吴恩达老师深度学习专项学习笔记
(一)神经网络与深度学习一、概论神经网络:神经元:◯表示非线性函数神经网络:像乐高积木一样堆叠神经元用神经网络进行监督学习(目前神经网络的落地方向比较成熟)结构化数据(海量数据, 广告,赚钱)非结构化数据(图片、语音)为什么兴起数据变多,计算机,算法二、神经网络基础符号标记logistic 回归回顾之前学习内容:参考线性回归:hθ(x)=g(θTx)sigmoid函数:g(z)=11+e−zh_\
文章目录
(一)神经网络与深度学习
一、概论
- 神经网络:
神经元:◯表示非线性函数
神经网络:像乐高积木一样堆叠神经元 - 用神经网络进行监督学习(目前神经网络的落地方向比较成熟)
结构化数据(海量数据, 广告,赚钱)
非结构化数据(图片、语音) - 为什么兴起
数据变多,计算机,算法
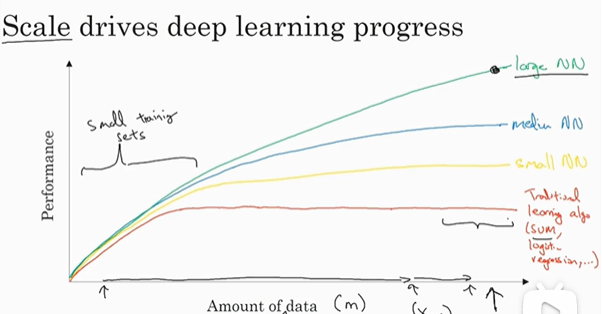
二、神经网络基础
-
符号标记

-
logistic 回归
回顾之前学习内容:参考线性回归:
h θ ( x ) = g ( θ T x ) s i g m o i d 函 数 : g ( z ) = 1 1 + e − z h_\theta(x)=g(\theta^Tx)\\sigmoid函数:g(z)=\frac{1}{1+e^{-z}} hθ(x)=g(θTx)sigmoid函数:g(z)=1+e−z1 -
逻辑回归可以看作很小的神经网路哦

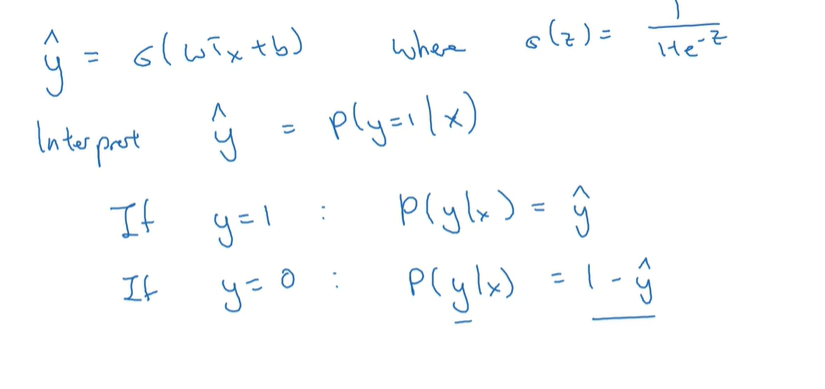

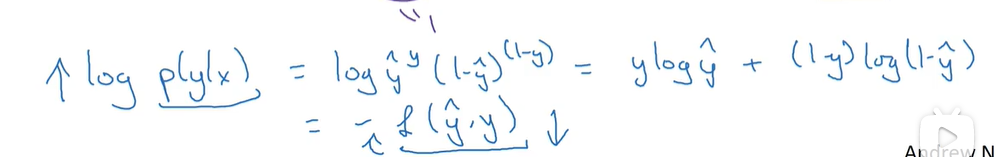
-
梯度下降法
w : = w − α d w b : = b − α d b w := w - \alpha dw\\b := b - \alpha db w:=w−αdwb:=b−αdb -
反向传播:

-
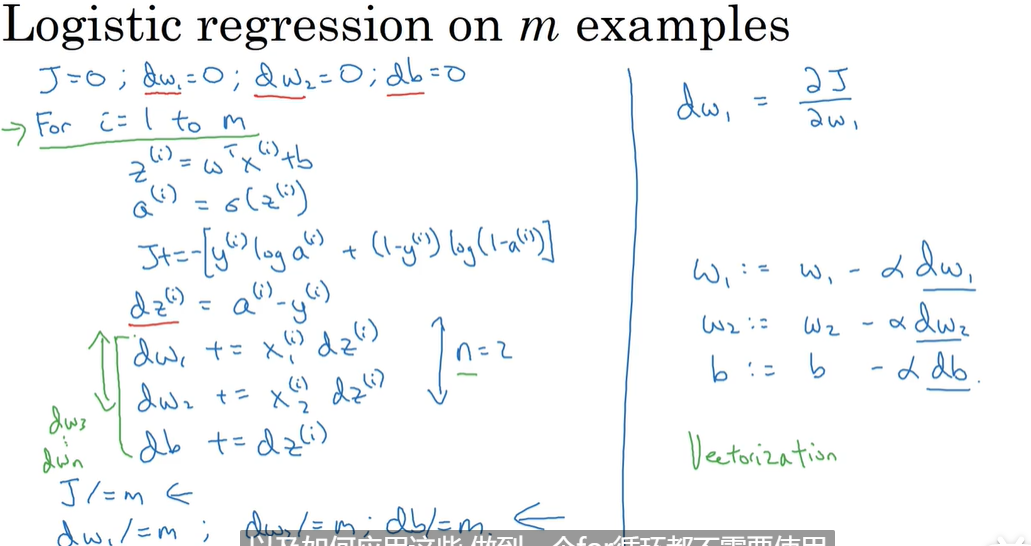
整体过程(使用两个for循环)
-
整体过程向量化(利用CPU和GPU的单指令流)


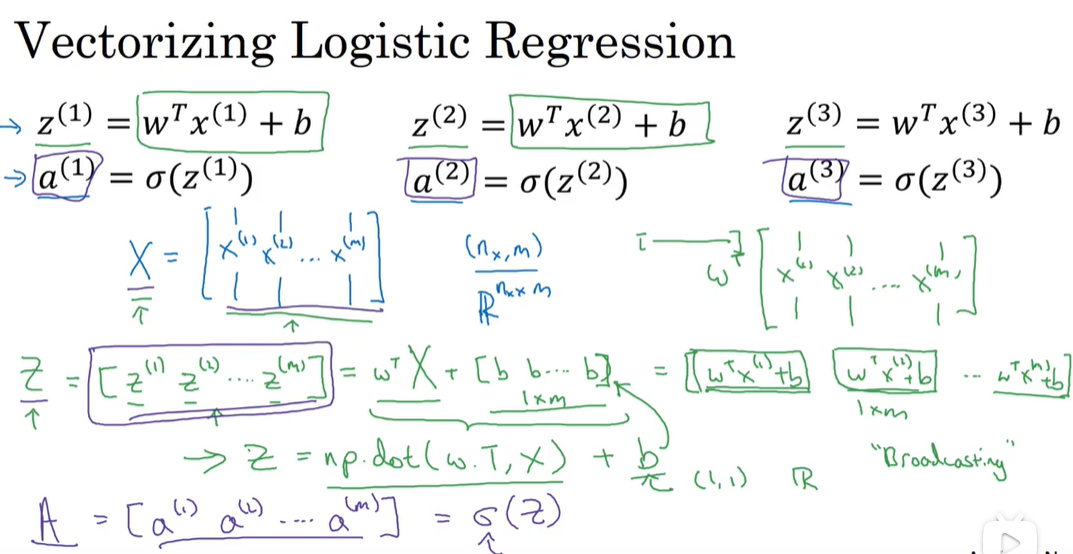


-
python的broadcasting机制
coding小技巧:reshape()来检验你的矩阵是否正确,有用而且几乎不费运行时间
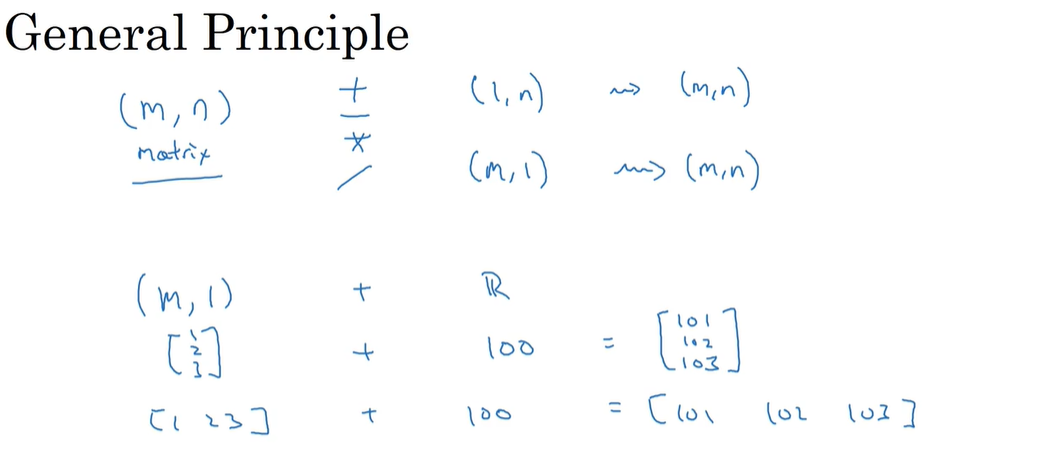
但是用不好很容易出现bug,一些编程小技巧:
-
不要使用秩为1的矩阵(5,),因为这种数据结构既不是行向量也不是列向量,转置是一个行向量,所以np.random.randn(5),np.random.rand(5,1)差别很大
-
如果不确定一个矩阵的大小,使用
assert(a.shape == (5,1)) -
np.multiply :数组和矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致 np.dot():对于秩为1的数组,执行对应位置相乘,然后再相加; 对于秩不为1的二维数组,执行矩阵乘法运算;超过二维的可以参考numpy库介绍。 星号(*)乘法运算:对数组执行对应位置相乘 对矩阵执行矩阵乘法运算
-
三、浅层神经网络
-
网络结构图概览:
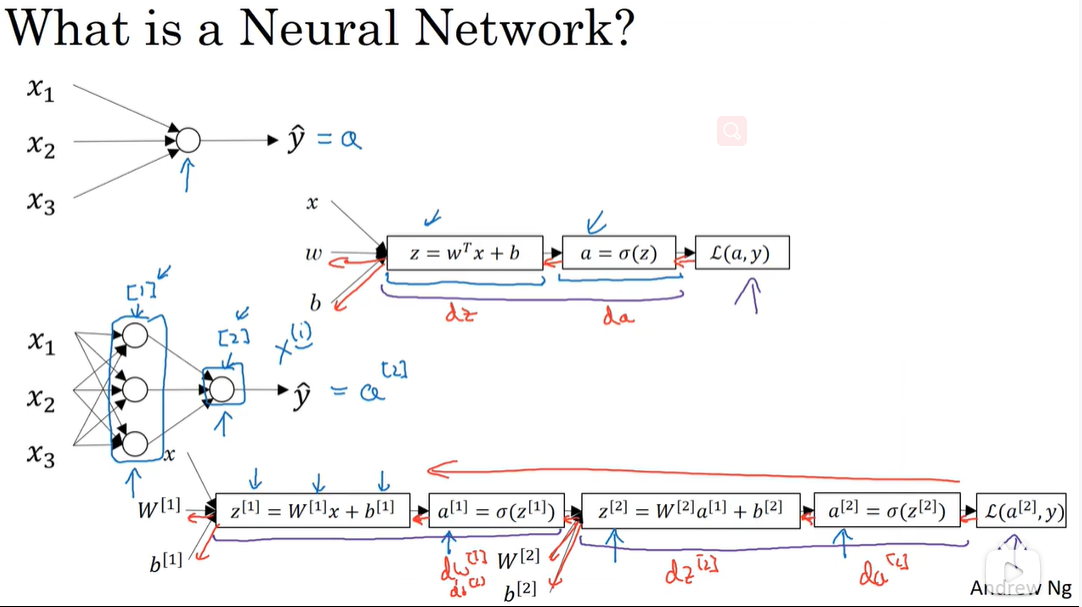
-
神经网络各个参数的表示:

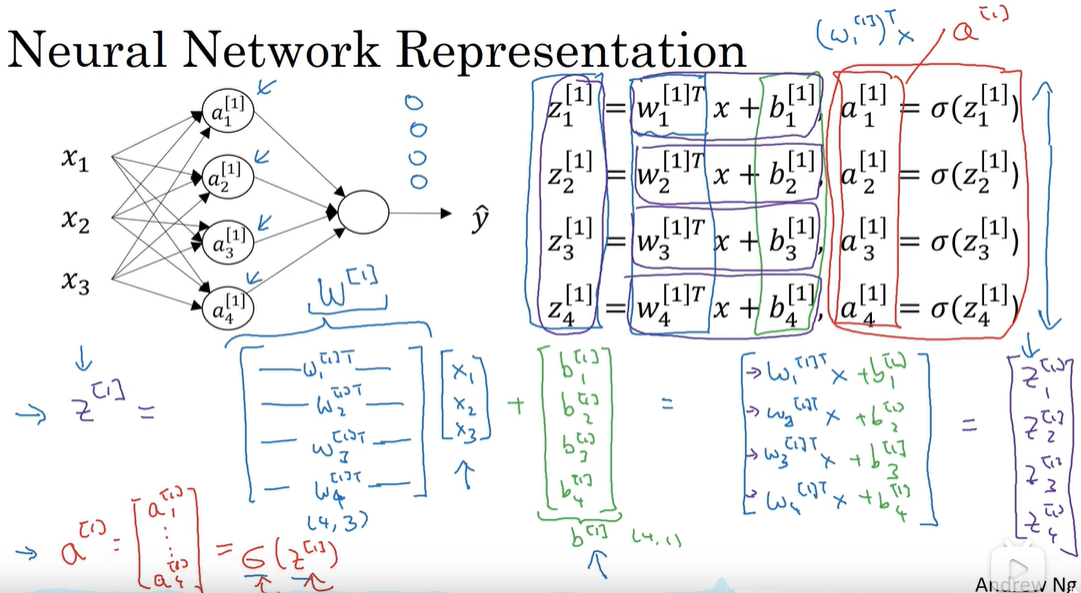
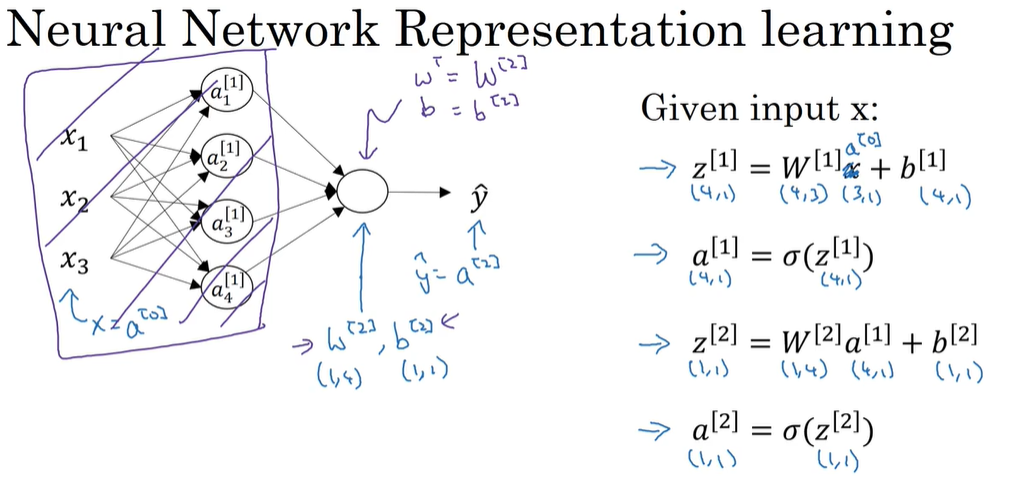

-
激活函数的选择(自己尝试一下哎,怎么测试好坏呢,交叉验证集???)
-
sigmoid函数
σ ( z ) = 1 1 + e ( − z ) 导 数 : σ ( z ) ( 1 − σ ( z ) ) \sigma(z) = \frac{1}{1 + e^{(-z)}}\\导数:\sigma(z)(1 - \sigma(z)) σ(z)=1+e(−z)1导数:σ(z)(1−σ(z)) -
tanh函数==(是sigmoid的平移,但几乎在任何场合都比它优越,但在在二元分类输出层还是使用sigmoid,使其结果在0到1)==
t a n h ( z ) = e z − e − z e z + e − z ( 在 − 1 和 1 之 间 取 值 ) 导 数 : 1 − ( t a n h ( z ) ) 2 tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}} (在-1和1之间取值)\\导数:1-(tanh(z))^2 tanh(z)=ez+e−zez−e−z(在−1和1之间取值)导数:1−(tanh(z))2 -
relu函数–线性修正单元(解决1 2 的z很大时斜率接近于零问题,它的斜率为0到1)
r e l u ( z ) = m a x { 0 , z } relu(z) = max\{0,z\} relu(z)=max{0,z} -
leaky relu,很少用(z为负的时候斜率很小但不为0)
-
-
为什么要使用激活函数?(引入非线性)
-
反向传播算法

-
随机初始化
不能将参数全部初始化为0,原因如下:
同一层的节点将会有相同的值,即隐藏层单元有同样的函数w = np.random.randn(2,2) * 0.01 \\是初始化值过大会使sigmoid函数接近零斜率小,变化慢 b = np.zeros(2,1)
四、深层神经网络
-
符号标记:
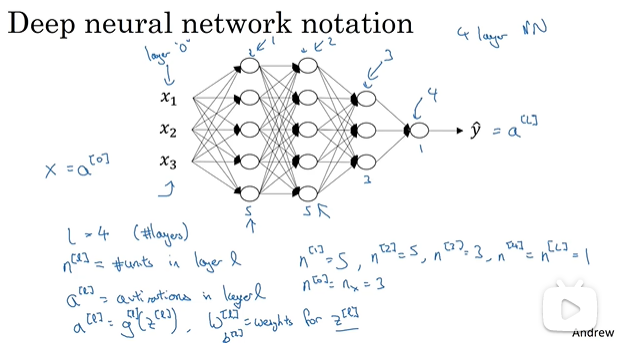
-
核对矩阵维度:( 自己在纸上写一写)
-
为什么深度模型更好用
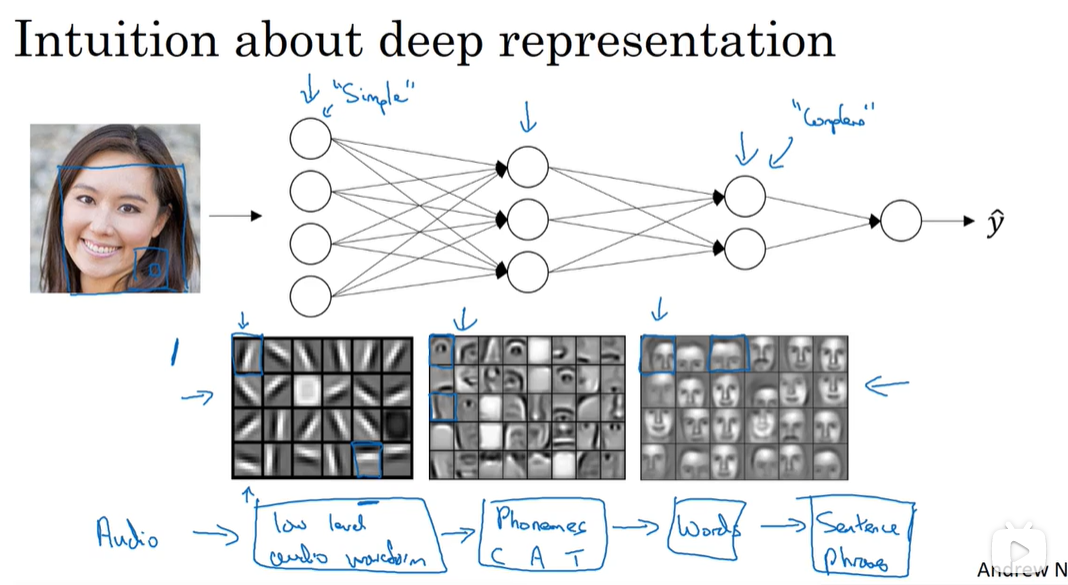
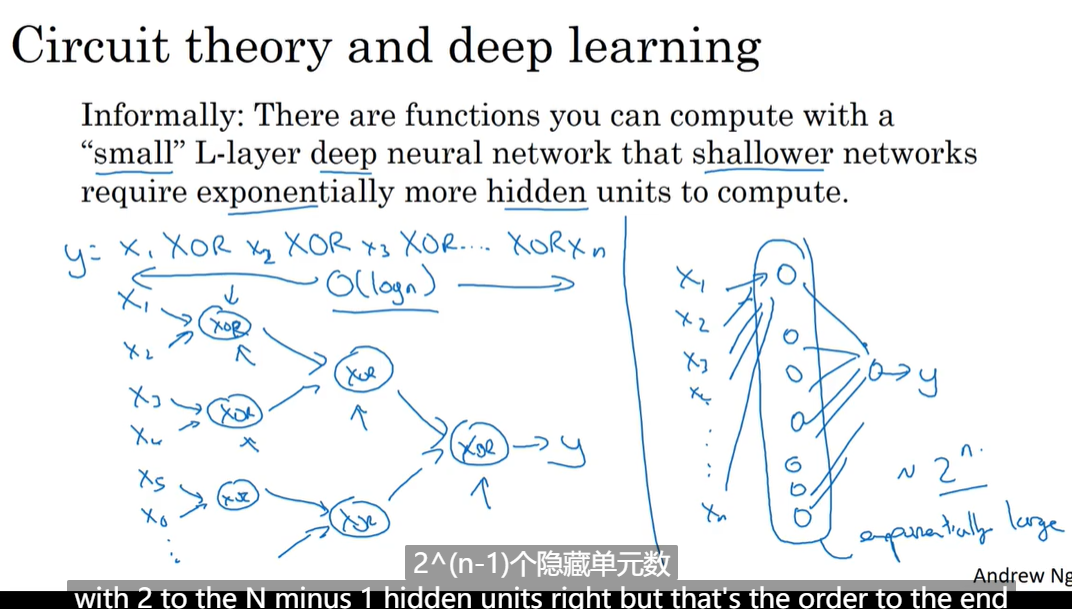
-
神经网络模块化:
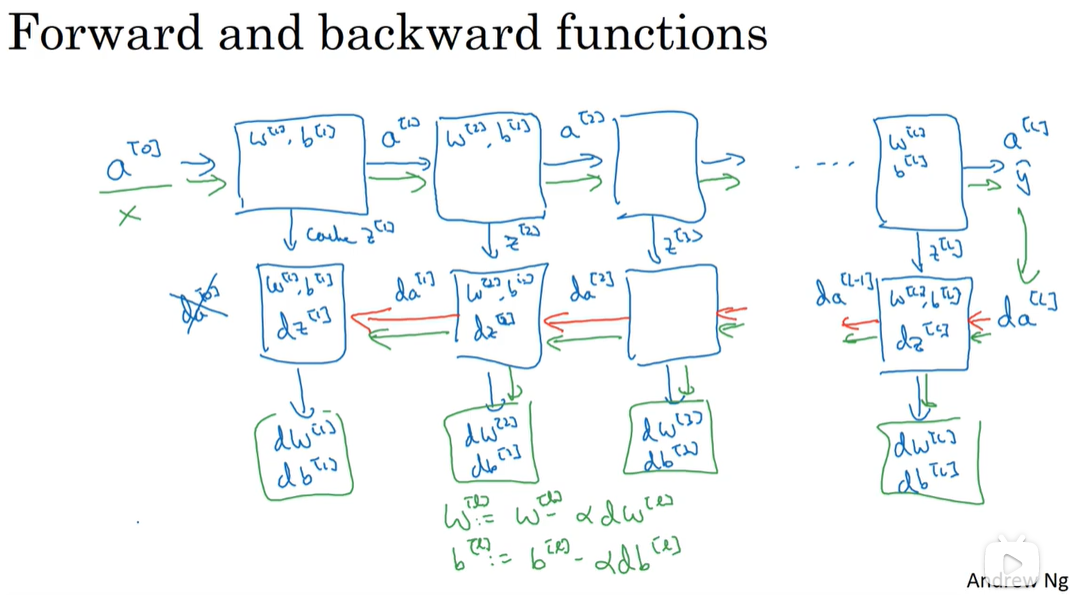


-
参数和超参数:(保留交叉验证不断尝试)
参数:W,b超参数:学习率,迭代次数,隐藏层数,隐藏单元,激活函数的选择
后面要学的超参数:动量,批处理数,正则化参数
(二)改善深层神经网络
一、深度学习的实用层面
-
训练,测试,验证集(平时训练,模拟考试,考试)
小数据集:6:2:2
大数据集:100000个样本 98:1:1
测试集和验证集最好有相同的分布
-
偏差和方差

-
机器学习基础
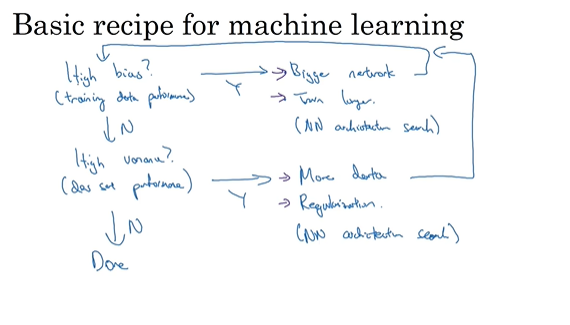
偏差和方差的平衡 目前数据量足够网络足够深时可以做到都小
-
正则化:
一般使用L2正则化(权重衰减矩阵)

为什么使用正则化?
w≈0,奥卡姆剃刀原理,消除一些隐藏单元的影响使网络不至于很复杂
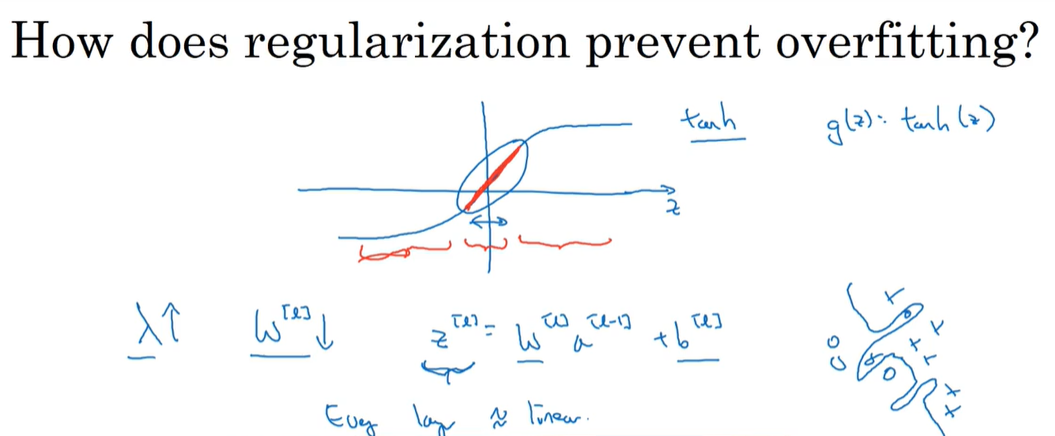
dropout是另一种正则化方法(反向随机失活)一个参数:keep-prob保留节点的概率

- 这样做可以使节点不依赖于任何一个特征,因为这个特征可能会被dropout掉
- 每一层参数不同可以设置不同的keep-prob值,参数多的值设置更小的值
- 超参数少,通常应用于计算机视觉中
- 画损失函数是否梯度下降时关闭Dropout,确保其单调递减后再打开dropout函数
其他的正则化方法:
-
数据增强:翻转,剪裁已有图片来扩增数据集
-
早停法:缺点:不能同时减小方差和减小偏差,而L2正则化会有超参数需要调试

-
输入归一化,减少迭代时间,加速并使数值稳定,主要应用于两特征输入数值相差较大0.1-1,1-10000用就完了不会有伤害
- 最大最小归一化
- 正态分布归一化(一般采用)
- l2归一化(稀疏矩阵)
-
梯度消失,梯度爆炸
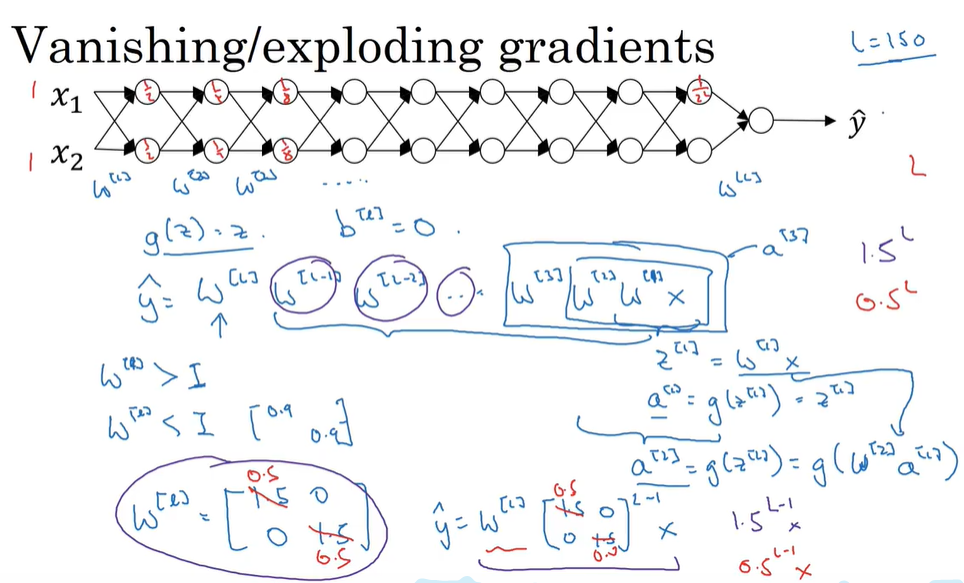
解决方法权重初始化(不能完全解决)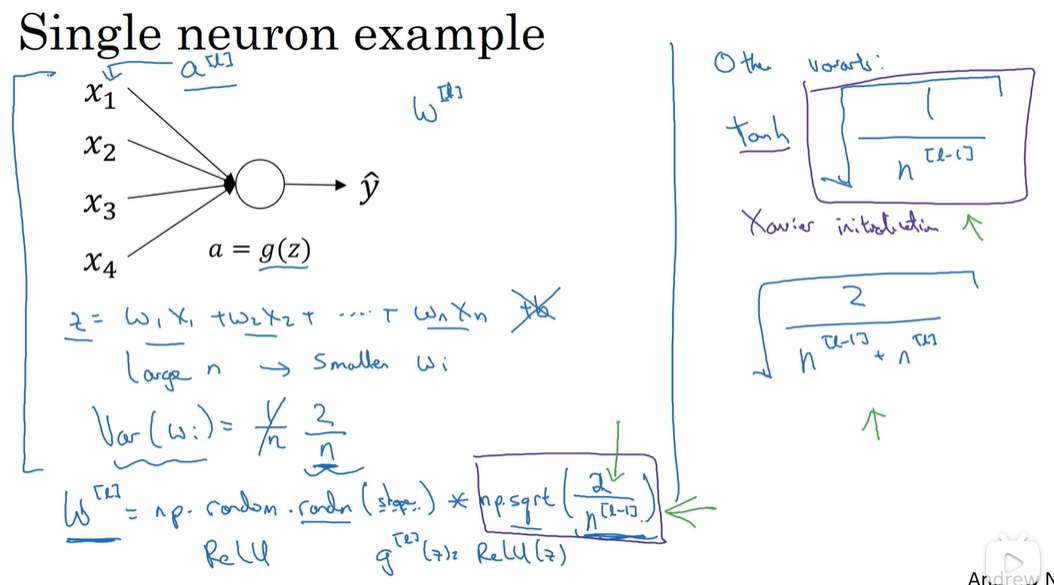
-
梯度检验:
-
梯度的数值逼近

-
梯度检验(检查是否反向传播有问题,可以节约很多时间)

-
注意事项:
- 只在测试的时候使用梯度检验,在训练时不用,会减慢训练速度
- 如果发现有问题,怎么找到问题?追踪到相差比较大的层
- 注意正则化项
- 不能和梯度下降一同使用
-
二、优化算法:
作用:帮你快速训练模型
-
mini-batch 梯度下降法(又一超参数)


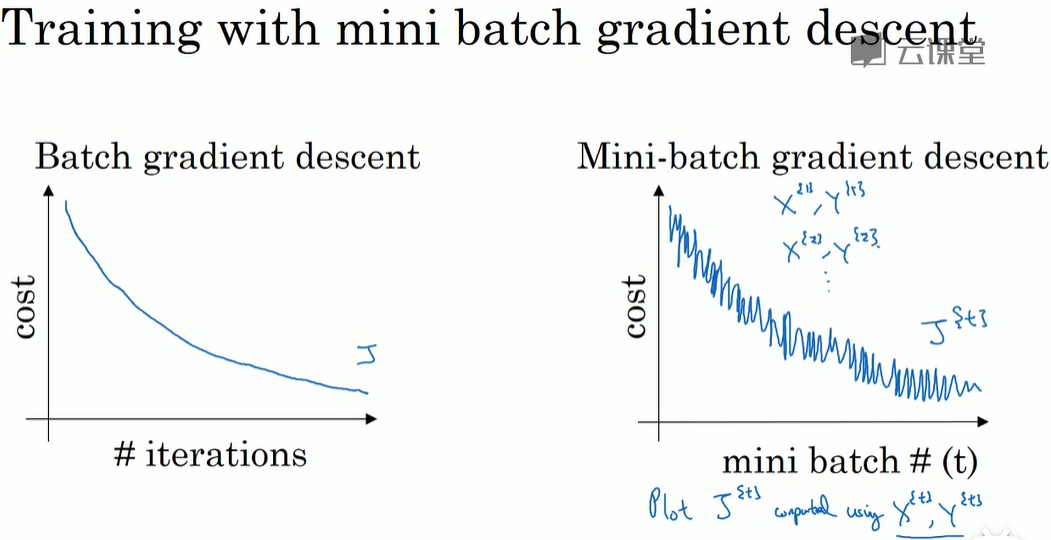


-
指数加权平均

计算指数加权平均只占单行数字的存储和内存,效率很高偏差修正:
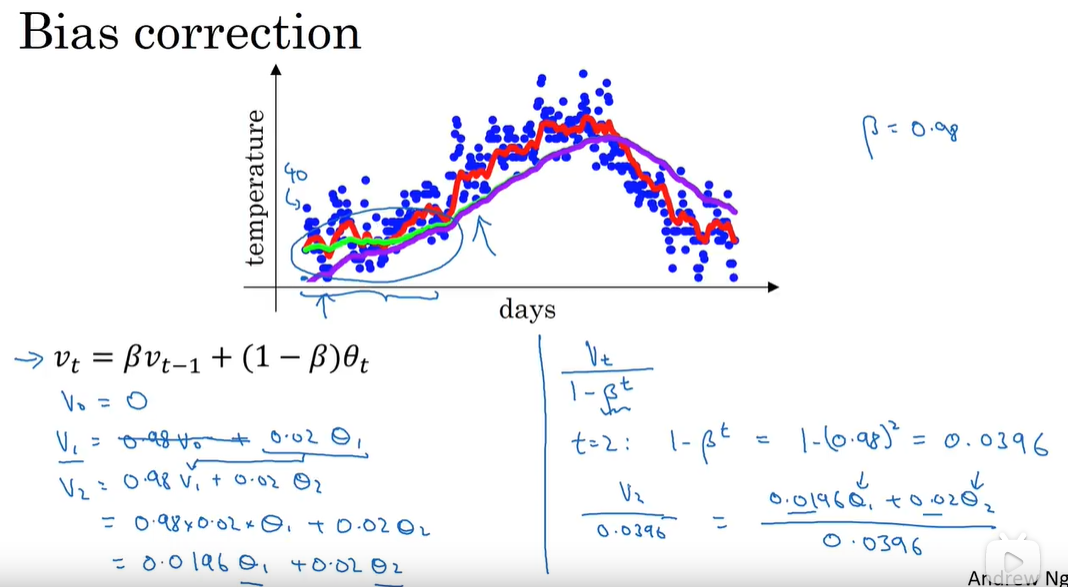
只在早期有修正效果 -
动量梯度下降法(一般快于标准梯度下降法)
更加平缓: β \beta β的值一般设置为0.9
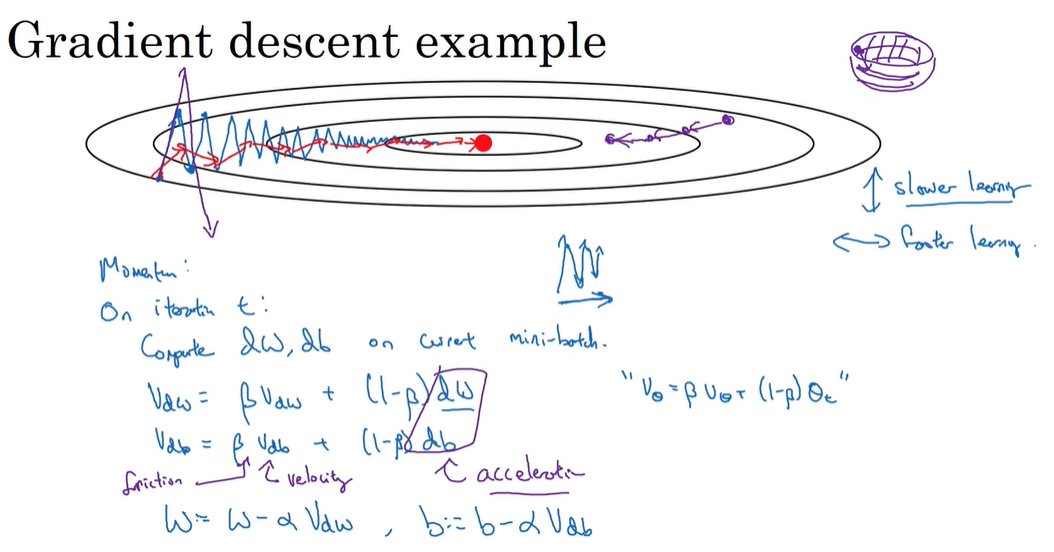
-
RMSprop(root mean square prop)允许我们使用一个较大的学习率
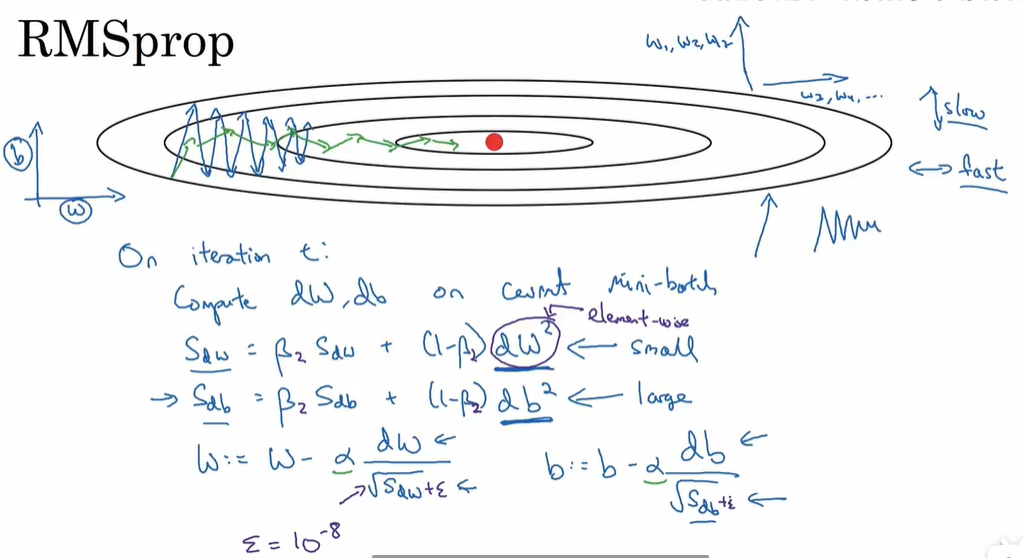
-
Adam==(RMSporp和Momentum的结合)推荐使用==

一般设置参数如下:
α 调 试 β 1 = 0.9 β 2 = 0.999 ε = 1 0 − 8 \alpha 调试\\ \beta1= 0.9\\ \beta2= 0.999\\ \varepsilon = 10^{-8} α调试β1=0.9β2=0.999ε=10−8 -
学习率衰减
- 方法一: α = α 0 1 + d e c a y r a t e ∗ e p o c h n u m \alpha = \frac{\alpha0}{1 + decayrate * epochnum} α=1+decayrate∗epochnumα0
- 方法二: α = 0.9 5 e p o c h n u m ∗ α 0 \alpha = 0.95^{epochnum}*\alpha0 α=0.95epochnum∗α0
- 方法三:离散衰减
- 方法四:手动衰减
-
局部最优问题(优化算法面临的问题)
三、超参数调试
-
超参数的重要性排序:红色最重要,接着黄色,接着紫色Adma参数不用调

随机均匀选择点

-
为超参数选择合适的范围
- 区间两端点在同一量级则均匀随机选择
- 区间两端点在不同量级,则取对数


-
超参数搜索过程
- 资源少硬件差:在一个模型上尝试
- 硬件强:多个模型参数并行

-
Batch 归一化
对于逻辑回归:数据归一化为正态分布
对于深度神经网络:对神经网络的隐藏层也要优化
对于输入单元你想让平均值为0方差为1,对于隐藏层单元可以通过设置参数 γ , β \gamma,\beta γ,β得到合适的分布

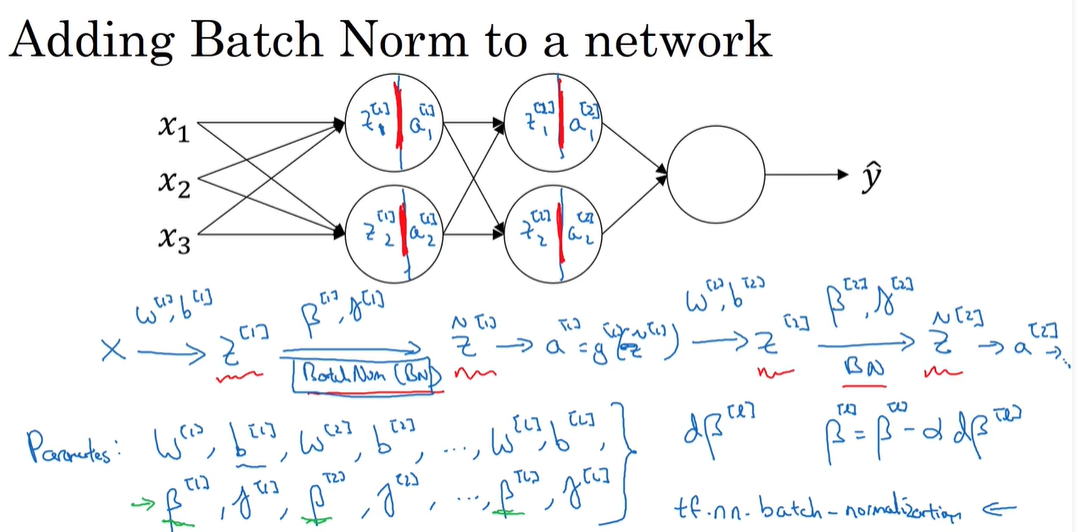


- 为什么batch norm有用?
- 加快网络训练
- 减少了输入值改变的问题,使这些值变得更稳定,后层网络更独立于前层参数
- 类似于Dropout,有稍微轻微的正则化作用

- 为什么batch norm有用?
-
softmax回归(完成多分类)
特殊之处:输入一组数,输出一组数,其他激活函数都是输入一个数,输出一个数
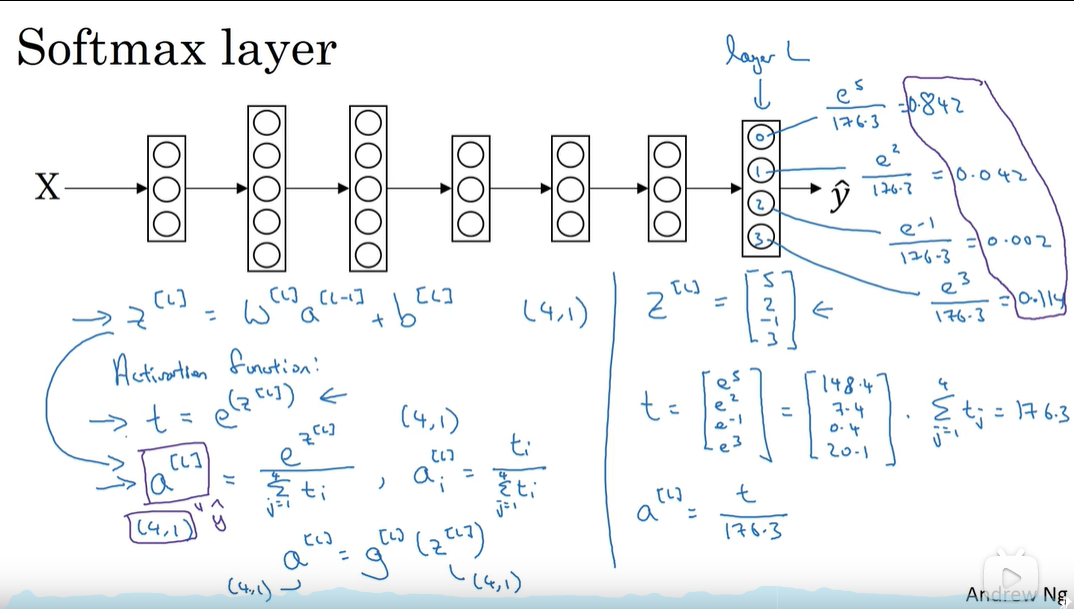
怎么训练带有softmax的模型 -
深度学习框架:(只需将正向传播写出,会自动求出反向传播)

-
tensorflow(会画出计算图)

(三)机构化机器学习项目
一、ML策略(一)
可以调节的参数太多,怎么提高效率
-
正交化:每调节一个参数,只对一个方面造成影响,不然调节很困难

-
单数字评估指标:
机器学习,你有一个idea,然后实现它,最后进行评估,评估时要使用一个指标衡量哪个模型好,而不是多个指标
-
怎么设计这个单评估指标呢?
满足和优化指标:共N个指标,对一个指标进行优化,对于另外N-1个指标只要满足不等式条件(即设置一个门槛)就不考虑它的具体大小。
-
-
训练、开发、测试集的划分:
测试集和验证集要有相同的分布

大小比例:
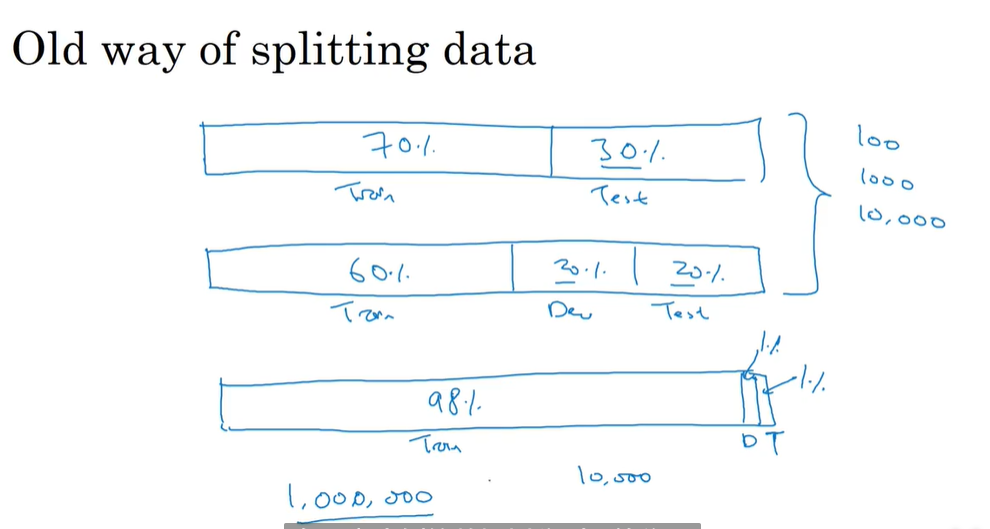
对于test set 的大小,我们有时候不需要对系统有置信度很高的评价,甚至不单独分出测试集也是可以的
-
改变指标:
对原来的指标评估的模型不满意要重新设计指标

-
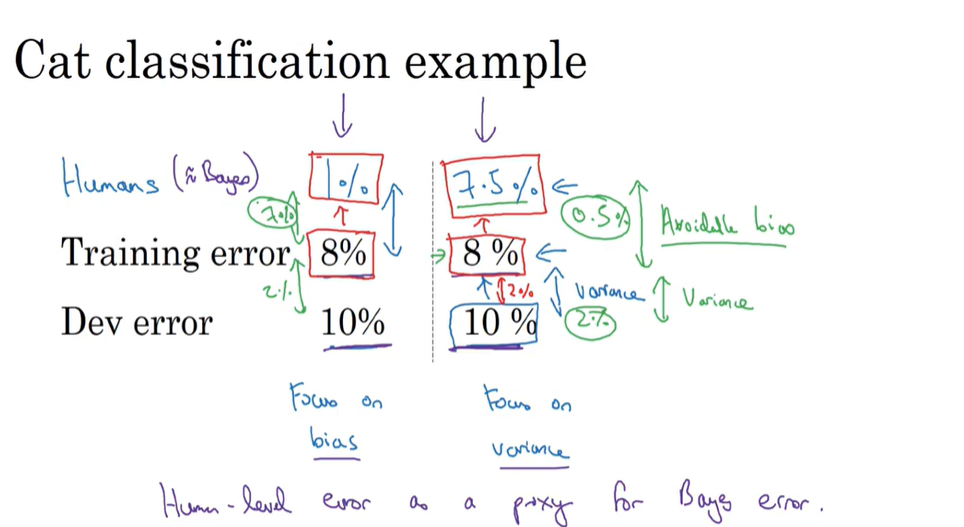
可避免方差:(人类标记误差约等于贝叶斯方差),看出是高bias还是高variance,从而调节参数。
-
理解人的表现

越接近人类水平越难 -
超过人类的表现:
在超过人的表现时,进展越来越慢

目前,超过人类的方面主要是有结构化数据,计算机视觉等非结构化数据的领域表现有待提高(即自然感知任务)
二、ML策略(二)
-
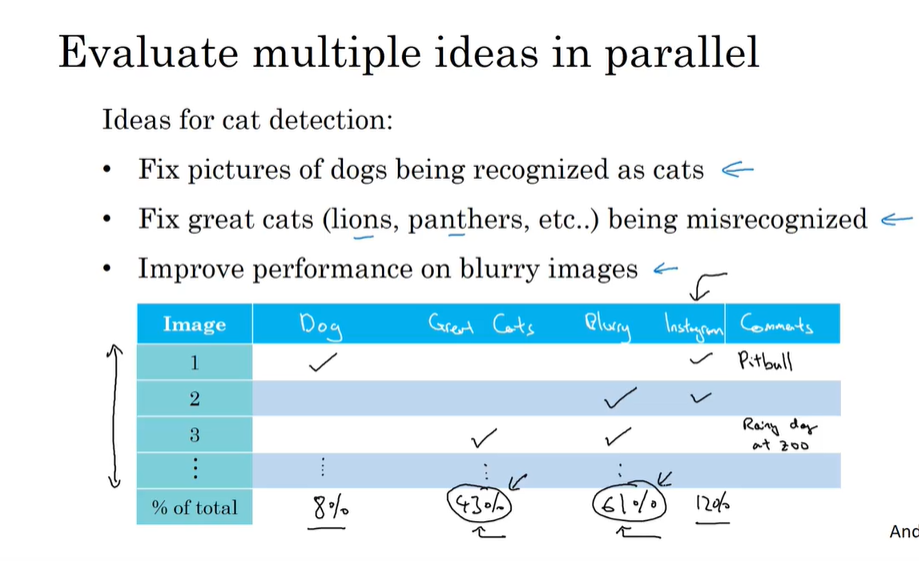
误差分析(虽然费时间,但很有必要。要迅速分析哪个方向是有希望的,不要玄学调参)
如果你模型的准确率不高,查看100张你分错的图片分析问题
-
清楚标记错误的数据
如果数据集很大则基本不需要修正标签,还是进行错误分析,看是否值得

-
如果值得怎么修改呢?

-
-
快速搭建你的机器学习系统,然后不断迭代,不断改进
-
在不同的划分上训练并测试:

-
不匹配数据划分的偏差(训练,验证,测试集来自不同的分布)
如果训练集和测试集来自不同的分布,而你训练好的模型在测试集上偏差不大,而在验证集上有较大偏差,则不能放心的说high variance。因为此时有两个变量:- 只见过测试集没见过开发集
- 而开发数据集还来自不同的分布


-
解决数据不匹配问题
-
人工分析理解测试,验证,训练集的不同
-
训练更多相似于验证集和测试集的数据,那数据怎么来呢,可以人工合成数据(加入一些噪音)
合成时注意过拟合问题,因为人类看起来很逼真,但实际不行
-
-
迁移学习(深度学习强大的地方可以将一个地方学到的知识应用于另外的地方,但你别期望效果有多好)
应用于:原问题有很多数据,而迁移目标问题的数据量不多
做法:重新训练神经网络的最后一层参数,甚至可以加几层用于训练。
好处:训练更快,数据量需求小
预训练和微调的概念:
例子:图像识别应用于医疗放射科任务
-
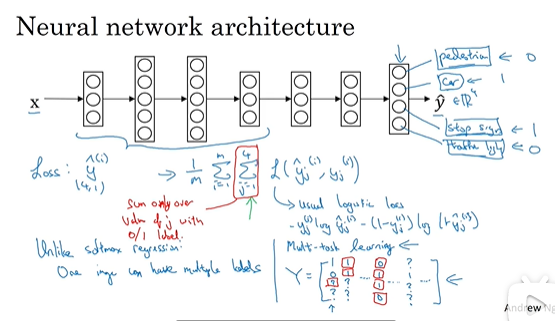
多任务许学习
(并行,试图让单个神经网络同时做几件事,每个任务都能帮助到其他任务,只要你的神经网络足够强大,就不会降低性能)例如:无人驾驶 ,同时要看,有没有行人,有没有车,有没有红绿灯,有没有交通标志,与softmax不同,不是只给图像一个标签,它要在一张图片上同时识别人、车、红绿灯、交通标志。
应用:目标检测
-
端到端的深度学习(end-to-end deep learning):让数据说话,减少手工组件
最大挑战:需要大量数据
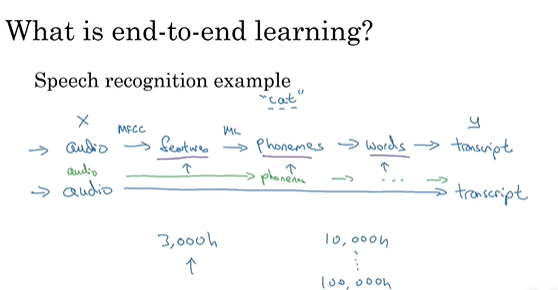
例子:门禁的人脸识别系统:先检测到人脸,放大剪裁人脸图像放到神经网络(没有足够数据时的做法)

- 你设计的可能不好,让算法自己找到更好的表示方法

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)