深度学习总结
入职学习了一段时间也该有个总结了吧。深度学习一、深度学习框架TensorFlow、Pytorch、Caffe、Paddle、MXNet、Kera二、网络层级结构卷积神经网络只是针对图像起到一个特征提取器的作用。1、输入层2、卷积层卷积层是卷积神经网络的核心,而卷积又是卷积层的核心。卷积我们可以直观的理解为两个函数的一种运算,这种运算称为卷积运算。输入和卷积核都是张量,卷积运算就是用卷积分别乘以输入
入职学习了一段时间也该有个总结了吧。大部分内容收集与网上,自己整理。
深度学习
一、深度学习框架
TensorFlow、Pytorch、Caffe、Paddle、MXNet、Kera
二、网络层级结构
卷积神经网络只是针对图像起到一个特征提取器的作用。
1、输入层
2、卷积层
卷积层是卷积神经网络的核心,而卷积又是卷积层的核心。卷积我们可以直观的理解为两个函数的一种运算,这种运算称为卷积运算。
输入和卷积核都是张量,卷积运算就是用卷积分别乘以输入张量中的每个元素,然后输出一个代表每个输入信息的张量。其中卷积核又被称为权重过滤器,也可以称为过滤器。
卷积核,是整个卷积过程中的核心,比较简单的卷积核有Horizontalfilter、verticalfilter、soblfilter。这些过滤器能够检测图像的水平边缘、垂直边缘、增强图片中心区域权重等。过滤器类似标准神经网络中的权重矩阵W,W需要通过梯度下降算法反复迭代求得。同样,过滤器也是需要通过模型训练来得到。
当输入图片与卷积核不匹配或者卷积核超过图片边界时,可以采用边界填充的方法。即,把图片尺寸进行扩展,扩展区域补0。也可以选择不扩展。在扩展中可以选择same以及valid。在实际的训练中选择Same。
①、标准卷积
这是我们最常用的卷积,连续紧密的矩阵形式可以提取图像区域中相邻像素之间的关联性,例如一个3X3的卷积核可以获得3X3的感受野。如下图所示:

②、空洞卷积
空洞卷积又可以称为扩张卷积。
诞生背景,在图像分割领域,图像输入到CNN(典型的网络比如FCN[3])中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(upsampling一般采用deconv反卷积操作,deconv可参见知乎答案如何理解深度学习中的deconvolution networks?),之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),©图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割[3]、语音合成WaveNet[2]、机器翻译ByteNet[1]中。简单贴下ByteNet和WaveNet用到的dilated conv结构,可以更形象的了解dilated conv本身。
FCN([1411.4038] Fully Convolutional Networks for Semantic Segmentation):Fully convolutional networks,顾名思义,整个网络就只有卷积组成,在语义分割的任务中,因为卷积输出的feature map是有spatial信息的,所以最后的全连接层全部替换成了卷积层。
Wavenet(WaveNet: A Generative Model for Raw Audio):用于语音合成。
③、分组卷积
普通的卷积过程如下图,这里显式地显示通道数,输入为H×W×c1,共有c2个h×w×c1的滤波器,经过卷积后,输出为H×W×c2。

接下来是分组卷积,这里group=2,即图中的g=2,可以看出,输入的c1个通道,被分为2组,每组为H×W×c1/2,卷积滤波器变成了2组,每组c2/2个大小为h×w×c1/2的滤波器,所以共有c2个h×w×c1/2的滤波器,每组中的每个滤波器只与前一层的一半特征图进行卷积。因此滤波器的参数数量(黄色)正好是对应正常卷积层的一半。

举个例子:比如input大小为H×W×32,通道数c1=32,想要得到output的通道数c2=64,当group是1时,要经过64个3×3×32滤波器,那么该卷积层的参数个数是64×3×3×32,即64个3×3×32大小的滤波器,pytorch中写法如下。

如果把group设置为2,要么每个滤波器的channel=c1/g=32/2=16,需要64个3×3×16大小的滤波器,滤波器分成两组,每组32个3×3×16,input也被分成两组,每组的shape为H×W×16,每组做卷积运算,得到两组H×W×32,做拼接,得到H×W×64的output。参数个数是64×3×3×16,减少了一半。

注意:groups的值必须能被in_channels和out_channels整除,否则会报错。
优点:
减少参数量。
有时候可以起到正则化的作用。
④、可变形卷积
标准卷积中的规则格点采样是导致网络难以适应几何形变的“罪魁祸首”。为了削弱这个限制,研究员们对卷积核中每个采样点的位置都增加了一个偏移的变量。通过这些变量,卷积核就可以在当前位置附近随意的采样,而不再局限于之前的规则格点。这样扩展后的卷积操作被称为可变形卷积(deformable convolution)。
代表模型:Deformable Convolutional Networks(Deformable Convolutional Networks):暂时还没有其他模型使用这种卷积,期待后续会有更多的工作把这个idea和其他视觉任务比如检测,跟踪相结合。
⑤、可分离卷积
深度可以分离卷积是讲卷积过程分为Depthwise Convolution与Pointwise Convolution进行。
Depthwise Convolution其实就是分组卷积的分组数跟input_features的channel数一样的时候,然后一个卷积核负责一个通道,一个通道只被一个卷积核卷积(拿分组卷积中的例子来说的话,就是分为12组)。

Depthwise Convolution(深度卷积)完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution(逐点卷积)中的kernel[K, N, 1, 1], 这里K的大小跟上一层的通道数是一致的,实现了深度方向的加权组合。pointwise convolution就是1*1的卷积,可以看做是对那么多分离的通道做了个融合。

代表模型:Xception(Xception: Deep Learning with Depthwise Separable Convolutions)
⑥、转置卷积
转置卷积又称为反卷积(Deconvolution),它和空洞卷积的思路刚好相反,是为上采样而生的,也应用于语义分割当中,而且它的计算也和空洞卷积刚好相反,先对输入的feature map间隔补0,卷积核不变,然后使用标准的卷积进行计算,得到更大尺寸的feature map。

3、激励层
激励层 Activation Function Layer:将卷积层的输出结果做一次非线性映射,即激活。
①、sigmoid
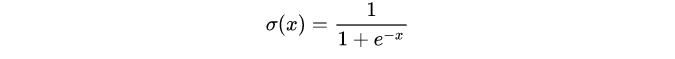

sigmoid激活函数也叫作logistic函数,用于隐藏层输出,输出在(0,1)之间, 它可以讲一个实数映射到(0,1)的范围内,可以用来做二分类,常常用于特征相差比较复杂,或是相差不是特别大的时候效果比较好。
优点:①易于求导
②simoid函数的输出映射在(0,1)之间,单调连续,
缺点:由于其软饱和性,一旦输入数据落入饱和区,一阶导数变得接近0,就有可能产生梯度消失问题。
其输出没有以0为中心。因为如果输入神经元的数据总是正数,那么关于ω的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数,这样会导致梯度下降权重更新时出现z字型的下降。
②、tanh
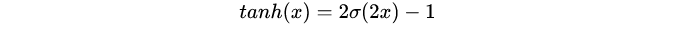

tanh曲线:也称为双切正切曲线,取值范围为[-1,1],tanh在特征相差明显的时候效果会好,在循环过程中,会不断的扩大特征效果,与Sigmoid函数相比,tanh是0均值的,因此实际应用中,tanh要比sigmoid函数更好。
Tanh函数的优点:1.收敛速度比Sigmoid函数快。 2. 其输出以0为中心。
缺点:还是出现软饱和现象,梯度消失问题并没有解决。
为了防止饱和,现在主流的做法会在激活函数之前多做一步batch normalization,尽可能保证每一层网络的输入具有均值较小的、零中心的分布。
③、ReLU
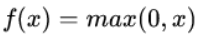

由图可以看出,输入信号在小于0的时候,输出都是0,输入信号大于0的时候,输出等于输入。
优点:
①、在SGD(随机梯度下降算法)中收敛的速度够快。
②、不会出现像sigmoid那样梯度消失的问题
③、提供了网络稀疏表达能力
④、在无监督训练中也有良好的表现
缺点:
①、不以0为中心
②、前向传导(forward pass)过程中,如果x<0,则神经元保持非激活状态,且在后向传导(backward pass)中【杀死】梯度。这样权重就无法得到更新,网络无法学习。神经元死亡是不可逆的。这样导致数据多样化丢死。通过合理设置学习率,会降低神经元【死掉】的概率。
④、Leaky ReLU
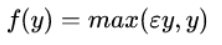

其中ε是很小的负数梯度值,比如0.01,这样做的目的是使负轴信息不会全部丢失,解决了ReLu神经元死掉的问题。更进一步的方法是PReLU,即把ε当做每个神经元中的一个参数,是可以通过梯度下降求解的。
⑤、ELU
⑥、SELU
4、池化层
实施池化层的目的为:
(1)降低信息冗余(2)提升模型的尺度不变性、旋转不变性(3)防止过拟合
①、平均池化
在钱箱传播的过程中,计算图像区域中的均值作为该区域池化后的值,在反向传播过程中,梯度特征均匀分配到各个位置。
在实际应用中,均值池化往往以全局均值池化的形式出现,常见于SE模块以及分类模块中。极少见于作为下采样模块用于分类网络中。
均值池化的优点在于可以减小估计均值的偏移,提升模型的鲁棒性。
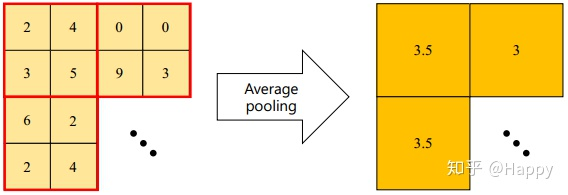
// 摘选自caffe并稍加修改.
top_data = 0;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
top_data[ph * pooled_width_ + pw] += bottom_data[h * width_ + w];
}
}
top_data[ph * pooled_width_ + pw] /= pool_size;
②、最大池化
在前向过程,选择图像区域中的最大值作为该区域池化后的值,在后向过程中,梯度通过前向过程时的最大值反向传播,其他位置的梯度为0。
在实际应用中,最大值池化又分为:重叠池化和非重叠池化。如AlexNet/GoogLeNet系列中采用的重叠池化,VGG中才用的非重叠池化。但是,在R二十Net之后,池化层在分类网络中应用逐渐减少,往往采用stride=2的卷积替代最大值池化层。
最大值池化的优点在于它能学习到图像的边缘和纹理结构。
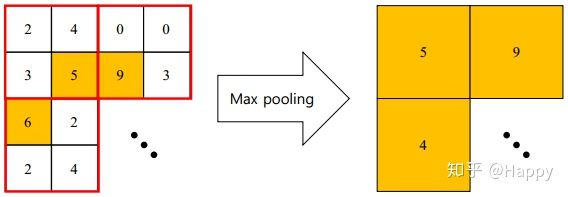
// 摘选自caffe并稍加修改.
top_data = -FLT_MAX;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
const int index = h * width_ + w;
if (bottom_data[index] > top_data[pool_index]) {
top_data = bottom_data[index];
}
}
}
③、随机池化
随机池化的方法非常简单,只需对特征区域元素按照其概率值大小随机选择,元素值大的被选中的概率也打。随机位置池化则继承了随机池化和最大值池化两者。

④、全局平均池化
将特征图所有像素值相加求平均,得到一个数值,即用该数值表示对应特征图。
目的是为了取代全连接层
优点:减少了参数数量,减小计算量,减小过拟合。
思路:如下图所示,假设最终分成10类,则最后卷积层应该包含10个滤波器(即输出10个特征图),然后按照全局池化平均定义,分为对每个特征图,累加所有像素值并求平均,最后得到10个数值,将这10个数值输入到softmax层中,得到10个概率值,即这张图片属于每个类别的概率值。

意义:对整个网络从结构上做正则化防止过拟合,剔除了全连接层黑箱子操作的特征,直接赋予了每个channel实际的类别意义。
5、上采样层
①、双线行插值
②、转置卷积(反卷积)
③、反池化
6、全连接层
三、权重&学习率策略
1、权重w初始化
神经网络在训练的过程中的参数的学习是基于梯度下降算法进行优化的。梯度下降法需要在开始训练时给每个参数赋予一个初始值,这个初始值的选取是十分重要的
①、零初始化
这样初始化,在第一遍的前向传播的过程中,所有隐藏层神经元的激活函数值都相同,导致深层神经元可有可无,这一现象称为对称权重现象。
②、随机初始化
为了打破零初始化的产生的问题,比较好的方法是对每层的权重都进行随机初始化,这样使得不同层的神经元之间有很好的区分性,但是,随机初始化参数的一个问题是如何选择随机初始化的区间。如果权重初始化太小,会导致神经元的输入过小,随着层数的不断增加,会出现信号消失的问题,也会导致sigmoid激活函数失去非线性能力,因为在0附近sigmoid函数近似是线性的。如果参数初始化太大,会导致输入状态太大,对于sigmoid激活函数来说,激活函数的值会变得饱和,从而出现梯度消失的问题。
③、Xavier初始化
当网络使用logistic激活函数时,Xavier初始化可以根据每层的神经元数量来自动计算初始化参数的方差。
④、He初始化
⑤、预训练初始化
⑥、常见的参数初始化方法:
a、高斯分布初始化:参数从一个固定均值(比如0)和固定方差(比如0.01)的高斯分布进行随机初始化
b、均匀分布初始化,在一个给定的区间【-r,r】内采用均匀分布来初始化参数。超参数r的设置可以按照神经元的连接数量进行自适应的调整。
c、初始化一个深层神经网络时,一个比较好的初始化策略是保持每个神经元的输入和输出的方差一致。
①uniform均匀分布初始化:
w=np.random.uniform(low=-sacle,high=scale,size=[Nin,Nout])
②Xavier初始化,适用于普通激活函数(tanh,sigmoid)
scale=np.sqrt(3/n)
③He初始化,适用于ReLU:
scale=np.sqrt(6/n)
④noramal高斯分布初始化,其中stdev为高斯分布的标准差,均值为0:
w=np.random.randn(Nin,Nout)*stdev
⑤Xavier初始法,适用于普通激活函数(tanh,sigmoid):
stdev=np.sqrt(n)
⑥He初始化,适用于ReLU:
stdev=np.sqrt(2/n)
⑥svd初始化:对RNN有比较好的效果。参考论文:
https://arxiv.org/abs/1312.6120[8]
2、学习率alpha调整
学习率是机器学习中一个重要参数,对loss的收敛速度和准确性有重要的影响,在深度学习中它一般需要动态调整。其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值,合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
①、指数衰减
学习率按照训练轮数增长指数差值递减

这种衰减方式简单直接,收敛速度快,是最常用的学习率衰减方式,对应公式为:
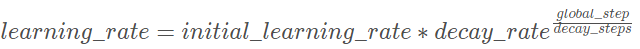
首先定义一个优化器
optimizer_ExpLR = torch.optim.SGD(net.parameters(), lr=0.1)
#定义优化器之后,就可以给这个优化器绑定一个指数衰减学习率控制器
ExpLR = torch.optim.lr_scheduler.ExponentialLR(optimizer_ExpLR, gamma=0.98)
其中参数gamma表示衰减的底数,选择不同的gamma值可以获得幅度不同的衰减曲线,如下:

②、固定步长衰减
学习率每隔一定步数(或者epochs)就减少为原来的gamma分之一,使用固定步长衰减依旧先定义优化器,再给优化器绑定StepLR对象:
optimizer_StepLR = torch.optim.SGD(net.parameters(), lr=0.1)
StepLR = torch.optim.lr_scheduler.StepLR(optimizer_StepLR, step_size=step_size, gamma=0.65)
其中gamma参数表示衰减的程度,step_size参数表示每隔多少个step进行一次学习率调整,下面对比了不同gamma值下的学习率变化情况:

③、多步长衰减
上述固定步长的衰减的虽然能够按照固定的区间长度进行学习率更新,但是有时我们希望不同的区间采用不同的更新频率,或者是有的区间更新学习率,有的区间不更新学习率,这就需要使用MultiStepLR来实现动态区间长度控制:
optimizer_MultiStepLR = torch.optim.SGD(net.parameters(), lr=0.1)
torch.optim.lr_scheduler.MultiStepLR(optimizer_MultiStepLR,
milestones=[200, 300, 320, 340, 200], gamma=0.8)
其中milestones参数为表示学习率更新的起止区间,在区间[0. 200]内学习率不更新,而在[200, 300]、[300, 320]…[340, 400]的右侧值都进行一次更新;gamma参数表示学习率衰减为上次的gamma分之一。其图示如下:

从图中可以看出,学习率在区间[200, 400]内快速的下降,这就是milestones参数所控制的,在milestones以外的区间学习率始终保持不变。
④、余弦退火衰减
严格的说,余弦退火策略不应该算是学习率衰减策略,因为它使得学习率按照周期变化,其定义方式如下:
optimizer_CosineLR = torch.optim.SGD(net.parameters(), lr=0.1)
CosineLR = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_CosineLR, T_max=150, eta_min=0)
其包含的参数和余弦知识一致,参数T_max表示余弦函数周期;eta_min表示学习率的最小值,默认它是0表示学习率至少为正值。确定一个余弦函数需要知道最值和周期,其中周期就是T_max,最值是初试学习率。下图展示了不同周期下的余弦学习率更新曲线:

四、损失函数
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
1、zero one loss(0-1损失函数)
0-1损失是指预测值和目标值不相等为1,反之为0:
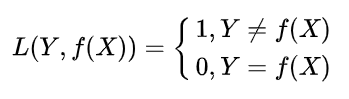
特点:
①、0-1损失函数直接对应分类判断错误的个数,但是它是一个非凸函数,不太适用。
②、感知机就是用的这种损失函数。但是相等这个条件太过严格,因此可以放宽条件,即满足
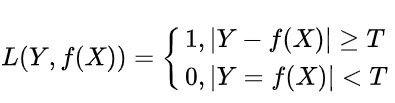
2、cross entropy loss(交叉熵损失函数)
交叉熵损失函数的标准形式如下:
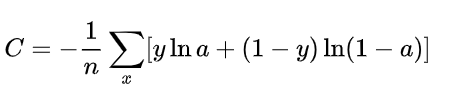
其中公式中x表示样本,y表示实际的标签,a表示预测的输出,n表示样本总数量。
特点:
①、本质上也是一种对数似然函数,可用于二分类和多分类任务中。
二分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):
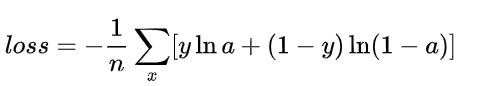
多分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出)
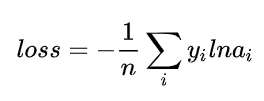
②、当使用sigmoid作为激活函数的时候,常使用交叉熵损失函数而不用均方误差损失函数,因为他可以完美解决平方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快,误差小的时候,权重更新慢”的良好性质。
3、mse loss(均方误差)
均方误差指的是模型预测值f(x)与样本真实值y之间距离平方的平均值。其公式如下:
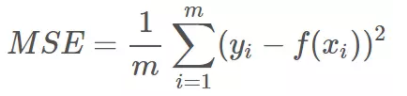
4、Logistic loss
5、focal loss
focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题,该损失函数降低了大量简单负样本在训练中所占的权重,也可以理解为一种苦难样本挖掘。
6、center loss
为每一个类别提供一个类别中心,最小化min-batch中每个样本与对应类别中心的距离,这样就可以达到缩小类内距离的目的。
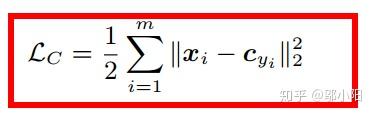
cyj就是每个这个batch中每个样本对应的类别中心,它和特征x的维度一样,对相关变量求导如下:

值得注意的是,在进行类别中心的求导时,只用当前batch中某一类别的图片来获得该类别中心的更新量。即每一个类别中心的变化只用属于这个类别的图片特征来计算。
训练是softmax loss结合center loss进行联合训练的,loss的权重为lambda.
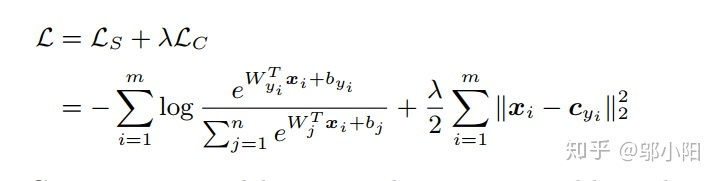
7、wing loss
应用于人脸关键点检测
8、dice loss
应用于医学影像分割
9、hinge loss
Hinge损失函数标准形式如下:

特点:
①、hinge损失函数表示如果被分类正确,损失为0,否则损失就位1-yf(x)。SVM就是使用这个损失函数
②、一般的f(x)是预测值,在-1到1之间,y是目标值(-1或1)。其含义是,f(x)的值在-1和+1之间就可以了,并不鼓励|f(x)|>1,即并不鼓励分类器过度自信,让某个正确分类的样本距离分割线超过1并不会有任何奖励,从而使分类器可以更专注整体的误差。
③、健壮性相对比较高,对异常点、噪声不敏感,但它没太好的概率解释。
10、arcface loss
五、优化算法
1、BGD(批量梯度下降法)
最小化所有训练样本的损失函数,是得最终求解的是全局的最优解,即求解的参数是是得风险函数最小,但是对于大规模样本问题效率低下。
优点:全局最优化
缺点:计算量大,迭代速度慢
2、SGD(随机梯度下降法)
随机梯度下降法,每次更新,只能使用一个样本,因此,它的速度比较快。但是由于是随机抽取一个,训练样本可能出现相似或重复,而且单个样本数据之间可能差别比较大,这就可能导致每一次训练时,代价函数出现较大的波动。
最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都想着全局最优方向,但是大的整体的方向是全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
优点:①:训练速度快②:支持在线学习
缺点:①:准确度下降②:有噪音,非全局最优化
3、MBGD(小批量梯度下降法)
每次训练时用训练集的一部分或一小批,既不是所有数据集也不是单个样本。
优点:①:可以使用深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效
②:支持在线学习
缺点:精确度不如BGD,非全局最优解
4、Momentum(动量算法)
梯度下降法在遇到平坦或者高区率区域时,学习过程有时很慢。利用动量算法能比较好解决这个问题。
5、 AdaGrad(自适应算法)
AdaGrad算法是通过参数来调整合适的学习率λ,能独立自动调整模型参数的学习率,对稀疏参数进行大幅度更新和对频繁参数进行小幅更新。因此,AdaGrad方法非常适合处理稀疏数据,但是可能因其累计梯度平方导致学习率过早或过量的减少所导致。
6、RMSProp(自适应算法)
RMSProp修改AdaGrad算法,为的是在非凸背景下效果更好。针对地图平方和累计越来越大的问题。RMSProp用指数甲醛的移动平均代替梯度平方和。RMSProp为使用移动平均,引入一个新的超参数p,用来控制移动平均的长度范围。
7、Adam(自适应算法)
Adam本质上是带有动量项的RMSProp,它利用梯度的一阶矩估计和二阶据估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置矫正后每一次迭代学习率都有一个确定范围。使得参数比较平稳。
8、Gradient Descent(梯度下降法)
梯度下降法是最早最简单,也是最常用的优化方法。梯度下降法实现简单,当目标是凸函数时,梯度下降法的解释全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是“最速下降法”。最速下降法越接近目标值,步长越小,前进越慢。
9、自适应算法
传统梯度下降算法对学习率这个超参数非常敏感,难以驾驭;对参数控件的某些方向也没有很好的方法。这些不足在深度学习中,因高维空间、多层神经网络等因素,常会出现平坦鞍点、悬崖等问题。
动量算法在一定程度上缓解了对参数控件某些方向的问题,但是需要新增一个参数,而且对学习率的控制还不是很理想。为了更好的驾驭这个超参数,就产生了自适应算法。
六、预处理
1、图像裁剪
①、中心裁剪
②、随机裁剪
③、随机长宽比裁剪
2、翻转和旋转
①、概率水平翻转
②、概率垂直翻转
③、随机旋转
3、图像变换
①、标准化
②、填充
③、灰度化
④、仿射变换
七、后处理
1、分类映射
2、检测NMS
NMS,称为非极大值抑制,是目标检测框架中的后处理模块,主要用于删除高度冗余的bbox。在目标检测的过程中,对于每个obj在检测的时候会产生多个bbox,NMS的本质就是对每个obj的多个bbox去冗余,得到最终的检测结果。
对于检测任务,NMS是一个必需的部件,其为对检测结果进行冗余去除操作的后处理算法,标准的NMS为手工设计的,基于一个固定的距离阈值进行贪婪聚类,即贪婪地选取得分高的检测结果并删除那些超过阈值的相邻结果,使得在recall和precision之间取得权衡。
算法的流程:
给出一张图片和上面许多物体检测的候选框(即每个框可能都代表某种物体),但是这些框很可能有重叠的部分,我们要做的就是只保留最优的框。假设有N个框,每个框被分类器计算得到的分数为Si,1<=i<=N
①、建造一个存放待处理候选框的集合H,初始化为包含全部N个框;
建造一个存放最优框的集合M,初始化为空集
②、将所有集合H中的框进行排序,选出分数最高的框m,从集合H移到集合M
③、遍历集合H中的框,分别与框M计算交并比(IOU)如果高于某个阈值(一般为0-0.5),则认为此框与m重叠,将此框从集合H中去除。
④、回到第一步进行迭代,知道集合H为空。集合M中的框为我们所需。
需要优化的参数:
IOU的阈值是一个可优化的参数,一般范围为(0-0.5),可以使用交叉验证来选择最优的参数。
八、CUDA编程,加速,模型剪枝压缩,NAS,AutoML

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)