机器学习-泛化能力
目录1.什么是泛化能力2.什么是好的机器学习模型的提出3.泛化误差4.模型泛化能力的评价标准4.提高泛化能力5.举例6.相关引用文献1.什么是泛化能力百度百科解释:机器学习算法对新鲜样本的适应能力。更加具体的解释:学习到的模型对未知数据的预测能力,这个未见过的测试数据必须是和训练数据处于同一分布,不在同一分布的数据是不符合独立同分布假设的(对同一规律不同的数据集的预测能力)。通常通过测试误差来评价
目录
1.什么是泛化能力
百度百科解释:机器学习算法对新鲜样本的适应能力。
更加具体的解释:学习到的模型对未知数据的预测能力,这个未见过的测试数据必须是和训练数据处于同一分布,不在同一分布的数据是不符合独立同分布假设的(对同一规律不同的数据集的预测能力)。通常通过测试误差来评价学习方法的泛化能力。
通俗+形象解释:
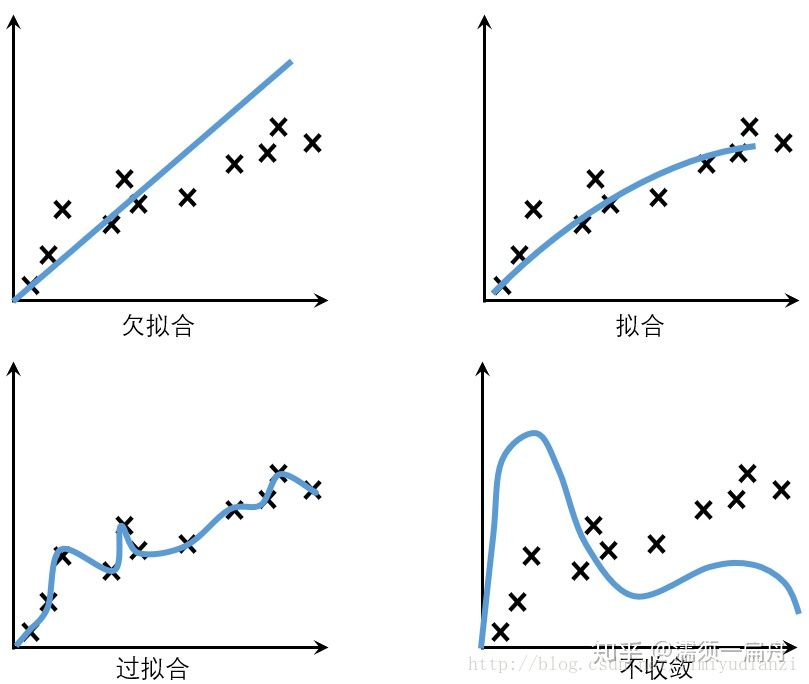
就是通过数据训练学习的模型,拿到真实场景去试,这个模型到底行不行,如果达到了一定的要求和标准,它就是行,说明泛化能力好,如果表现很差,说明泛化能力就差。为了更好的理解泛化能力,这里引入三种现象,欠拟合、过拟合以及不收敛。泛化能力的本质就是反映模型有没有对客观世界做真实的刻画,还是发生了过拟合。
考试成绩差的同学,有这三种可能:
一、泛化能力弱,做了很多题,始终掌握不了规律,不管遇到老题新题都不会做,称作欠拟合;
二、泛化能力弱,做了很多题,只会死记硬背,一到考试看到新题就蒙了,称作过拟合;
三、完全不做题,考试全靠瞎蒙,称作不收敛。
2.什么是好的机器学习模型的提出
奥卡姆的威廉是 14 世纪一位崇尚简单的修士和哲学家。 他认为科学家应该优先采用更简单(而非更复杂)的公式或理论。
奥卡姆剃刀定律在机器学习方面的运用如下:
机器学习模型越简单,良好的实证结果就越有可能不仅仅基于样本的特性。
现今,我们已将奥卡姆剃刀定律正式应用于 统计学习理论 和 计算学习理论 领域。这些领域已经形成了 泛化边界,即统计化描述模型根据以下因素泛化到新数据的能力:
-
模型的复杂程度
-
模型在处理训练数据方面的表现
虽然理论分析在理想化假设下可提供正式保证,但在实践中却很难应用。 机器学习速成课程则侧重于实证评估,以评判模型泛化到新数据的能力。
机器学习模型旨在根据以前未见过的新数据做出良好预测。 但是,如果要根据数据集构建模型,如何获得以前未见过的数据呢? 一种方法是将您的数据集分成两个子集:
-
训练集 - 用于训练模型的子集。
-
测试集 - 用于测试模型的子集。
一般来说,在测试集上表现是否良好是衡量能否在新数据上表现良好的有用指标,前提是:
-
测试集足够大。
-
您不会反复使用相同的测试集来作假。
3.泛化误差
首先给出泛化误差的定义, 如果学到的模型是 f^ , 那么用这个模型对未知数据预测的误差即为泛化误差
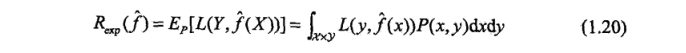
泛化误差反映了学习方法的泛化能力,如果一种方法学习的模型比另一种方法学习的模型具有更小的泛化误差,那么这种方法就更有效, 事实上,泛化误差就是所学到的模型的期望误差。
4.模型泛化能力的评价标准
回归任务常用的性能度量是“均方误差”。
1. 错误率与精度
错误率与精度是分类任务中最常用的两种性能度量。既适用于二分类,也适用于多分类。
错误率:分类错误的样本数占总样本数的比例。
精度 : 分类正确的样本数占总样本数的比例。
精度 + 错误率 = 1
假设,总的样本数为m个,我们对这m个样本进行预测,其中预测对了的样本有p个,预测错的样本有n个(p+n = m),则:
错误率 = n/m
精度 = p/m
2. 查全率、查准率、F1
当任务有所偏好时,错误率与精度便不能满足任务的需求。比如我们关心的是“检索出来的信息中有多少是用户感兴趣的”或者“用户感兴趣的信息有多少被检索出来了”。此时就需要查全率、查准率、F1值来进行模型的性能度量。
假设,总的测试样本有m个,其中正样本有z个,负样本有f个。
查全率:对这m个样本进行预测,其中z个正样本中有zm个被预测对。查全率 = zm / z
查准率: 对这m个样本进行预测,预测的结果中有ym个是正样本,ym个样本中有y个是z的,则:查准率 = y / ym
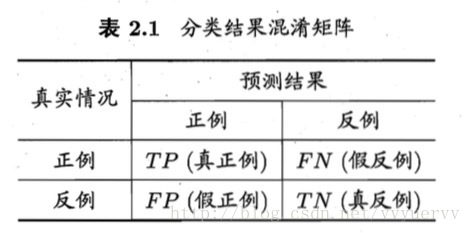
上图为混淆矩阵,TP + FN + FP + TN = 样例总数。
对应的查准率P和查全率R分别定义为:
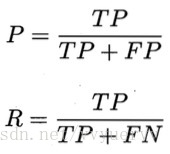
查准率和查全率是一对矛盾的度量。
查准率越高时,查全率往往偏低。而查全率越高时,查准率往往偏低。
P-R曲线:(查准率-查全率曲线)
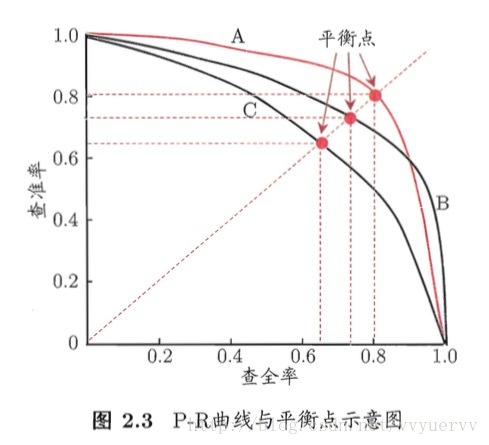
P-R曲线是以查全率为横轴,以查准率为纵轴的二维坐标图。
P-R曲线的建立过程:
根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本,排在后面的则是学习器任务“最不可能”是正例的样本。按此排序,逐个把样本作为正例进行预测,则每次可以计算出当前的查全率和查准率。以此为纵轴和横轴作图,便得到了查全率-查准率曲线,即P-R曲线。
P-R曲线作用:
用来对比不同学习器的好坏的。例如上图2.3中学习器A包含学习器C,则说学习器A优于学习器C。但当两个学习器的P-R曲线有交叉时,难以判断那个学习器较好。通常的做法是计算每个学习器曲线所包含的面积,比较面积的大小。但这值不太容易估算。于是人们便使用“平衡点”(简称BEP)这一度量,即“查准率 = 查全率”时的取值。例如上图中的平衡点可判定,学习器A优于学习器B。
F1值:
F1值为查全率和查准率的协调平均值,
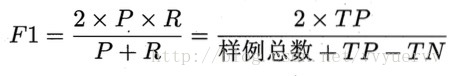
在一些应用中,对查全率和查准率的重视程度有所不同,F1度量的一般形式能让我们表达出对查全率和查准率的的不同偏好。
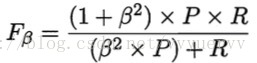
其中β > 0 度量的查全率对查准率的相对重要性。β = 1 时便为标准的F1。β > 1时查全率有更大的影响,β < 1时查准率有更大的影响。
当我们在多个二分类混淆矩阵上综合考虑查全率和查准率时有两种方法:
第一种,先在各混淆矩阵上分别计算出查全率和查准率,再计算平均值。这样就得到了“宏查全率”、“宏查准率”、以及“宏F1”
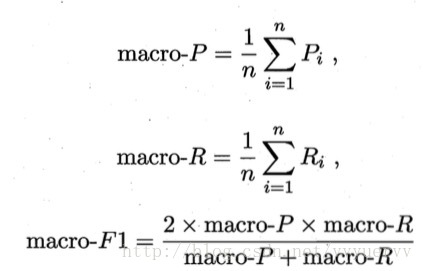
第二种,先将各混淆矩阵的对应元素进行平均,再基于这些平均值进行计算,得出“微查全率”“微查准率”以及“微F1”, 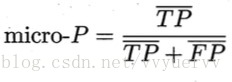

3.ROC与AUC
ROC曲线与AUC常被用来评价一个二分类器的优劣。
和P-R曲线类似,“ROC曲线”是根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要的量值(真正例率TRP和假正例率FPR),分别以他们作为横、纵坐标作图,就得到了“ROC曲线”。

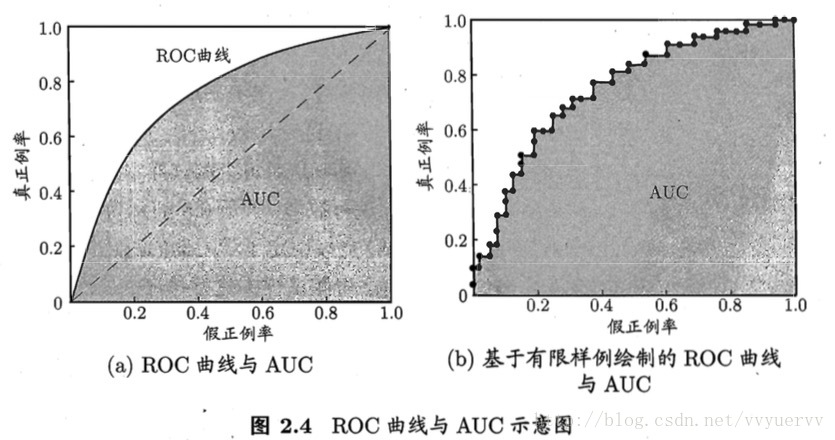
上图(a)中的虚线表示“随机猜测”模型。在(0,1)点处,即FPR=0, TPR=1,这意味着FN = 0,并且FP = 0。这是一个完美的分类器,它将所有的样本都正确分类。在(1,0)点处,即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。在(0,0)点处,即FPR=TPR=0,即FP = TP =0,可以发现该分类器预测所有的样本都为负样本。在(1,1)点处,分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
现实任务中通常是利用有限个测试样本来绘制ROC图的,所以仅能或得有限个(真正例率TRP和假正例率FPR)坐标对,绘制出的图如上图中的(b)。
ROC曲线绘制过程:
给定m个正例和n个反例,根据学习器预测结果对样例进行排序,然后把分类阈值设置为最大,即把所有样例均预测为反例,此时真正例率和假正例率均为0,在坐标(0,0)出标记一个点。然后,将分类的阈值依次设置为每个样例的预测值,即依次将每个样例划分为正例。设前一个标记的坐标为(x,y),当前若为真正例,则对应的标记点的坐标为(x, y+1/m);若当前为假正例,则对应标记点的坐标为(x+1/n, y), 然后用线段连接相邻的点即可。
学习器比较:
若一个学习器A的ROC曲线包含另外一个学习器B的ROC曲线,则认为学习器A的性能优于学习器B。
若两者的ROC曲线相交,则需要对各自ROC曲线下得面积(即AUC)进行比较。
AUC可通过对ROC曲线下各部分面积求和而得。

4.代价敏感错误率与代价曲线
不同类型的错误所造成的后果不同。
为权衡不同类型错误造成的不同损失,可为错误赋予“非均等代价”。
以二分类为例,可设定一个“代价矩阵”
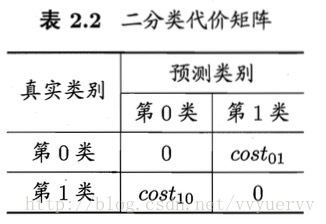
表中cost10 表示将第1类错分为第0类的代价,cost01同样,表示将第0类错分为第1类的代价。此二分类也可拓展为多分类costij表示将第i类错分为第j类的代价。
前面的性能度量都默认的假设了均等代价,所有错误率是直接计算错误的次数,并没有考虑不同错误会造成的不同的后果。在非均等代价下,我们希望的不再是简单地最小化错误次数,而是希望最小化“总体代价”。 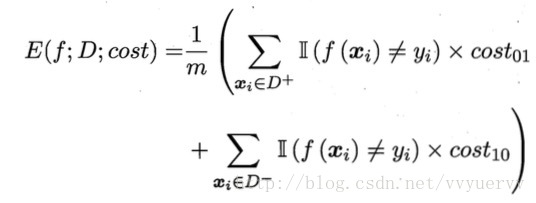
上式中,D+和D-分别表示样例集D中的正例子集和反例子集。
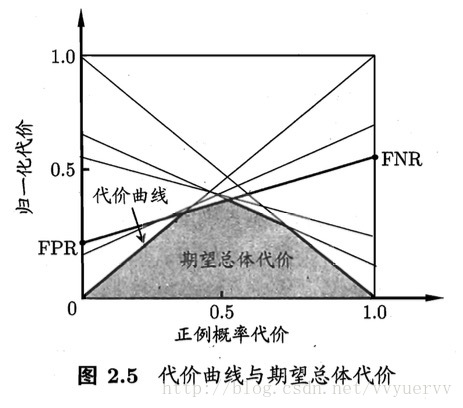
在非均等代价下,ROC曲线不能直接反应学习器期望的总体代价,而“代价曲线”则可达到该目的。
代价曲线图的横轴是取值为[0,1]的正例概率代价: 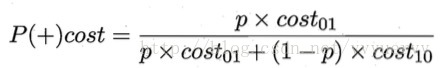
上式中p是样例为正例的概率。
纵轴是取值为[0,1]的归一化代价:
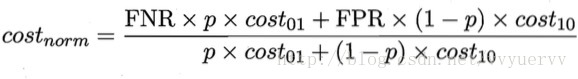
FNR表示假正例率,FNR = 1 - TPR
代价曲线的绘制:
ROC曲线上每一点对应了代价平面上的一条线段,设ROC曲线上的坐标为(TPR,FPR),则可相应的计算出FNR,然后在代价平面上绘制一条从(0,FPR)到(1,FNR)的线段,线段下面的面积即表示了该条件下得期望总体代价。如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价。
4.提高泛化能力
提高泛化能力的方式大致有三种:1.增加数据量。2.正则化。3.凸优化。
5.举例
下面图片中每个点代表一棵树的位置,蓝点代表生病的树,橙点代表健康的树。
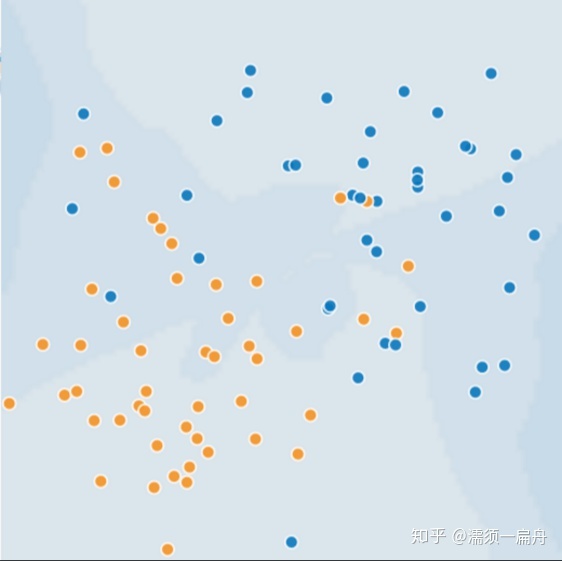
给你样本数据,要求提供一个机器学习算法算法,区分开两种树。
你千辛万苦画出来一条曲线能够很好地进行聚类,而且模型的损失非常低(损失函数),几乎完美的把两类点一分为二。但这个模型真的就是好模型吗?

用该算法预测新样本时,没有很好的区分两类点,表现得有些差劲。
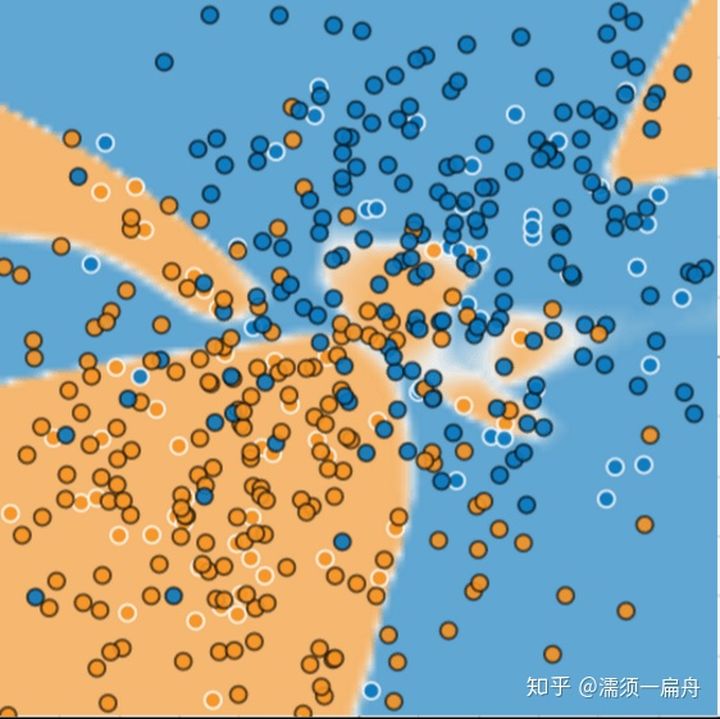
上述模型过拟合了训练数据的特性,过拟合模型在训练过程中产生的损失很低,但在预测新数据方面的表现却非常糟糕。如果某个模型在拟合当前样本方面表现良好,那么我们如何相信该模型会对新数据做出良好的预测呢?过拟合是由于模型的复杂程度超出所需程度而造成的。机器学习的基本冲突是适当拟合我们的数据,但也要尽可能简单地拟合数据。
6.相关引用文献
https://blog.csdn.net/tiankong_/article/details/78361496
https://zhuanlan.zhihu.com/p/59673364?utm_source=wechat_session
https://segmentfault.com/a/1190000016425702?utm_source=tag-newest
https://my.oschina.net/u/4604431/blog/4476343
https://www.jianshu.com/p/849423297c7f
https://blog.csdn.net/vvyuervv/article/details/65449079

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)