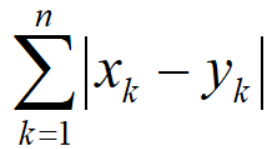
二、KNN算法实践
2.1 KNN算法实现
'''
KNN计算逻辑
1)给定测试对象,计算它与训练集中每个对象的距离
2)圈定距离最近的k个训练对象,作为测试对象的邻居
3)根据这k个近邻对象所属的类别,找到占比最高的那个类别作为测试对象的预测类别
影响knn算法的准确度:1、计算测试对象与训练集中各个对象的距离,2、k的选择
'''
import numpy as np
import matplotlib.pyplot as plt
import operator
#训练数据的类别
def creatDataSet():
X_train=np.array([[1.0,2.0],[1.2,0.1],[0.1,1.4],[0.3,3.5],[1.1,1.0],[0.5,1.5]])
y_train=np.array(['A','A','B','B','A','B'])
return X_train,y_train
if __name__=='__main__':
X_train,y_train=creatDataSet()
plt.scatter(X_train[y_train=='A',0],X_train[y_train=='A',1],color='r',marker='*')
plt.scatter(X_train[y_train=='B',0],X_train[y_train=='B',1],color='g',marker='+')
plt.show()
#基于欧式距离的Knn分类器
def KNN_classify(k,distance,X_train,y_train,Y_test):
'''
:param k:
:param distance: 距离
:param X_train: 上述group
:param x_train: label
:param Y_test:测试集
:return: 标签列表
'''
# distance=='E' or distance=='M'
assert distance == 'E' or distance =='M','dis must E or M,E为欧拉距离,M为曼哈顿距离'
labellist=[]
num_test=Y_test.shape[0]
print(num_test)
print(X_train.shape[0])
print(X_train)
'''使用欧式距离'''
if (distance=='E'):
for i in range(num_test):
distances=np.sqrt(np.sum(((X_train-np.tile(Y_test[i],(X_train.shape[0],1)))**2),axis=1))
print(np.tile(Y_test[i], (X_train.shape[0], 1)))
print(distances)
nearest_k=np.argsort(distances)#距离由小到大进行排序,并返回index值
topK=nearest_k[:k]
classCount={}
for i in topK:
classCount[y_train[i]]=classCount.get(y_train[i],0)+1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
'''使用曼哈顿距离'''
if distance=='M':
for i in range(num_test):
distances=np.sum(abs(X_train-np.tile(Y_test[i],(X_train.shape[0],1))),axis=1)
nearest_k=np.argsort(distances)
topK=nearest_k[:k]
classCount={}
for i in topK:
classCount[y_train[i]]=classCount.get(y_train[i],0)+1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
if __name__=='__main__':
X_train,y_train=creatDataSet()
y_test_pred=KNN_classify(1,'M',X_train,y_train,np.array([[1.0,2.1],[0.4,2.0]]))
print(y_test_pred)#['A' 'A']
KNN例子散点图

2.2 KNN进行图像分类-用于MNIST数据集
# 开发时间 ;2021/6/4 0004 11:12
import torch
from torch.utils.data import DataLoader
import numpy as np
import operator
#基于Knn分类器
def KNN_classify(k,distance,X_train,y_train,Y_test):
# distance=='E' or distance=='M'
assert distance == 'E' or distance =='M','dis must E or M,E为欧拉距离,M为曼哈顿距离'
labellist=[]
num_test=Y_test.shape[0]
# print(num_test)
# print(X_train.shape[0])
# print(X_train)
'''使用欧式距离'''
if (distance=='E'):
for i in range(num_test):
distances=np.sqrt(np.sum(((X_train-np.tile(Y_test[i],(X_train.shape[0],1)))**2),axis=1))
# print(np.tile(Y_test[i], (X_train.shape[0], 1)))
# print(distances)
nearest_k=np.argsort(distances)#距离由小到大进行排序,并返回index值
topK=nearest_k[:k]
classCount={}
for i in topK:
classCount[y_train[i]]=classCount.get(y_train[i],0)+1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
'''使用曼哈顿距离'''
if distance=='M':
for i in range(num_test):
distances=np.sum(abs(X_train-np.tile(Y_test[i],(X_train.shape[0],1))),axis=1)
nearest_k=np.argsort(distances)
topK=nearest_k[:k]
classCount={}
for i in topK:
classCount[y_train[i]]=classCount.get(y_train[i],0)+1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
def getXmean(X_train):
X_train = np.reshape(X_train, (X_train.shape[0], -1)) # 将图片从二维展开为一维
mean_image = np.mean(X_train, axis=0) # 求出训练集所有图片每个像素位置上的平均值
std_image=X_train.std()
return mean_image,std_image
def centralized(X_test,mean_image,std_image):
X_test = np.reshape(X_test, (X_test.shape[0], -1)) # 将图片从二维展开为一维
X_test = X_test.astype(np.float32)
X_test -= mean_image # 减去均值图像,实现零均值化
return X_test
#KNN实现MNIST数据分类
#使用pytorch框架进行数据的下载与读取
import torch
import torchvision.datasets as da
import torchvision.transforms as transforms
batch_size=100
#minist dataset
train_dataset=da.MNIST(root='/pymnist', #选择数据根目录
train=True, #选择训练数据集
transform=None, #不考虑使用任何数据预处理
download=True) #从网上下载
test_dataset=da.MNIST(root='/pymnist', #选择数据根目录
train=False, #选择测试数据集
transform=None, #不考虑使用任何数据预处理
download=True) #从网上下载
#加载数据
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)#打乱数据
test_loader=torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
'''
数据集数据都是n*m维的矩阵,这里的n是样本数(行数),m是特征数(列数)
训练集包括6000个样本,测试集包括10000个样本,在MNIST数据集中,每张图片由28*28像素点构成
每个像素点使用一个灰度值表示
我们将28*28像素展开为一个一维的行向量,所以每一行就是一张图
'''
#可视化
import matplotlib.pyplot as plt
photo_1=train_loader.dataset.train_data[0]
plt.imshow(photo_1,cmap=plt.cm.binary)
plt.show()
print(train_loader.dataset.train_labels[0])
if __name__=='__main__':
# 归一化处理后的结果
x_train = train_loader.dataset.train_data.numpy()
x_mean, x_std = getXmean(x_train)
x_train = centralized(x_train, x_mean, x_std).reshape(x_train.shape[0], 28 * 28)
y_train = train_loader.dataset.train_labels.numpy()
x_test = test_loader.dataset.test_data[:1000].numpy()
x_mean, x_std = getXmean(x_test)
x_test = centralized(x_test, x_mean, x_std).reshape(x_test.shape[0], 28 * 28)
y_test = test_loader.dataset.test_labels[:1000].numpy()
num_test = y_test.shape[0]
y_test_pred = KNN_classify(5, 'E', x_train, y_train, x_test)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('E: Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
y_test_pred = KNN_classify(5, 'M', x_train, y_train, x_test)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('M: Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
得到结果为:
E: Got 962 / 1000 correct => accuracy: 0.962000
M: Got 954 / 1000 correct => accuracy: 0.954000
2.3 KNN进行图像分类-用于CIFAR10数据集
import operator
#Knn分类器
def KNN_classify(k,distance,X_train,y_train,Y_test):
'''
:param k:
:param distance: 距离
:param X_train: 上述group
:param x_train: label
:param Y_test:测试集
:return: 标签列表
'''
# distance=='E' or distance=='M'
assert distance == 'E' or distance =='M','dis must E or M,E为欧拉距离,M为曼哈顿距离'
labellist=[]
num_test=Y_test.shape[0]
print(num_test)
print(X_train.shape[0])
print(X_train)
'''使用欧式距离'''
if (distance=='E'):
for i in range(num_test):
distances=np.sqrt(np.sum(((X_train-np.tile(Y_test[i],(X_train.shape[0],1)))**2),axis=1))
print(np.tile(Y_test[i], (X_train.shape[0], 1)))
print(distances)
nearest_k=np.argsort(distances)#距离由小到大进行排序,并返回index值
topK=nearest_k[:k]
classCount={}
for i in topK:
classCount[y_train[i]]=classCount.get(y_train[i],0)+1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
'''使用曼哈顿距离'''
if distance=='M':
for i in range(num_test):
distances=np.sum(abs(X_train-np.tile(Y_test[i],(X_train.shape[0],1))),axis=1)
nearest_k=np.argsort(distances)
topK=nearest_k[:k]
classCount={}
for i in topK:
classCount[y_train[i]]=classCount.get(y_train[i],0)+1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
labellist.append(sortedClassCount[0][0])
return np.array(labellist)
#-----------------------------------------------------------------------------------------------------------------------
#使用pytorch框架进行数据的下载与读取
import torch
from torch.utils.data import DataLoader
import torchvision.datasets as da
import torchvision.transforms as transforms
batch_size=100
#Cifar10 dataset
train_dataset=da.CIFAR10(root='DL/pycifar', #选择数据根目录
train=True, #选择训练数据集
download=True) #从网上下载
test_dataset=da.CIFAR10(root='DL/pycifar', #选择数据根目录
train=False, #选择测试数据集
download=True) #从网上下载
#加载数据
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)#打乱数据
test_loader=torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
#-----------------------------------------------------------------------------------------------------------------------
#分类图片可视化
classify=('plane','car','bird','cat',
'deer','dog','frog','horse','ship','truck')
digit=train_loader.dataset.data[0]
import matplotlib.pyplot as plt
plt.imshow(digit,cmap=plt.cm.binary)
plt.show()
print(classify[train_loader.dataset.targets[0]])#frog
#-----------------------------------------------------------------------------------------------------------------------

总结
一个KNN的分类器的学习记录,代码在py38上全跑通

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)