Python3入门机器学习之2.8scikit-learn中的Scaler
Python3入门机器学习2.8 scikit-learn中的Scaler1.对测试数据如何归一化?对于我们的原始数据集我们要将它拆分成训练数据集和测试数据集,如果我们要用归一化后的数据来训练我们的模型的话,显然我们首先要对训练数据集进行归一化处理。比如说我们进行均值标准差归一化这样的方法,我们相应就要求出来我们训练数据集对应的均值mean_train,以及训练数据集对应的标准差std_train
Python3入门机器学习
2.8 scikit-learn中的Scaler
1.对测试数据如何归一化?
对于我们的原始数据集我们要将它拆分成训练数据集和测试数据集,如果我们要用归一化后的数据来训练我们的模型的话,显然我们首先要对训练数据集进行归一化处理。比如说我们进行均值标准差归一化这样的方法,我们相应就要求出来我们训练数据集对应的均值mean_train,以及训练数据集对应的标准差std_train。当我们这样归一化之后,我们将这样的训练数据集用于训练模型,最终我们要使用获得的这个模型来预测数据,那么对于测试数据集相应的也要进行归一化处理。那么现在问题来了,对于测试数据集我们如何进行归一化处理呢?可能有人就会说,把整个测试数据集求一下它的均值mean_test和标准差std_test,用这两个值对测试数据集进行归一化,然后再讲这个测试数据送给我们训练出的这个模型进行预测,不是就可以了吗?这样做是不可以的。
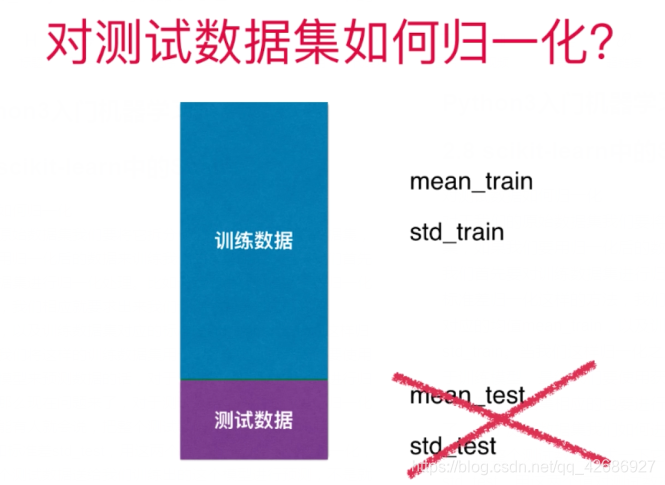
我们正确的做法应该是将我们的测试数据集使用训练数据集得到的mean_train和std_train相应的进行归一化。换句话说,我们应该用我们的测试数据集x_test去减去mean_train,然后再去除以std_train,即(x_test - mean_train) / std_train来得到均值标准差归一化的结果。为什么这样做呢?有以下几个原因:
首先最主要的原因在于,我们在这里划分出了一部分原始数据作为测试数据集,对于这个测试集我们确实很容易得到它的均值和标准差。但是不要忘记,我们训练出这个模型是为了让它使用在真实的环境中,可是很多时候在真实的环境中我们是无法得到所有的测试数据相应的均值和标准差。另外一个原因,其实将我们的数据归一化也是我们算法本身的一部分,换句话说,我们可以理解成我们的算法就包括(x_test - mean_train) / std_train,针对后面来的数据我们也应该使用同样的方式进行处理,然后来测试它的准确度,得到的才是真正的我们自己做的这个算法它对应的准确度。
所以我们需要保存训练数据集得到的均值和标准差,为了方便这一步的操作,在scikit-learn中对数据的归一化专门封装了一个类,这个类叫做Scaler。scikit-learn的封装里面想办法让这个Scaler这个类和我们的机器学习算法这个类整体的使用流程是一致的,如下图就是scikit-learn中封装的Scaler类的使用流程:

其中,fit就是求出训练数据集对应的一些统计指标,比如说对于均值标准差归一化来说,fit后就求出了训练数据集相应的均值和标准差。
2.实际操作:
(1).首先准备好数据集,仍然使用鸢尾花的数据集:
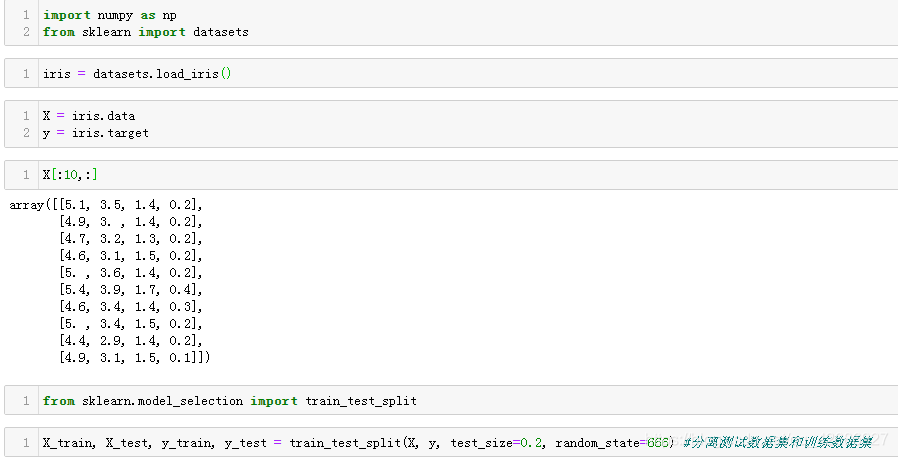
以下为使用scikit-learn中的StandardScaler对数据进行归一化处理:
(2).引入scikit-learn中的StandardScaler,调用fit()函数,根据训练数据集获得数据的均值和方差:

(3).将数据根据这个StandardScaler进行均值标准差归一化处理:


(4).最终预测分类准确度:

3.尝试自己封装StandardScaler这个类:
import numpy as np
class StandardScaler:
def __init__(self):
self.mean_ = None
self.scale_ = None
def fit(self, X):
'''根据训练数据集X获得数据的均值和方差'''
assert X.ndim == 2, "The dimension of X must be 2"
self.mean_ = np.array([np.mean(X[:,i]) for i in range(X.shape[1])])
self.scale_ = np.array([np.std(X[:,i]) for i in range(X.shape[1])])
return self
def transform(self, X):
'''将X根据这个StandardScaler进行均值标准差归一化处理'''
assert X.ndim == 2, "The dimension of X must be 2"
assert self.mean_ is not None and self.scale_ is not None, \
"must fit before transform!"
assert X.shape[1] == len(self.mean_), \
"The feature number of X must be equal to mean_ and std_"
resX = np.empty(shape=X.shape, dtype=float)
for col in range(X.shape[1]):
resX[:,col] = (X[:,col] - self.mean_[col]) / self.scale_[col]
return resX

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)