《Python数据分析与展示》讲解numpy,Matplotlib,pandas 详细笔记
第0周 Python基本语法元素conda: 一个工具,用于包管理和环境管理,其中:包管理与pip类似,管理Python第三方库环境管理能够允许用户使用不同版本Python,并能灵活切换anaconda:一个集合,包括conda、某版本Python、一批第三方库等conda将工具、第三方库、Python版本、conda都当作包,同等对待ipython第1周 数据分析之表示单元...
第0周 Python基本语法元素
conda: 一个工具,用于包管理和环境管理,其中:包管理与pip类似,管理Python第三方库环境管理能够允许用户使用不同版本Python,并能灵活切换
anaconda:一个集合,包括conda、某版本Python、一批第三方库等
conda将工具、第三方库、Python版本、conda都当作包,同等对待
- ipython



第1周 数据分析之表示
单元1 NumPy库入门
- 一维数据:由对等关系的有序或无序数据构成,采用线性方式组织
- 列表和数组:一组数据的有序结构
- 列表:数据类型可以不同
3.1413, 'pi', 3.1404, [3.1401, 3.1349], '3.1376'
- 数组:数据类型相同
3.1413, 'pi', 3.1404, [3.1401, 3.1349], '3.1376'
二维数据:由多个一维数据构成,是一维数据的组合形式
多维数据:由一维或二维数据在新维度上扩展形成
高维数据:仅利用最基本的二元关系展示数据间的复杂结构 键值对
- 数据维度的Python表示:数据维度是数据的组织形式
- 一维数据:列表和集合类型
[3.1398, 3.1349, 3.1376] 有序
{3.1398, 3.1349, 3.1376} 无序 - 二维数据:列表类型
- 多维数据:列表类型
- 高维数据:字典类型或数据表示格式来表示:JSON、XML和YAML格式
- 一维数据:列表和集合类型
dict = {
“firstName” : “Tian”,
“lastName” : “Song” ,
}
-
NumPy的数组对象:ndarray
NumPy是一个开源的Python科学计算基础库,是SciPy、Pandas等数据处理或科学计算库的基础。整合C/C++/Fortran代码的工具(运算速度快),线性代数、傅里叶变换、随机数生成等功能。 -
ndarray是一个多维数组对象,由两部分构成:
• 实际的数据
• 描述这些数据的元数据(数据维度、数据类型等) -
ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始
-
ndarray实例

-
ndarray对象的属性

- ndarray的元素类型



- ndarray数组的创建方法:
(1)从Python中的列表、元组等类型创建ndarray数组
x = np.array(list/tuple)
x = np.array(list/tuple, dtype=np.float32)
当np.array()不指定dtype时,NumPy将根据数据情况关联一个dtype类型

(2)使用NumPy中函数创建ndarray数组,如:arange, ones, zeros等


- 这里ones,zeros,eyes等生成的数组类型都是浮点数类型,arange生成的是整数类型。
- 这里的(2,3,4)表示最外层的元素中还有两个元素,每个元素有三个维度,每个维度下又有四个元素

(3)使用NumPy中其他函数创建ndarray数组


- 53行中endpoint表示的是最后一个数10是否为生成的元素中的一个
- ndarray数组的变换:
对于创建后的ndarray数组,可以对其进行维度变换和元素类型变换a = np.ones((2,3,4), dtype=np.int32)
ndarray数组的维度变换:



- 注意:reshape并不改变a,resize改变a,flatten不改变a
- ndarray数组的类型变换:new_a = a.astype(new_type)

ndarray数组向列表的转换:ls = a.tolist()

- 数组的索引和切片
索引:获取数组中特定位置元素的过程
切片:获取数组元素子集的过程
-
一维数组的索引和切片:与Python的列表类似

-
多维数组的索引:

-
多维数组的切片

-
注意:a[:,1:3,:],表示第一个维度不关心,第二个维度表示去取最外层每个元素中第一到第三不包括第三维度,第三个维度应该是取列,这里对列不关心
a[:,:, : :2]表示每个元素中每个维度都取到,列取从0开始,步长为2的全部维度
- ndarray数组的运算
-
数组与标量之间的运算作用于数组的每一个元素
-
NumPy一元函数

-
注意:ceiling表示不超过元素的整数值,floor小于这个元素的最大整数值


-
NumPy二元函数


- NumPy库入门小结

单元2 数据存取与函数
- 数据的CSV文件存取:
- np.savetxt(frame, array, fmt=’%.18e’, delimiter=None)
• frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
• array : 存入文件的数组
• fmt : 写入文件的格式,例如:%d %.2f %.18e
• delimiter : 分割字符串,默认是任何空格

用loadtxt将csv中的文件再读入的一个numpy的数组
- np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
• frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
• dtype : 数据类型,可选
• delimiter : 分割字符串,默认是任何空格
• unpack : 如果True,读入属性将分别写入不同变量

- CSV只能有效存储一维和二维数组
np.savetxt() np.loadtxt()只能有效存取一维和二维数组
- 多维数据的存取
- a.tofile(frame, sep=’’, format=’%s’)
• frame : 文件、字符串
• sep : 数据分割字符串,如果是空串,写入文件为二进制
• format : 写入数据的格式

-
注意:与csv不同,这个文件并没有包含任何的维度信息,只是将数组中的元素逐一列出

-
注意:如果没有写 sep,最后就是以二进制形式输出,二进制比别的字符更节省空间
-
从文本中还原出数据:p.fromfile(frame, dtype=float, count=‐1, sep=’’)
• frame : 文件、字符串
• dtype : 读取的数据类型
• count : 读入元素个数,‐1表示读入整个文件
• sep : 数据分割字符串,如果是空串,写入文件为二进制
-
文本文件例子

-
二进制文件例子

-
该方法需要读取时知道存入文件时数组的维度和元素类型,a.tofile()和np.fromfile()需要配合使用,可以通过元数据文件来存储额外信息。
- NumPy的便捷文件存取
- np.save(fname, array) 或 np.savez(fname, array)
• fname : 文件名,以.npy为扩展名,压缩扩展名为.npz
• array : 数组变量
- np.load(fname)
• fname : 文件名,以.npy为扩展名,压缩扩展名为.npz

- NumPy的随机数函数:np.random.*

- 随机数种子例子




-
NumPy的统计函数:np.*




-
NumPy的梯度函数:
梯度:连续值之间的变化率
np.gradient(f) 计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
- 因为二维数组中每个元素的梯度存在两个方向。

数据的存取与函数小结


单元3 实例1 图像的手绘效果
- PIL库:(PIL,Python Image Library),是一个具有强大图像处理能力的第三方库。在命令行下的安装方法: pip install pillow
from PIL import Image:Image是PIL库中代表一个图像的类(对象) - 图像的数组表示: im = np.array(Image.open(“D:/pycodes/beijing.jpg”)); print(im.shape, im.dtype)
图像是一个三维数组,维度分别是高度、宽度和像素RGB值,图像类型为unit8

-
这里的convert(‘L’)表示将a变为灰度图
-
图中的97行是必须要有的,把把数组转换为图像的类型
-
图像收回效果实例分析:对图像进行灰度化的基础上由立体效果和明暗效果堆叠而成的。灰度代表明暗变化,梯度值表示的是灰度的变化率。
-
手绘效果的几个特征:
• 黑白灰色
• 边界线条较重
• 相同或相近色彩趋于白色
• 略有光源效果 -
梯度的重构
利用像素之间的梯度值和虚拟深度值对图像进行重构
根据灰度变化来模拟人类视觉的远近程度

注意:立体效果通过修改立体深度值来体现
解题
- 根据灰度变化来模拟人类视觉的远近程度
设计一个位于图像斜上方的虚拟光源
光源相对于图像的俯视角为Elevation, 方位角为Azimuth
建立光源对个点梯度值的影响函数
运算出各点的新像素值

- 程序不是很懂????
from PIL import Image
import numpy as np
a = np.asarray(Image.open('./beijing.jpg').convert('L')).astype('float')
depth = 10. # 构建虚拟深度值,范围(0-100)
grad = np.gradient(a) #取图像灰度的梯度值
grad_x, grad_y = grad #分别取横纵图像梯度值
grad_x = grad_x*depth/100. # 对深度值进行归一化
grad_y = grad_y*depth/100.
A = np.sqrt(grad_x**2 + grad_y**2 + 1.) # 构造x和y轴梯度的三维归一化单位坐标系
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
vec_el = np.pi/2.2 # 光源的俯视角度,弧度值
vec_az = np.pi/4. # 光源的方位角度,弧度值
#np.cos(vec_el)为单位光线在地平面上的投影长度
#dx, dy, dz是光源对x/y/z三方向的影响程度
dx = np.cos(vec_el)*np.cos(vec_az) #光源对x 轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对y 轴的影响
dz = np.sin(vec_el) #光源对z 轴的影响
b = 255*(dx*uni_x + dy*uni_y + dz*uni_z) #光源归一化,梯度与光源相互作用,将梯度转化为灰度
b = b.clip(0,255)# 为避免数据越界,将生成的灰度值裁剪至0‐255区间
im = Image.fromarray(b.astype('uint8')) #重构图像
im.save('./beijingHD.jpg')
第2周 数据分析之展示
单元4 Matplotlib库入门
- Matplotlib库介绍:Python优秀的数据可视化第三方库。Matplotlib库由各种可视化类构成,内部结构复杂,受Matlab启发。matplotlib.pyplot是绘制各类可视化图形的命令子库,相当于快捷方式
-
import matplotlib.pyplot as plt
- plt.plot()只有一个输入列表或数组时,参数被当作Y轴,X轴以索引自动生成
- plt.savefig()将输出图形存储为文件,默认PNG格式,可以通过dpi修改输出质量,dpi:每一英寸空间中包含的点的数量

- plt.plot(x,y)当有两个以上参数时,按照X轴和Y轴顺序绘制数据

-注意:plt.axis([-1, 10, 0, 6])表示横坐标从-1到10,纵坐标从0到6
- plt.subplot(3,2,4)及plt.subplot(324)在全局绘图区域中创建一个分区体系,并定位到一个子绘图区域
- pyplot的plot()函数
plt.plot(x, y, format_string, **kwargs)
∙ x : X轴数据,列表或数组,可选
∙ y : Y轴数据,列表或数组
∙ format_string: 控制曲线的格式字符串,可选,由颜色字符、风格字符和标记字符组成
∙ **kwargs : 第二组或更多(x,y,format_string)
# 当绘制多条曲线时,各条曲线的x不能省略
-
画四条线

-
format_string: 控制曲线的格式字符串,可选由颜色字符、风格字符和标记字符组成



-
例子

-
plt.plot(x, y, format_string, **kwargs)
∙ **kwargs : 第二组或更多(x,y,format_string)
color : 控制颜色, color=‘green’
linestyle : 线条风格, linestyle=‘dashed’
marker : 标记风格, marker=‘o’
markerfacecolor: 标记颜色, markerfacecolor=‘blue’
markersize : 标记尺寸, markersize=20
- pyplot的中文显示
pyplot的中文显示:第一种方法
pyplot并不默认支持中文显示,需要rcParams修改字体实现

-
rcparams的属性

-
中文字体的种类


- 注意:这个例子改变的字体和字体大小时改变的全局的,一般情况下不要轻易改变全局的
pyplot的中文显示:第二种方法(推荐)
在有中文输出的地方,增加一个属性:fontproperties和fontsize就可以了

- pyplot的文本显示函数


- 框框里面文本的格式是Latex ,grid(true)表面图中加入网格曲线
- plt.annotate(s, xy=arrow_crd, xytext=text_crd, arrowprops=dict)

- annotate中xy表示箭头指向的点,xytext为解释文本的地方,arrowprops中的shrink表示箭头两端离两点中间隔开的距离
- pyplot的子绘图区域
- 复杂的绘图区域

-解释:其中第一个参数GridApec是一个元组,代表把网格分成一个3*3的区域;CurSpec表示当前选中的区域为第一行第0列;colspan表示从选定的(1,0)开始在列的方向上延伸两个长度,也就是选定长度和选定长度右边一列;向行的地方延伸用rowspan

- GridSpec类可以和subplot结合来取代subplot2grid的功能
import matplotlib.gridspec as gridspec
gs= gridspec.GridSpec(3,3) # 表明在一个区域中生成一个网格,这个网格是3*3阵列
ax1 = plt.subplot(gs[0, : ]) # 0表示第0行,后面表示覆盖所有列
ax2 = plt.subplot(gs[l, : -1]) # 行为第一行,列为0:-1不包括-1
ax3 = plt.subplot(gs[l:, -1])
ax4 = plt.subplot(gs[2, 0))
axS = plt.subplot(gs[2, 1])
单元5 Matplotlib基础绘图函数示例
-
pyplot的基础图标函数



-
pyplot饼图的绘制
import matplotlib.pyplot as plt
# labels给出了每个块对应的标签
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'
# size约束了每一块的尺寸
sizes = [15, 30, 45, 10]
# explode指出了那一块要突出来
explode = (0, 0.1, 0, 0)
# autopct表示中心显示百分数的方式,shadow是用来决定饼图是个二维的还是有阴影的
# startangle饼图起始的角度值
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=False, startangle=90)
plt.axis('equal') # 表示绘图时x,y方向的尺寸应该是相等的
plt.show()

- pyplot的直方图绘制
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
mu, sigma= 100, 20 #均值和标准差
a= np.random.normal(mu, sigma, size=100) # 生成指定的100个随机数
# hist的第二个参数bin表示直方的个数
# normed=1表示将直方图中每一个值出现的个数归一化为出现的概率
# normed=0显示每一个值出现的个数
plt.hist(a, 20, normed=1, histtype='stepfilled', facecolor='b',alpha=0.75)
plt.title ('Histogram')
plt.show()

- pyplot极坐标图的绘制
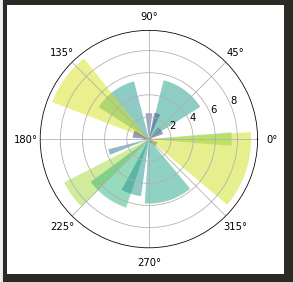
#面向对象绘制极坐标图:
import numpy as np
import matplotlib.pyplot as plt
N = 20 #数据个数
theta = np.linspace(0.0,2*np.pi,N,endpoint=False)#0-360度,按个数等分N个不同的角度
radii = 10*np.random.rand(N) # 用rand函数生成每个角度对应的值
width = np.pi/4*np.random.rand(N)
ax = plt.subplot(111,projection="polar")#一个绘图区域,绘制极坐标
#绘制起始位置,中心点向边缘绘制的长度,每个绘图区域面积
bars = ax.bar(theta,radii,width,bottom=0.0)
#修改每个绘图区的颜色,没有多讲解
for r,bar in zip(radii,bars):
bar.set_facecolor(plt.cm.viridis(r/10.))
bar.set_alpha(0.5)
plt.show()
- pyplot散点图的绘制
import numpy as np
import matplotlib.pyplot as plt
a = 100*np.random.randn(33).reshape(3,11)
# 面向对象的写法
fig, ax = plt.subplots() # 将plt.subplots()赋值给对象,此时为空说明是1*1
colors = ["#99cc01","#ffff01","#0000fe","#a6a6a6","#d91021","#fff161","#0d8ecf"
,"#fa4d3d","#d2d2d2","#ffde45","#9b59b6"]
#分别设置X轴值,Y轴值,以及第三个参数值大小来显示气泡大小
ax.scatter(a[0,:],a[1,:],s=100*a[2,:],color=colors,alpha=0.6)
#ax.plot(10*np.random.randn(100),10*np.random.randn(100),"o"),x和y轴各生成100个值
ax.set_title("随机气泡图",fontproperties = "simHei",fontsize = 16)
ax.set_xlabel("随机X值",fontproperties = "simHei",fontsize = 14)
ax.set_ylabel("随机y值",fontproperties = "simHei",fontsize = 14)
ax.grid(True)
fig.tight_layout()
plt.show()
单元6 实例2:引力波的绘制
- 概念
引力波:物理学中,引力波是因为时空弯曲对外以辐射形式传播的能量
爱因斯坦基于广义相对论预言了引力波的存在
2015年9月14日,LIGO合作组宣布探测到首个引力波信号。 2016年6月16日,LIGO合作组宣布2015年12月26日03:38:53(UTC),两台不同位置的引力波探测器同时探测到了一个引力波信号。
week3 padas
单元7 Pandas库入门
Pandas库介绍
Pandas是Python第三方库,提供高性能易用数据类型和分析工具
import pandas as pd
Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
Pandas库的理解
两个数据类型:Series, DataFrame
Series:相对于一个以为数据类型
DataFrame:相对于二维到多维的数据类型
基于上述数据类型的各类操作:基本操作、运算操作、特征类操作、关联类操作

Pandas库的Series类型
Series类型由一组数据及与之相关的数据索引组成
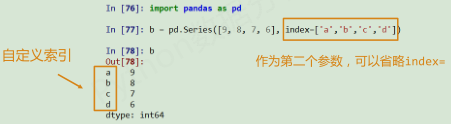
- Series类型可以由如下类型创建:
• Python列表,index与列表元素个数一致
• 标量值,index表达Series类型的尺寸

• Python字典,键值对中的“键”是索引,index从字典中进行选择操作

• ndarray,索引和数据都可以通过ndarray类型创建
• 其他函数,range()函数等

-
Series类型包括index和values两部分,操作类似ndarray类型和Python字典类型。

-
b的索引值类型就行index类型
-
Series类型的操作类似ndarray类型,因为series是基于ndarry设计的:
• 索引方法相同,采用[]
• NumPy中运算和操作可用于Series类型
• 自动索引和自定义索引并存,但是两套索引不能混用
• 可以通过自定义索引的列表进行切片
• 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
• series本身是索引加值的一种类型,对它的切片和运算全部都是生成series类型,也就是说有相关的值和值对应的索引,如果只选择其中的一个值如b[3],根据索引返回一个值,这时候就只返回值,没有索引。

-
Series类型的操作类似Python字典类型:
• 通过自定义索引访问
• 保留字in操作
• 使用.get()方法

-
124行中,保留字in不会判断自动索引,只会判断自定义索引

• a+b索引值相同的进行运算,不相同的就不进行运算,并且变为NaN这叫对齐。
- Series对象和索引都可以有一个名字,存储在属性.name中
- Series对象类型的修改
Series对象可以随时修改并即刻生效
Pandas库的DataFrame类型
-
DataFrame类型由共用相同索引的一组列组成

-
DataFrame类型可以由如下类型创建:
• 二维ndarray对象
• 由一维ndarray、列表、字典、元组或Series构成的字典
• Series类型
• 其他的DataFrame类型
-
例子
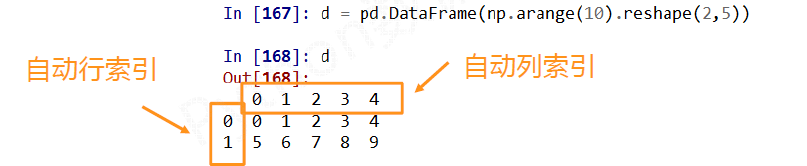




-
210行中d.ix[ ] 获得一行的信息,colums作为索引;211行表示获得某一个位置数据
注:由字典创建时字典的key会作为列索引。
DataFrame是二维带“标签”数组,基本操作类似Series,依据行列索引。
Pandas库的数据类型操作
-
重新索引: .reindex (index=None, columns=None, …) 能够改变或重排Series和DataFrame索引



-
类型: Series和DataFrame的索引是Index类型,Index对象是不可修改类型


通过操作索引可以操作DataFrame的中间数据值
删除指定索引对象:.drop()能够删除Series和DataFrame指定行或列索引

- 因为操作是默认删除0轴,删除行可以直接d.drop()加0轴索引,270行中删除列的时候时候需要修改参数axis=1。
Pandas库的数据类型运算
算术运算法则
-算术运算根据行列索引,只有索引值相同的位置行和列才进行运算,补齐后运算,运算默认产生浮点数
-补齐时缺项填充NaN (空值)
-二维和一维、一维和零维间为广播运算
-采用+ ‐ * /符号进行的二元运算产生新的对象
数据类型的算术运算
- 运算方法




- 注:fill_value参数替代NaN,替代后参与运算
不同维度间为广播运算,用采用+ ‐ * /符号运算时一维Series默认在轴1参与运算
使用运算方法可以令一维Series参与轴0运算
比较运算法则
比较运算只能比较相同索引的元素,不进行补齐
二维和一维、一维和零维间为广播运算
采用> < >= <= == !=等符号进行的二元运算产生布尔对象
注:同维度运算,尺寸一致;不同维度,广播运算,默认在1轴


单元小结
Series = 索引 + 一维数据
DataFrame = 行列索引 + 二维数据
理解数据类型与索引的关系,操作索引即操作数据
单元8 Pandas数据特征分析
数据的排序
.sort_index(axis=0, ascending=True) 在指定轴上根据索引进行排序,默认升序
.sort_values() 在指定轴上根据数值进行排序,默认升序

-强调一句:pandas库对索引的操作就是对数据的操作
.sort_values() 方法在指定轴上根据数值进行排序,默认升序
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
by:axis轴上的某个索引或索引列表

- 这里386行的代码,意思是在索引值2的列上默认按0轴方向进行排列;388行中在索引值为a的行上按1轴方向进行排序。

- NaN统一放到排序末尾
数据的基本统计分析
- 基本的统计分析函数
适用于Series和DataFrame类型:



- a.describe出来的结果,如果a是series类型,a.describe就是series类型 ;如果a是DataFrame类型,a.describe就是DataFrame类型
适用于Series类型:

- 数据的累计统计分析
- 累计统计分析函数
适用于Series和DataFrame类型,累计计算:


适用于Series和DataFrame类型,滚动计算(窗口计算):


-456行代码中由于是在0轴方向以两个元素为单位进行运算,c对应这一行往上没有相邻元素,所以自动补NaN,NaN加任意数还是NaN
- 数据的相关分析
两个事物,表示为X和Y,如何判断它们之间的存在相关性?
- 相关性
• X增大,Y增大,两个变量正相关
• X增大,Y减小,两个变量负相关
• X增大,Y无视,两个变量不相关


- 相关分析函数: 适用于Series和DataFrame类型



CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)