spark性能调优 | 默认并行度
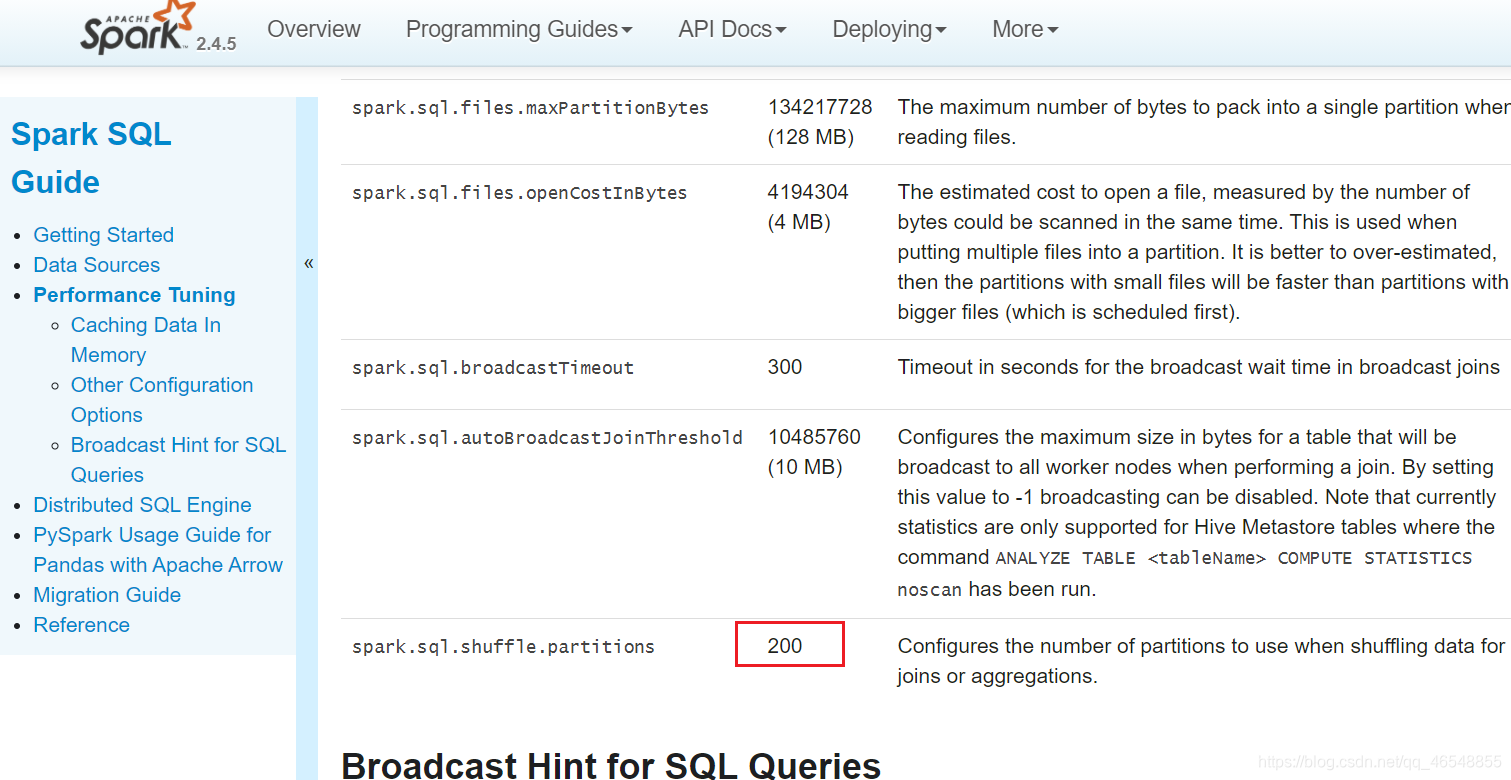
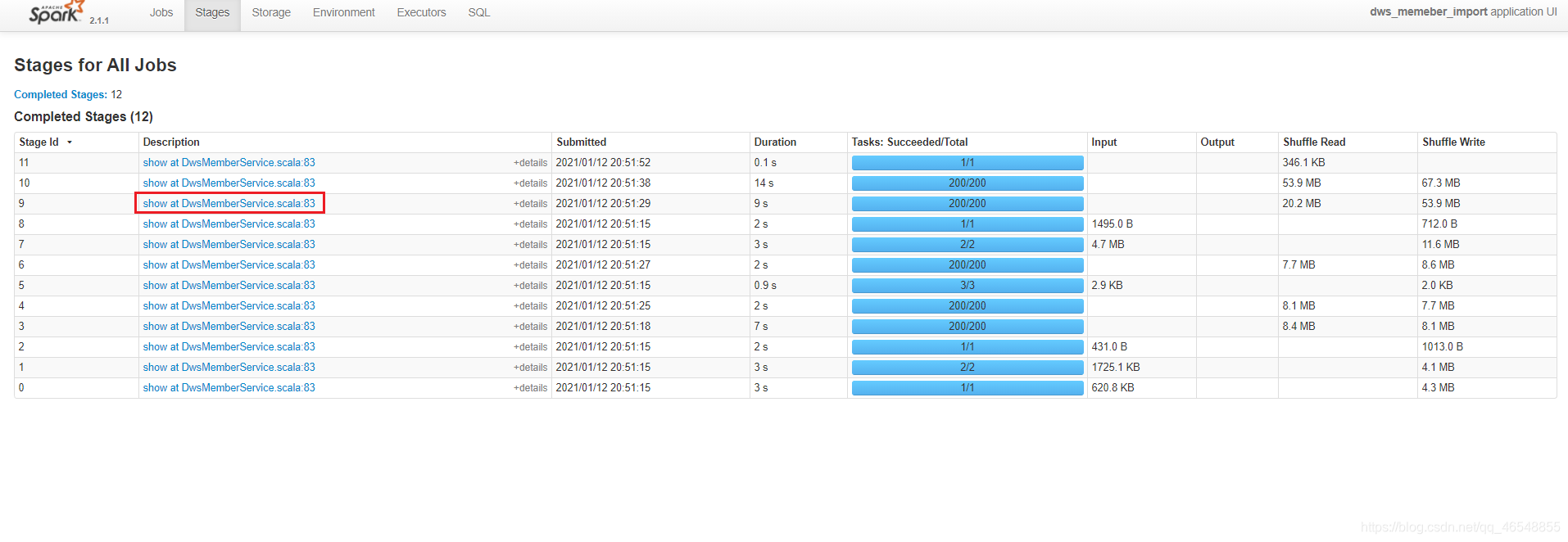
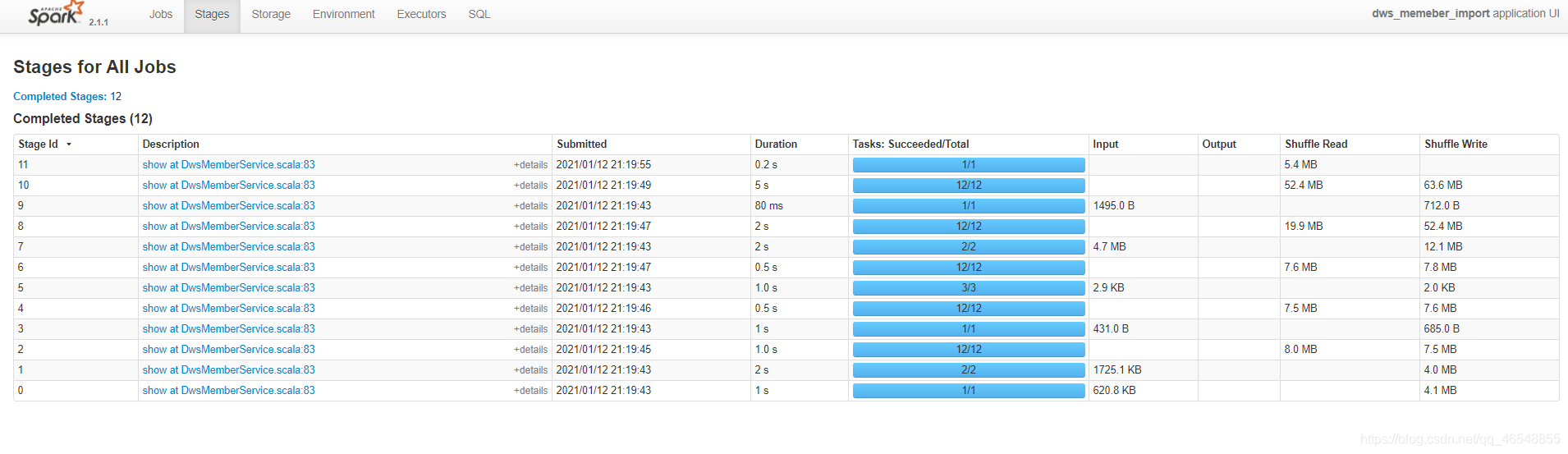
去向yarn申请的executor vcore资源个数为4个(num-executors*executor-cores),如果不修改spark sql分区个数,那么就会像上图所展示存在cpu空转的情况。这个时候需要合理控制shuffle分区个数。如果想要让任务运行的最快当然是一个task对应一个vcore,但是数仓一般不会这样设置,为了合理利用资源,一般会将分区(也就是task)设置成vcore的
·
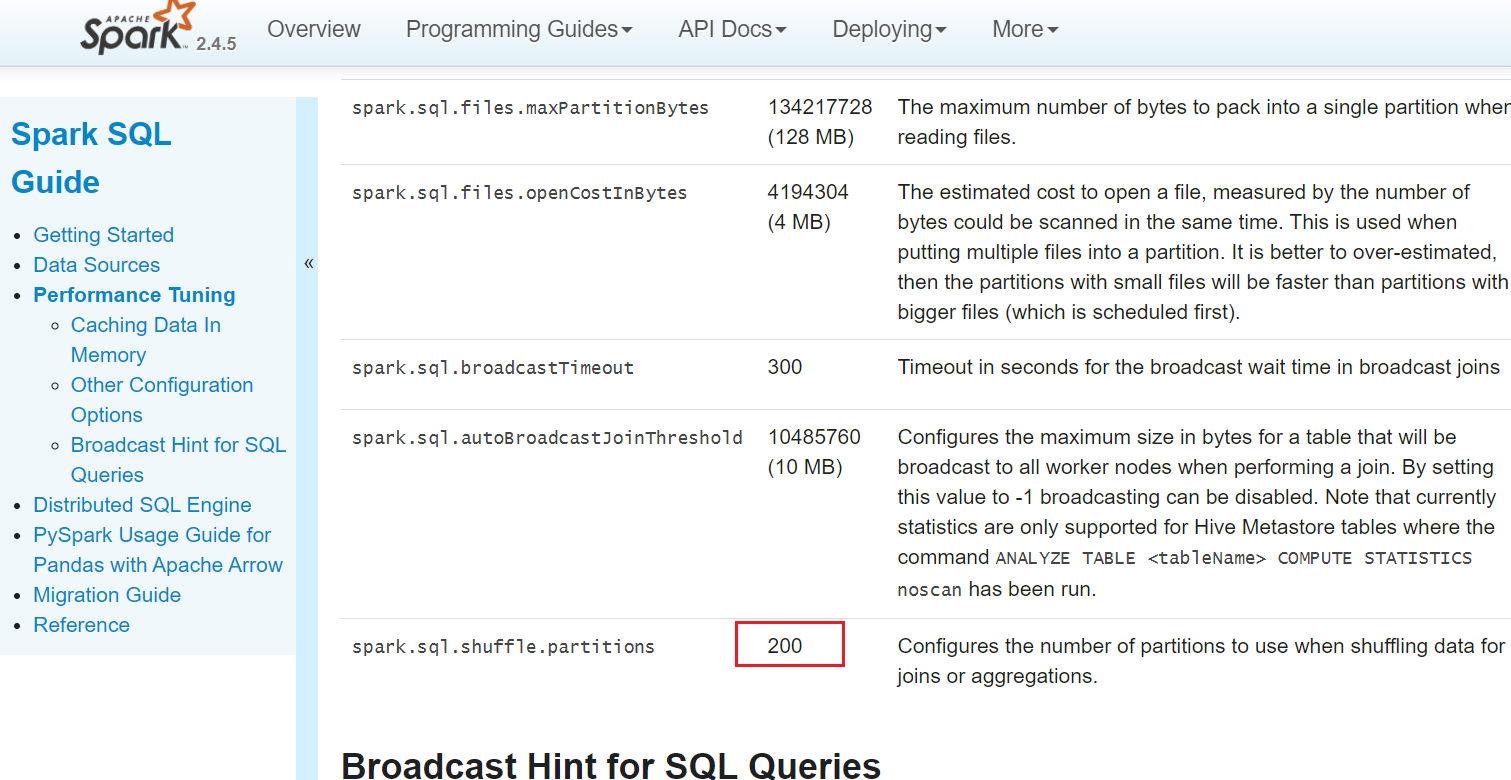
Spark Sql默认并行度
看官网,默认并行度200
https://spark.apache.org/docs/2.4.5/sql-performance-tuning.html#other-configuration-options

优化
在数仓中 task最好是cpu的两倍或者3倍(最好是倍数,不要使基数)
拓展
在本地 task需要自己设置,cpu就是local[x] x就代表cpu数
在yarn --num-executors 2 --executor-cores 2相乘就代表你的cpu个数
根据提交命令
spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--num-executors 2 \
--executor-cores 2 \
--executor-memory 2g \
--queue spark \
--class com.donglin.sparksqltuning.PartitionTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
去向yarn申请的executor vcore资源个数为4个(num-executors*executor-cores),如果不修改spark sql分区个数,那么就会像上图所展示存在cpu空转的情况。这个时候需要合理控制shuffle分区个数。如果想要让任务运行的最快当然是一个task对应一个vcore,但是数仓一般不会这样设置,为了合理利用资源,一般会将分区(也就是task)设置成vcore的2倍到3倍。
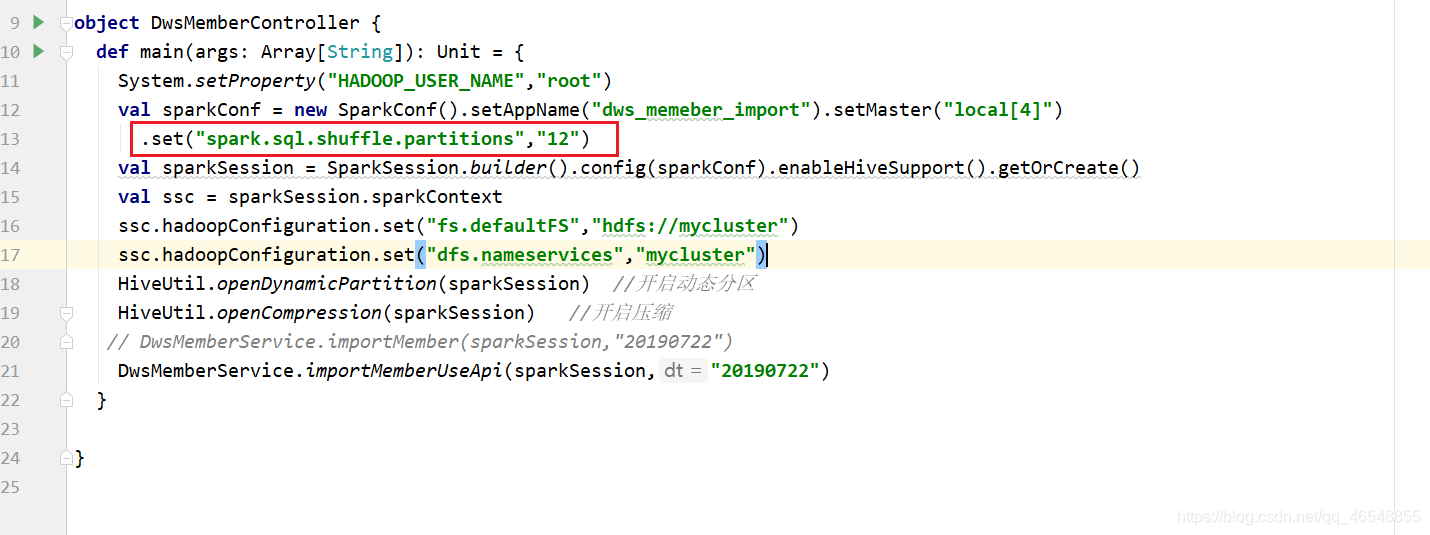
可以看出,时间快了不少!(这个需要多次调试,找出最优)

鲲鹏展翅 立根铸魂 深耕行业数字化
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)