sklearn机器学习之线性回归模型
⭐️几天没写博客了,接着来,接下来的内容主要涉及机器学习的sklearn的API的章节,本章节将开启机器学习的入门的课程????:该系列学习主要是讲sklearn中机器学习API的使用。该系列只会涉及较少的原理知识。只会涉及基础概念。目录1.线性回归模型的概念2.sklearn实现2.1 简单的直线2.2 两点定线3. 广义线性回归模型3.1线性回归的性能表现4. 岭回归——L2正则化5. 套索回
·
⭐️几天没写博客了,接着来,接下来的内容主要涉及机器学习的sklearn的API的章节,本章节将开启机器学习的入门的课程👇:
- 该系列学习主要是讲sklearn中机器学习API的使用。
- 该系列只会涉及较少的原理知识。只会涉及基础概念。
1.线性回归模型的概念

2.sklearn实现
线性回归的API
from sklearn.linear_model import LinearRegression,Ridge,Lasso
2.1 简单的直线
这里我们画一条y=0.5x+3的图像
#线性回归
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(-5,5,100)#x轴
y=0.5*x+3#表达式y
plt.plot(x,y,c='green')
plt.title("line")
plt.show()

2.2 两点定线
我们使用两点(1,3)和(4,5)来确定一条直线,这里有重要的东西需要说明,x的形状必须是列向量!coef_和intercept_是sklearn表示模型属性的值w和b
#通过两点计算直线
from sklearn.linear_model import LinearRegression
x=[[1],[3]]#这里一定要是一个列向量
y=[3,5]
lr=LinearRegression().fit(x,y)
z=np.linspace(0,5,20)
plt.scatter(x,y,s=80)
plt.plot(z,lr.predict(z.reshape(-1,1)),c='k')#将z转化为列向量
plt.show()
# coef_[0]代表斜率和interce_代表截距
print('斜率',lr.coef_[0],'截距',lr.intercept_)#计算斜率和截距

3. 广义线性回归模型
这里我们使用make_regressions函数来生成回归数据集。
# 使用make_regressions生成回归数据集
from sklearn.datasets import make_regression
x,y=make_regression(n_samples=50,n_features=1,n_informative=1,noise=50,random_state=1)
'''
n_samples:样本数
n_features:特征数(自变量个数)
n_informative:参与建模特征数
n_targets:因变量个数
noise:噪音
bias:偏差(截距)
coef:是否输出coef标识
random_state:随机状态若为固定值则每次产生的数据都一样
'''
#线性拟合
reg=LinearRegression().fit(x,y)
z=np.linspace(-3,3,200).reshape(-1,1)
#画出散点图
plt.scatter(x,y,c='r',s=80)
#画出拟合直线
plt.plot(z,reg.predict(z),c='k')
plt.show()
3.1线性回归的性能表现
拟合的好不好需要指标来衡量,lr.score函数就是通过R^2决定系数来计算模型的好坏。
#使用拆分工具来进行线性回归
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
x,y=make_regression(n_samples=100,n_features=2,n_informative=2,random_state=38)
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=8)
lr=LinearRegression().fit(x_train,y_train)
print("训练",lr.score(x_train,y_train))#这里的分数为R^2决定系数1最好,0最差
print("测试集损失",lr.score(x_test,y_test))

我们使用糖尿病数据集来测试
#糖尿病数据集测试
from sklearn.datasets import load_diabetes#导入数据
x,y=load_diabetes().data,load_diabetes().target#分为特征和标签
#将数据集0.8分为训练集,0.2分为测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=8)
#线性回归
lr=LinearRegression().fit(x_train,y_train)
print(lr.score(x_train,y_train))
print(lr.score(x_test,y_test))

4. 岭回归——L2正则化

岭回归中有个参数alpha来控制过拟合的程度
ridge=Ridge(alpha=1).fit(x_train,y_train)
我们使用糖尿病数据集来测试
from sklearn.datasets import load_diabetes#导入数据
x,y=load_diabetes().data,load_diabetes().target#分为特征和标签
#将数据集0.8分为训练集,0.2分为测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=8)
#岭回归L2正则化
from sklearn.linear_model import Ridge
ridge=Ridge().fit(x_train,y_train)
print('训练集分数:',ridge.score(x_train,y_train))
print("测试集分数:",ridge.score(x_test,y_test))
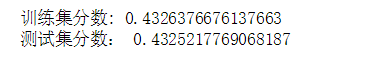
5. 套索回归——L1正则化

from sklearn.datasets import load_diabetes#导入数据
x,y=load_diabetes().data,load_diabetes().target#分为特征和标签
#将数据集0.8分为训练集,0.2分为测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=8)
#套索回归lasso
from sklearn.linear_model import Lasso
lasso=Lasso().fit(x_train,y_train)
print('训练集分数:',lasso.score(x_train,y_train))
print("测试集分数:",lasso.score(x_test,y_test))

参考资料
《深入浅出python机器学习》

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)