阿里云容器服务K8S集群使用体验:混合部署在线服务和离线任务
本来想使用自建的K8S集群来演示混合部署的,无奈作者的电脑配置实在是跟不上,一开虚拟机就卡得不行。于是果断选择氪金使用阿里云的容器服务K8S版,既省去了自己各种操作的压力,也权当是体验一把国内顶级的Kubernetes容器服务。一、混合部署的概念在开始介绍混合部署的概念之前,我们需要先考虑K8S在实际业务中可能存在的问题。假设你是一个中小企业的运维,并且公司业务都部署在K8S的集群上。那么...
本来想使用自建的K8S集群来演示混合部署的,无奈作者的电脑配置实在是跟不上,一开虚拟机就卡得不行。于是果断选择氪金使用阿里云的容器服务K8S版,既省去了自己各种操作的压力,也权当是体验一把国内顶级的Kubernetes容器服务。

一、混合部署的概念
在开始介绍混合部署的概念之前,我们需要先考虑K8S在实际业务中可能存在的问题。
假设你是一个中小企业的运维,并且公司业务都部署在K8S的集群上。那么毫无疑问,我们要尽可能地发挥K8S集群的机器利用率,也就是尽可能地不浪费K8S集群的计算能力。因为如果你不充分利用,一看CPU使用率连5%都不到,那一堆设备就相当于放那吃灰,这对于企业来说显然是不能接受的。
我们假设业务分为在线和离线两种模式:在线任务需要资源相对较少,但要求响应时间短;离线任务则不需要对任务进行迅速响应,但是计算量相对较大、占用资源多。那么我们应该怎么在K8S集群上完成这两种业务的部署、并且使得CPU利用率始终维持在一个比较高的水平上呢?
答案显而易见,就是“混合部署”,即在一台计算机上同时部署咱们的在线任务和离线任务。(当然,混合部署更常见的说法是混合云部署)
那么这么搞,问题也随之而来了。比方说我们的在线服务是给客户端提供Web资源,但是某天离线任务(比如TF)突然来了好几十个TB的数据要训练,一下就把所有node资源给占用了。那这下可好了,用户点我们的网站进不去,一天损失好几亿,一下就把我们之前辛辛苦苦省下来的买服务器的钱给霍霍干净了,这不完犊子了吗?
不要慌,这个问题早就得到了解决。接下来,咱们就来学习一下Kubernetes中的QoS管理。
二、QoS相关知识
QoS(Quality of Service),大部分译为 “服务质量等级”,又译作 “服务质量保证”,是作用在 Pod 上的一个配置,当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级。
我们使用的QoS等级主要有以下三个,他们所决定Pod的重要程度从上到下依次递减。
- Guaranteed:Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。如果一个容器只指明limit而未设定request,则request的值等于limit值,是最严格的要求。
- Burstable:Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。或者可以这么表达:在不满足Guaranteed的情况下,至少设置一个CPU或者内存的请求。
- BestEffort:容器必须没有任何内存或者 CPU 的限制或请求,就很佛系。
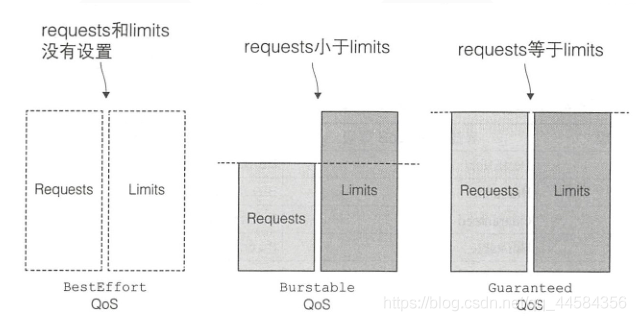
那么QoS的作用体现在哪呢?我们举个例子,比方说计算机中的内存和磁盘资源是不可以被压缩的,而当资源紧俏时,kubelet会根据资源对象的QoS进行驱逐:
- Guaranteed,最高优先级,最后kill。除非超过limit或者没有其他低优先级的Pod。
- Burstable,第二个被kill。
- BestEffort,最低优先级,第一个被kill。
这也就意味着如果一个Node中的内存和磁盘资源被多个Pod给抢占了,那么QoS为BestEffort的Pod显然是第一个被kill的。那么说到这里,想必各位读者对于上一节中存在的问题应该如何解决想必已经有了答案。我们在实际部署的时候,可以把在线服务所使用的Pod的QoS设置为Guaranteed,这样就避免了负载过大的离线任务占用过多资源把我们的在线Pod给挤掉的情况。
哔哔了这么多,咱们还是看几个Pod的yaml文件来学习一下QoS。我们创建一个QoS为Guaranteed的Pod。
# kubectl create namespace example-qos
QoS为Guaranteed的pod中每个容器都必须包含内存和CPU的请求和限制,并且值相等。那么我们就遵循这一原则,编写如下的yaml文件。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: example-qos
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "300Mi"
cpu: "500m"
requests:
memory: "300Mi"
cpu: "500m"
接下来我们启动该pod,并查看该pod的详细信息。
# kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod.yaml --namespace=example-qos
# kubectl get pod qos-demo --namespace=example-qos --output=yaml
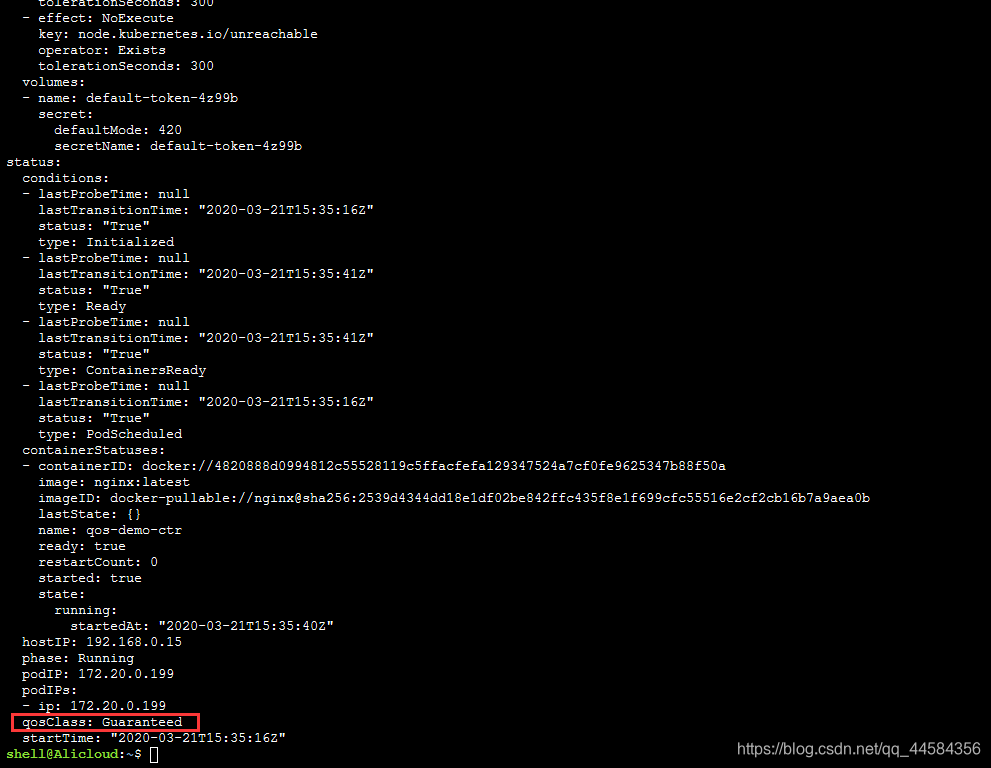
如果正常的话,最后会多出一行qosClass: Guaranteed,这代表我们创建的Pod的QoS为Guaranteed。如果Pod仅声明了内存限制,而没声明内存请求,那么kubernetes会自动赋予它与限制相同的内存请求。CPU也是如此。
三、操作过程
因为作者是第一次体验阿里云K8S容器服务,除了跟着阿里手册和K8S中文社区,还借鉴了不少技术文档,因此在步骤上可能稍有出入。以下步骤仅供参考,具体请以官方文档为准。
我们先登录阿里云的容器服务K8S的控制台。
1. 创建Kubernetes集群
想要创建一个Kubernetes集群,需要开通容器服务、弹性伸缩(ESS)服务和访问控制(RAM)服务。因此我们先登录容器服务管理控制台 、RAM 管理控制台和弹性伸缩控制台开通相应的服务。
控制台界面如下所示。

我们点击创建集群,进入以下界面。
 由于阿里的官方文档已经很详细地解释了每一步的各个选项的内容,这里本人就不狗尾续貂了,仅简单介绍阿里云K8S对应的三种服务模式。
由于阿里的官方文档已经很详细地解释了每一步的各个选项的内容,这里本人就不狗尾续貂了,仅简单介绍阿里云K8S对应的三种服务模式。
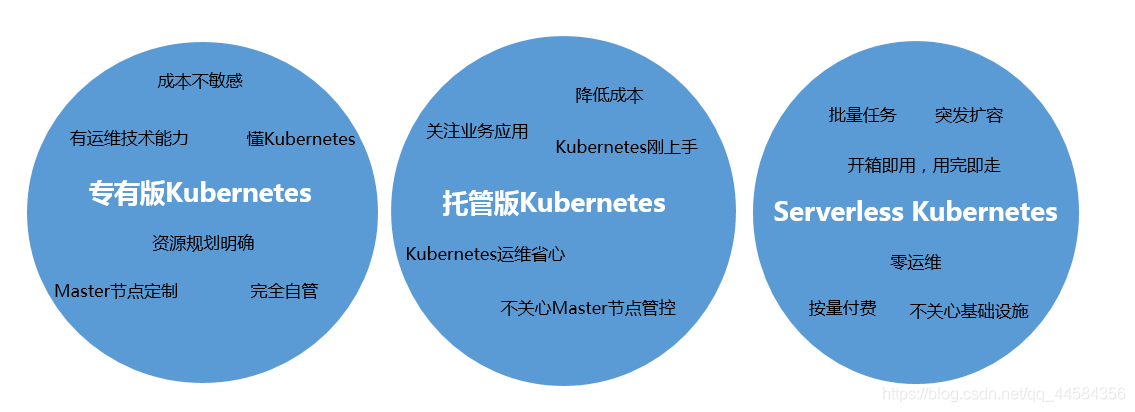
容器服务 Kubernetes 版(简称 ACK)提供高性能可伸缩的云原生应用管理能力,并提供了以下三种 Kubernetes 集群形态,
- 专有版 Kubernetes: 需要创建 3 个 Master(高可用)节点及若干 Worker 节点,可对集群基础设施进行更细粒度的控制,需要自行规划、维护、升级服务器集群。
- 托管版 Kubernetes:只需创建 Worker 节点,Master 节点由容器服务创建并托管。具备简单、低成本、高可用、无需运维管理 Kubernetes 集群 Master 节点的特点,您可以更多关注业务本身。
- Serverless Kubernetes:无需创建和管理 Master 节点及 Worker 节点,即可通过控制台或者命令配置容器实例的资源、指明应用容器镜像以及对外服务的方式,直接启动应用程序。
那么为了体验原生Kubernetes的操作,我们这里选择的是专有版Kubernetes。读者可根据个人情况自行选择。
 之后,我们一路点点点,选择适合自己的配置和插件,即可完成K8S集群的创建,创建完成结果如下。
之后,我们一路点点点,选择适合自己的配置和插件,即可完成K8S集群的创建,创建完成结果如下。
接下来要做的就是安装配置kubectl客户端,并连接到我们的K8S集群上了。之前作者在本地虚拟机部署K8S集群时,在master节点上安装过kubectl并用它对K8S集群输入命令。其实,Kubectl客户端可以在任意一台主机中部署,并连接K8S集群。
首先我们需要从 Kubernetes 版本页面下载最新的kubectl客户端。
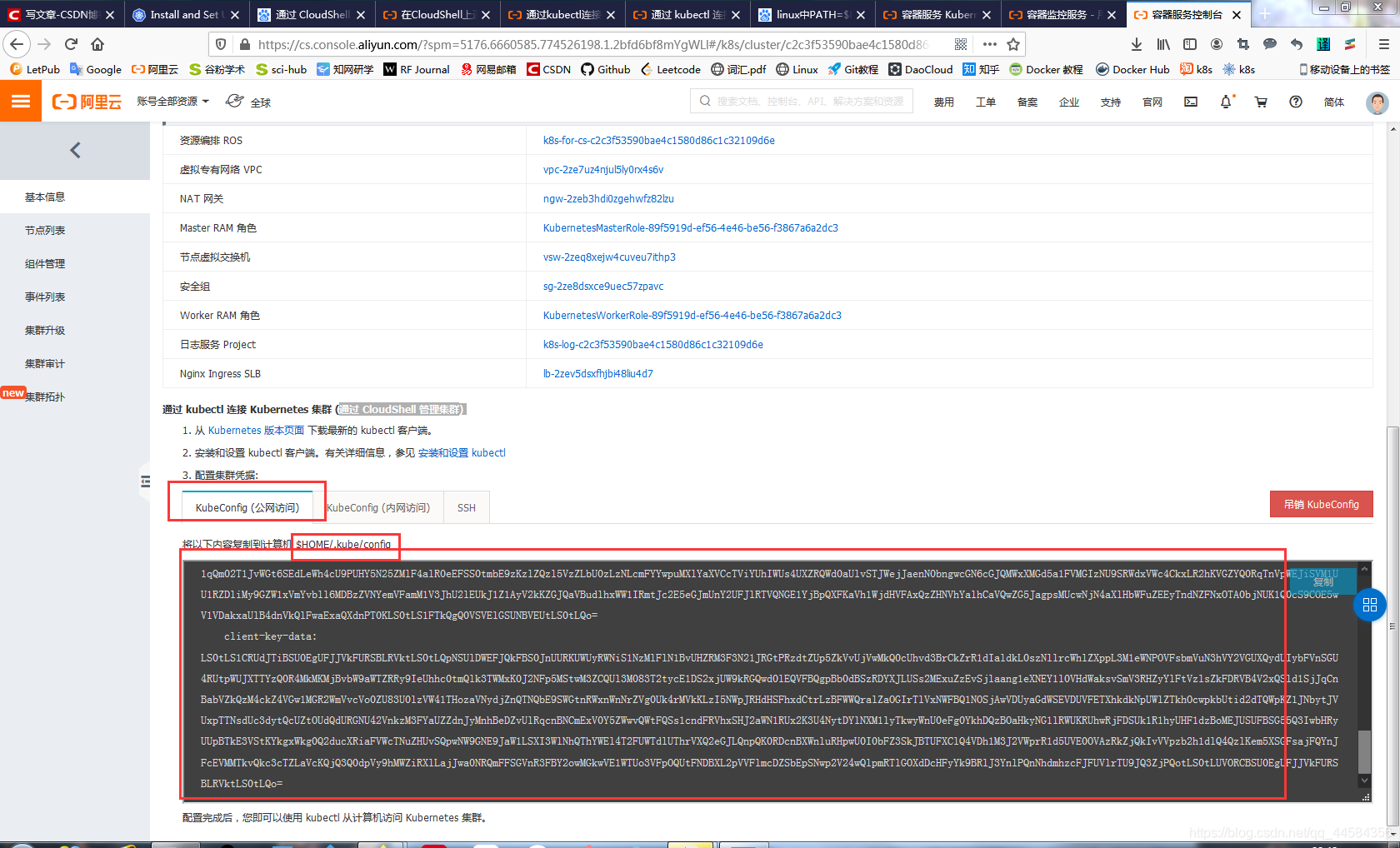
因为在创建集群的时候,我们设置使用公网访问,所以我们选择KubeConfig(公网访问)页签,并单击复制,将内容复制到本地计算机的 $HOME/.kube/config之中。
配置完成后,咱们就可以使用kubectl从计算机访问Kubernetes集群了。当然,作者比较懒,直接通过自带的CloudShell使用kubectl控制的K8S。具体方法如下。

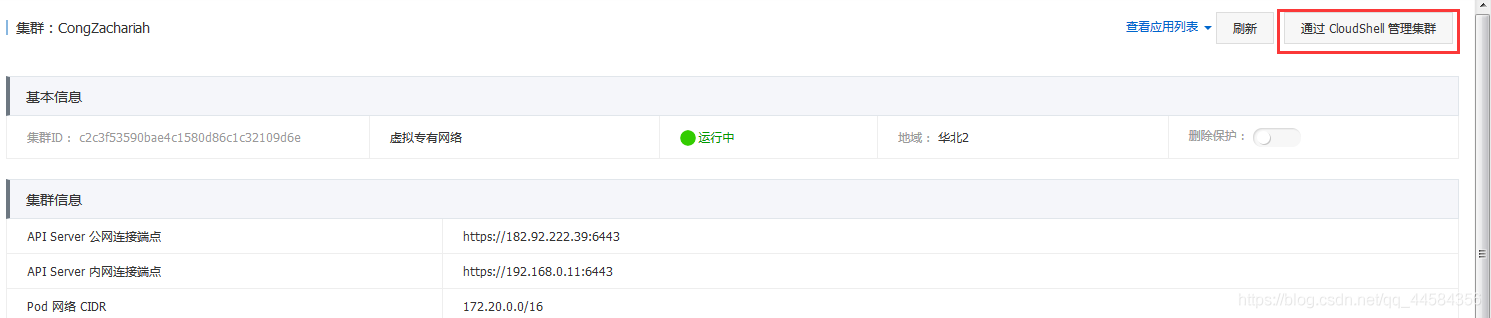 点击进入即可。我们查看nodes的状态,发现我们的集群已经正常启动了。
点击进入即可。我们查看nodes的状态,发现我们的集群已经正常启动了。
 (相信大家也发现了作者的K8S集群里就一个node。无奈作者家境贫寒,这也是没办法的办法。)
(相信大家也发现了作者的K8S集群里就一个node。无奈作者家境贫寒,这也是没办法的办法。)
至此,咱们的K8S集群的创建就算完成了。接下来,咱们就正式部署一下咱们的在线服务和离线任务。
2. 部署在线服务
因为阿里云已经封装好了大部分内容,这也就使得我们无需通过kubectl apply等命令去自己手动执行yaml文件了。我们只需要点击“控制台”,在新的页面点“创建”。
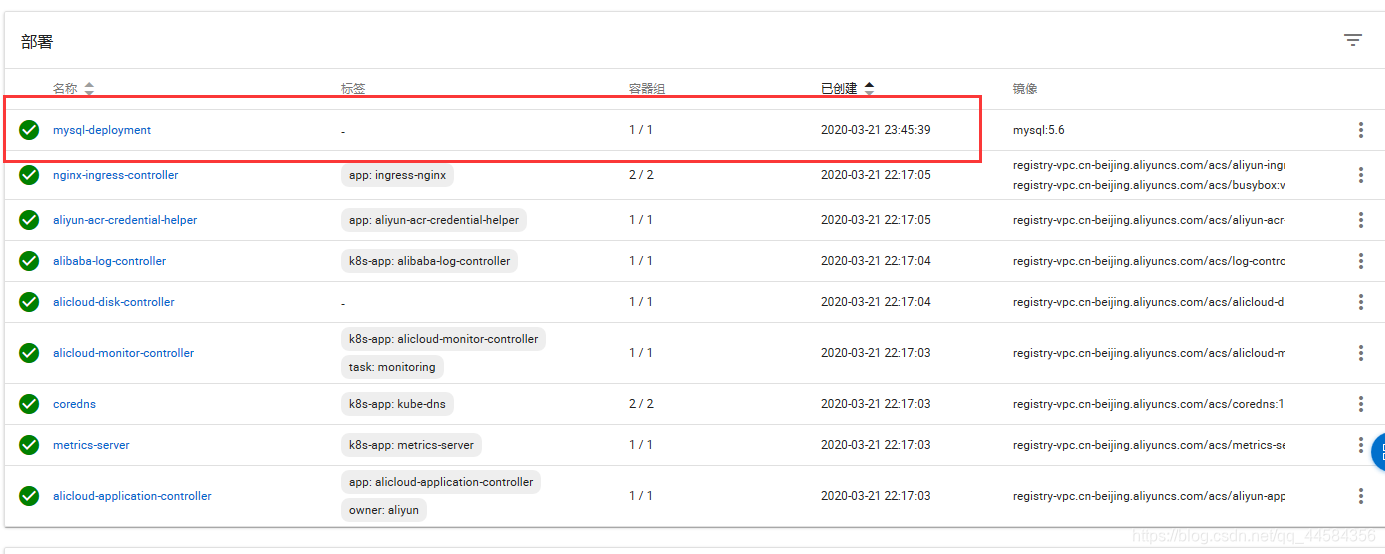
 接下来,咱们只需要输入yaml文件,K8S集群将自动部署好咱们的项目。具体界面如下,这里我们选择部署一个简单的mysql作为我们的在线服务模块。如下所示,我们先后上传
接下来,咱们只需要输入yaml文件,K8S集群将自动部署好咱们的项目。具体界面如下,这里我们选择部署一个简单的mysql作为我们的在线服务模块。如下所示,我们先后上传mysql-deployment.yaml和mysql-svc.yaml两个文件。
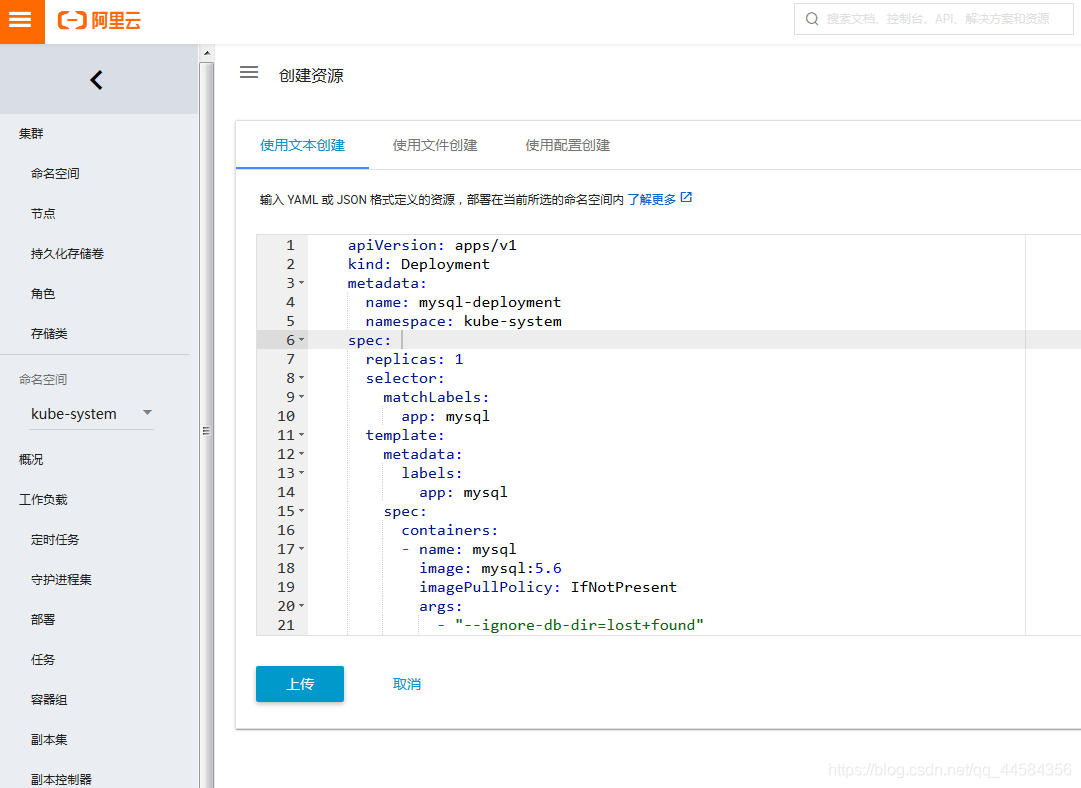
该两个yaml文件的完整代码可参考我之前的博客。
上传成功之后,我们可以清楚地看到CPU、内存的利用率,以及在当前命名空间中各Pod、副本集、deployment等信息。
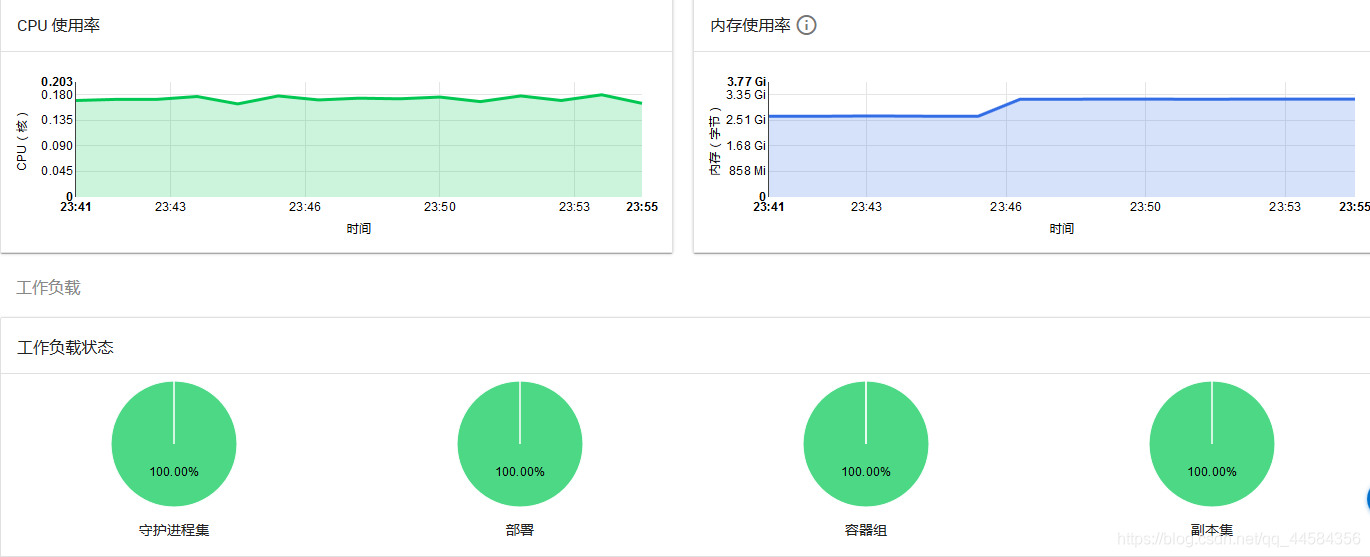
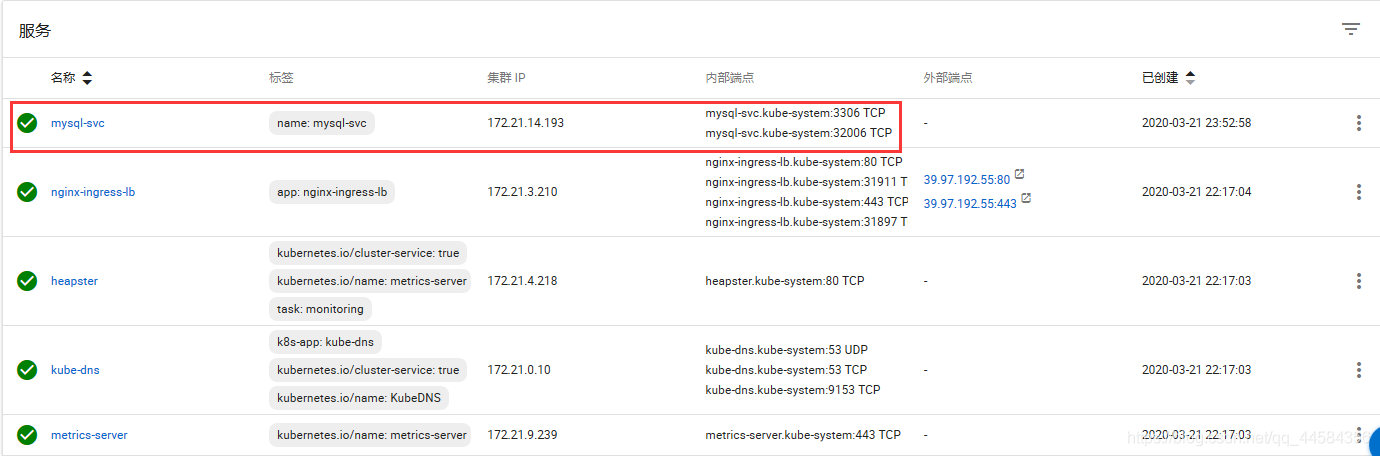
我们在外部能够轻松访问该Mysql,代表在线服务部署完成。
3. 部署离线任务
本例中,作者选择部署tf-operator、并在上边跑tensorflow程序来代表离线任务。所谓 tf-operator,就是让用户在 K8S 集群上部署训练任务更加方便和简单,大家可以参考官网和 Github 进行学习。
在部署 tf-operator 之前,我们首先要在集群中部署Kubeflow,它是基于Kubernetes和TensorFlow的机器学习流程工具,使用Ksonnet进行应用包的管理。当然,我们必须提前部署好ksonnet。
具体过程我就不写了,大家有兴趣可以参考这篇博客。(本例只示范用tf-operator跑一些简单的测试程序,因此Kubeflow不装也可以,但是尽量还是部署)
我们部署好了ks和kubeflow之后,就可以正式安装tf-operator了。我们简单写个脚本并执行一下。
# 指定工作目录
APP_NAME=my-kubeflow
ks init ${APP_NAME}
cd ${APP_NAME}
# 指定 ks registry,方便安装 pkg
ks registry add kubeflow github.com/kubeflow/kubeflow/tree/master/kubeflow
# 安装需要的 pkg
ks pkg install kubeflow/common
ks pkg install kubeflow/tf-training
# all 已经可以替代所安装的 pkg 了
ks generate all
ks apply all
理论上我们已经部署好了tf-operator,我们可以执行以下命令查看tf-operator的运行状态是否正常。
# kubectl get pods
而部署好了tf-operator之后,我们就可以跑一些tf程序了。这里我们采用官方的测试程序,一个分布式的 mnist 训练任务,原yaml文件如下。
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "dist-mnist-for-e2e-test"
spec:
tfReplicaSpecs:
PS:
replicas: 2
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubeflow/tf-dist-mnist-test:1.0
Worker:
replicas: 4
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubeflow/tf-dist-mnist-test:1.0
通过这个yaml文件,我们不难看出这个TFJob,作为离线计算任务,它的QoS为BestEffort。这也意味着当它和我们的在线服务之间因为资源占用问题而冲突时,它是不会影响我们的在线服务的(因为在线任务的QoS为Guaranteed)。
我们依然可以采用直接递yaml文件的方式创建TFJob。
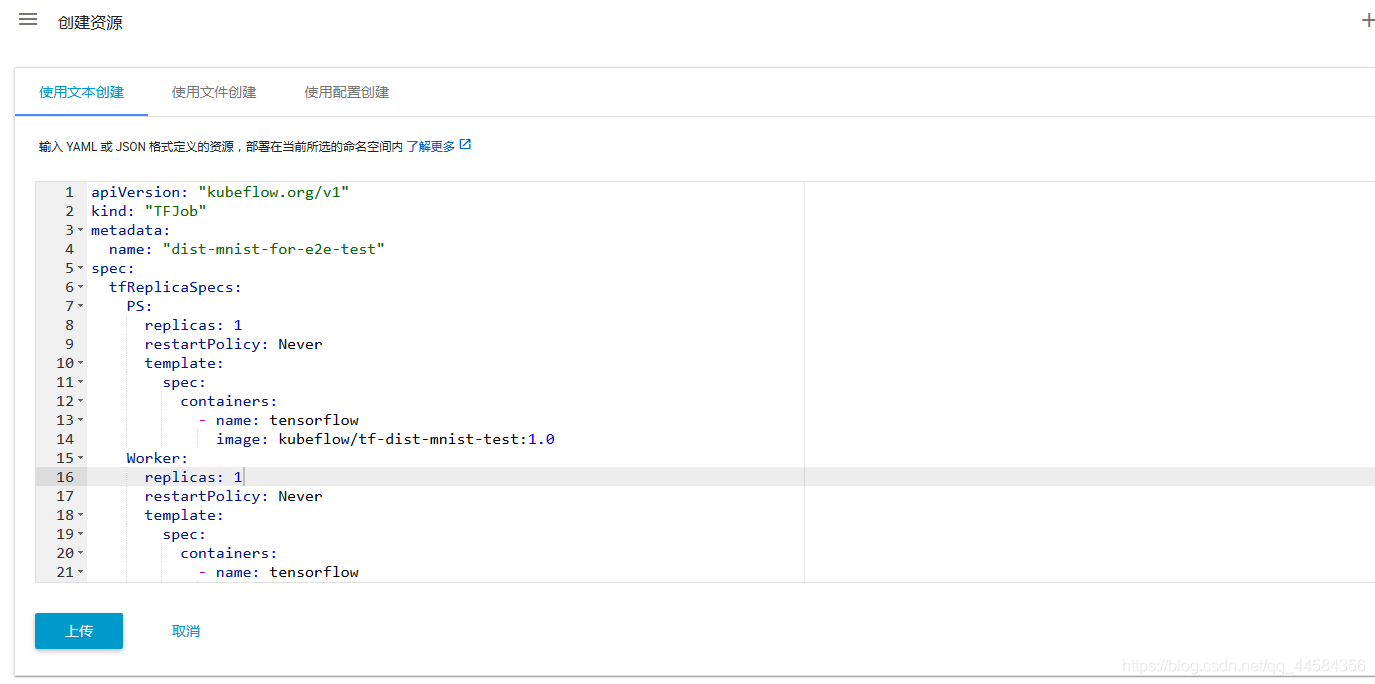
实际上,我们也可以通过下载源文件并执行kubectl命令行来建立该TFJob。
# cd ./examples/v1/dist-mnist
# docker build -f Dockerfile -t kubeflow/tf-dist-mnist-test:1.0 .
# kubectl create -f ./tf_job_mnist.yaml
可以通过以下命令来查看该Pod的状态。
# kubectl get tfjobs.kubeflow.org dist-mnist-for-e2e-test -o yaml
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
creationTimestamp: "2020-03-20T10:13:14Z"
generation: 1
name: dist-mnist-for-e2e-test
namespace: default
resourceVersion: "11825"
selfLink: /apis/kubeflow.org/v1/namespaces/default/tfjobs/dist-mnist-for-e2e-test
uid: f3c0a2c6-b1cb-11e9-9279-0800274cd279
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- image: kubeflow/tf-dist-mnist-test:1.0
name: tensorflow
Worker:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- image: kubeflow/tf-dist-mnist-test:1.0
name: tensorflow
status:
completionTime: "2020-03-20T11:21:47Z"
conditions:
- lastTransitionTime: "2020-03-20T11:21:47Z"
lastUpdateTime: "2020-03-20T11:21:47Z"
message: TFJob dist-mnist-for-e2e-test is created.
reason: TFJobCreated
status: "True"
type: Created
- lastTransitionTime: "2020-03-20T11:13:30Z"
lastUpdateTime: "2020-03-20T11:21:47Z"
message: TFJob dist-mnist-for-e2e-test is running.
reason: TFJobRunning
status: "False"
type: Running
- lastTransitionTime: "2020-03-20T11:21:47Z"
lastUpdateTime: "2020-03-20T11:21:47Z"
message: TFJob dist-mnist-for-e2e-test successfully completed.
reason: TFJobSucceeded
status: "True"
type: Succeeded
replicaStatuses:
PS:
succeeded: 1
Worker:
succeeded: 1
startTime: "2020-03-20T11:21:47Z"
四、监控模块
在本例中,我们采用的容器监控服务依托于阿里云云监控服务,能够提供默认监控、报警规则配置等服务。只需要在创建Kubernetes集群的时候选择“云监控”插件,就可以一键解决K8S集群的监控问题。
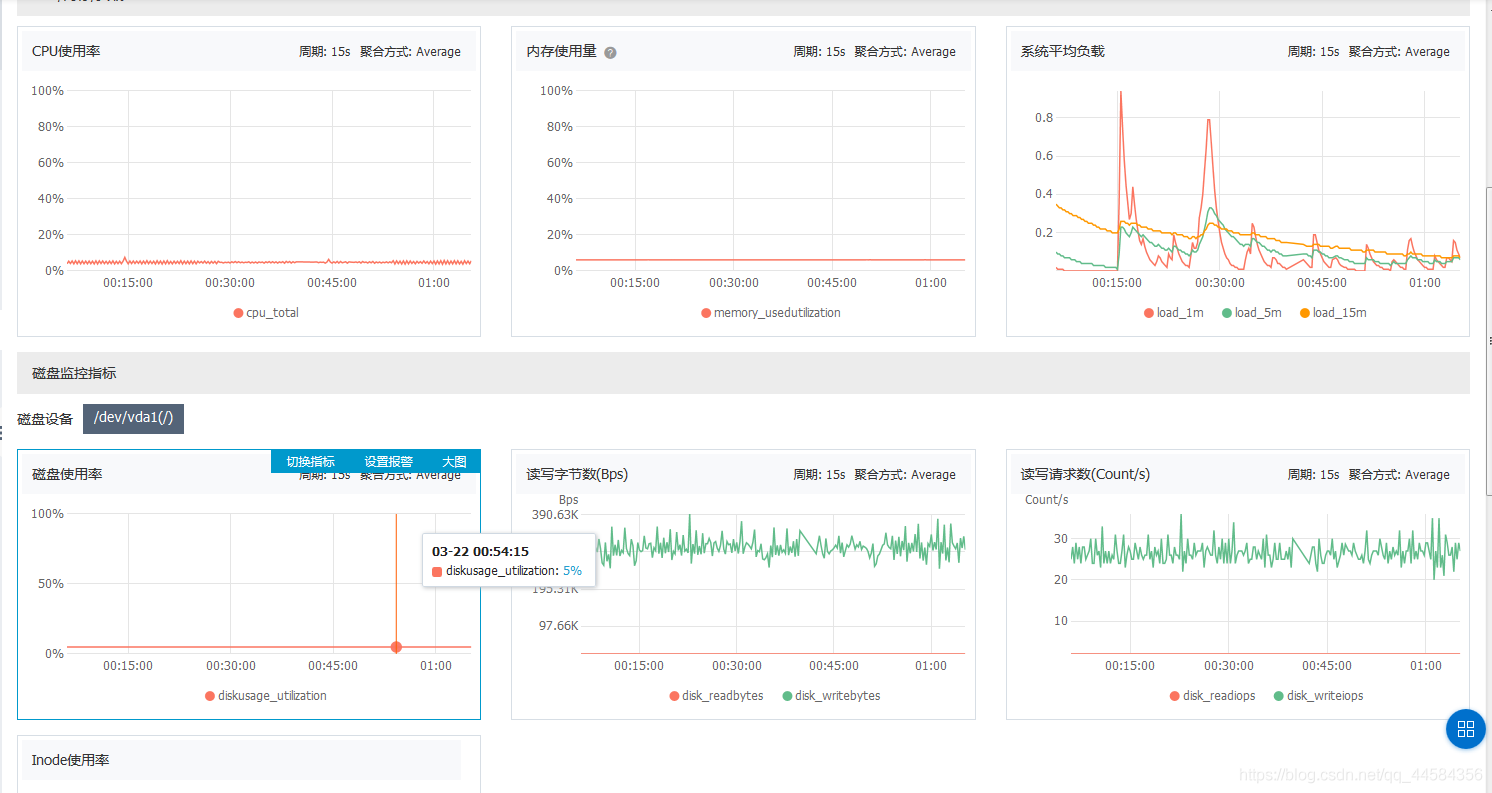
我们打开云监控的控制台,可以清楚地看到每一个节点的工作状态和资源利用率等指标。

点进去,可以看到单独节点的具体信息和各项指标的数据可视化。
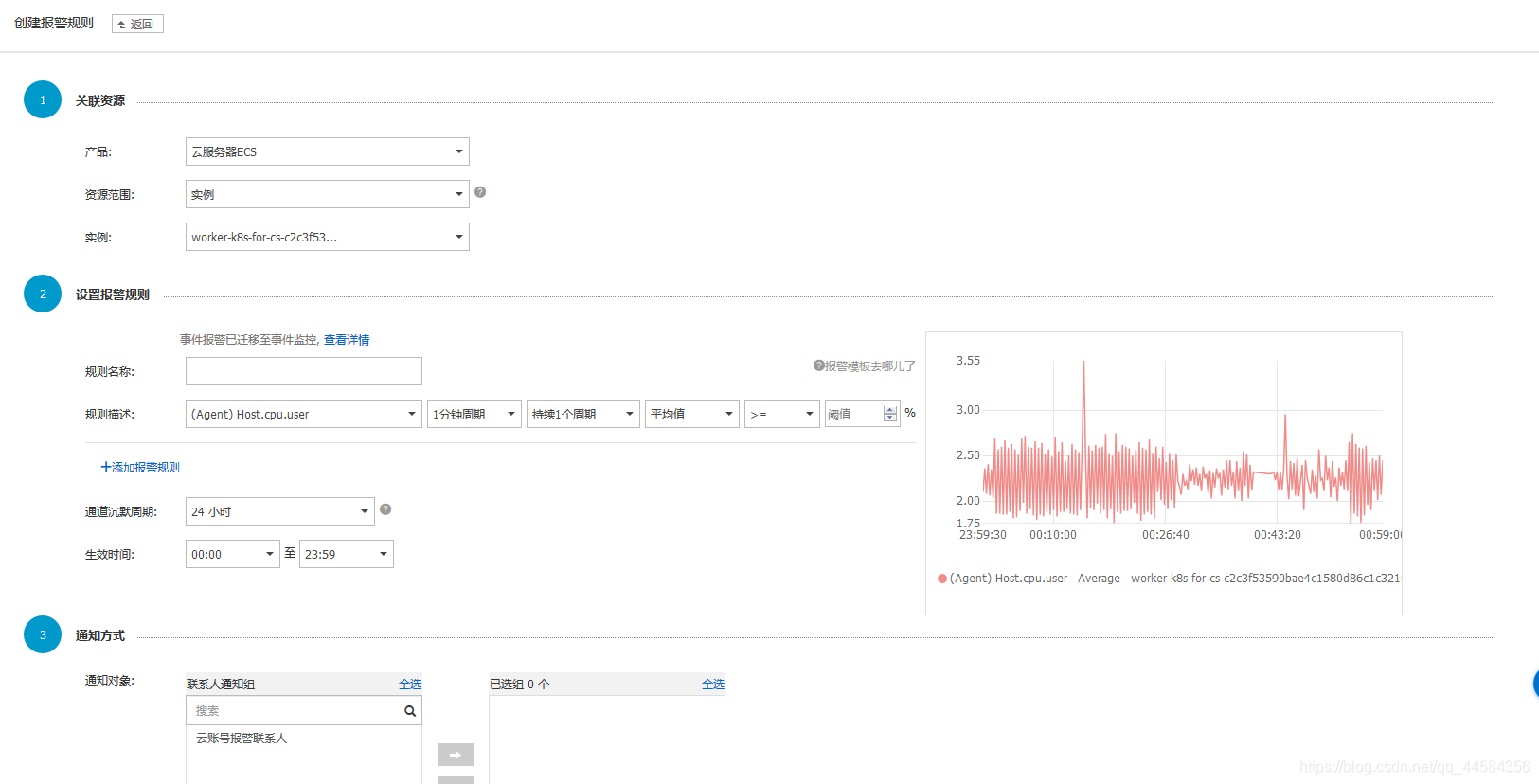
 阿里云监控服务的报警模块也做得十分完善。比如在某些关键服务中,我们可以根据自己业务的实际情况添加报警规则,容器监控服务会在监控指标达到告警阈值后短信通知云账号联系人。
阿里云监控服务的报警模块也做得十分完善。比如在某些关键服务中,我们可以根据自己业务的实际情况添加报警规则,容器监控服务会在监控指标达到告警阈值后短信通知云账号联系人。
 阿里云的监控模块十分容易上手,在此就不赘述了。
阿里云的监控模块十分容易上手,在此就不赘述了。
当我们自己使用虚拟机创建K8S集群时,为了实现对集群 的监控,我们只能自己部署监控插件,比如Prometheus。有兴趣的朋友可以移步https://www.cnblogs.com/fatyao/p/11007357.html学习Prometheus的安装和操作,作者开学之后也会尝试在自己搭建的K8S集群中采用Prometheus,在此先占个坑。
五、小结
作为国内云技术最优秀的互联网技术公司,阿里巴巴的云计算服务,无论从用户体验、稳定性能还是容灾管理、版本更新,都无疑是国内顶尖的。今天我们尝试了在阿里云容器服务Kubernetes版中构建一个K8S集群,并把我们的在线服务和离线任务同时部署在了K8S集群上,实现了“混合部署”的概念,并通过阿里云监控组件对系统的运行状态进行监控和预警,从而对企业生产中所应用的K8S业务部署有了实际的体验。

开源、云原生的融合云平台
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)