2、A Multi-Core Approach to Efficiently Mining High-Utility Itemsets in Dynamic Profit Databases
1、论文希望解决的问题:Transactional data changes over time,Many algorithms for mining high-utility itemsets (HUI) ignore this important property and thus are inapplicable or generate inaccurate results on real

1、论文希望解决的问题:
Transactional data changes over time,Many algorithms for mining high-utility itemsets (HUI) ignore this important property and thus are inapplicable or generate inaccurate results on real data.
2、作者的目标:
Proposes a novel algorithm Multi-Core HUI Miner (MCH-Miner), It adapts techniques introduced in the iMEFIM algorithm to run on a parallel multi-core architecture(并行多核体系结构) to effificiently mine HUIs in dynamic transaction databases.
3、问题定义:
High-utility Itemset (HUI):
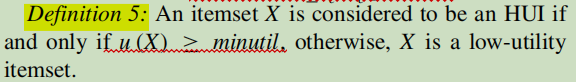
High-utility Itemset Mining(HUIM):

4、关键技术:
(1)more compact representation of the dynamic database D [12]


(2) the MCH-MINER algorithm
现如今,多处理器现在以multi-core processors的形式被广泛应用,将数据库分成几个部分,并存储在分布式服务器上。 但不适用于在单核处理器上执行串行数据挖掘算法的情况。采用当前的并行执行数据挖掘方法带来了新的挑战,如负载平衡、通信最小化和同步。三种支持并行的方式:task parallelism, data parallelism, and hybrid task/data parallelism
本文着重于任务并行性(task parallelism),通过拓展iMEFIM,设计了一个新的算法MCH-Miner algorithm, 采用分治策略,利用当多核处理器来加快模式挖掘过程。MCH-Miner 将搜索划分为子空间,每一个1-item作为独立的任务进行DFS,所有子空间不重叠。
(3) 解决负载平衡问题(load balancing problem)
负载平衡就是为每个进程分配大约相同数量的任务(处理器),保证每个处理器都在工作,尽量减少空闲时间。

采用多核并行计算模型,任务在单个多核处理器上执行。 因此,负载平衡非常简单,由于所有核共享相同的内存空间(使用共享内存系统),所有需要执行的任务都是分开的,其搜索空间不一致。因此,些任务被放到一个大小等于可用处理器核数量的任务池中。 然后,任务由处理器的核同时执行,使用先到先服务(FCFS)调度策略,直到所有任务完成。
(这部分看不太懂。)
5、相关文献
Two-Phase [8], IHUP [9], UP Growth [10], EFIM [11].
iMEFIM [12]: extends the EFIM algorithm, combines the newly introduced framework, a novel data structure named P-set is utilized to signifificantly reduce the cost of database scans.
6、总结
论文将HUIM的所有技术和策略与多核并行计算模型相结合,扩展了IMEFIM算法。结果是一种新的高性能算法MCH-Miner,它在动态利润数据库中并行挖掘HUI。
感觉创新性不如之前老师给的几篇top-k FIM的论文。
这是一篇越南人写的论文,语言方面也没有太大的借鉴价值。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)