
STM32CubeMX生成代码时防止UTF-8乱码
STM32CubeMX在重新生成代码时,位于User Code 区域的中文代码会出现乱码现象。这是因为Windows的默认编码为GBK, STM32CubeMX在生成代码时使用了默认的GBK编码。下面的两种方法来自《STM32CubeMX处理UTF-8编码中文注释存在的问题及解决方法》1、不要使用UTF-8编码。如果开发环境是多元的,要支持Windows、Linux、Mac OS X,那只能使..
·
STM32CubeMX在重新生成代码时,位于User Code 区域的中文代码会出现乱码现象。这是因为Windows的默认编码为GBK, STM32CubeMX在生成代码时使用了默认的GBK编码。
下面的两种方法来自《STM32CubeMX处理UTF-8编码中文注释存在的问题及解决方法》
1、不要使用UTF-8编码。如果开发环境是多元的,要支持Windows、Linux、Mac OS X,那只能使用UTF-8编码。
2、不要在STM32CubeMX生成的文件中写中文注释,可以写英文注释,或者将有中文注释的代码放到用户创建的源文件中,STM32CubeMX不会去修改用户创建的源文件,所以是没问题的。
还有一种方法来自《STM32CubeMX UTF8 source file merge bug》
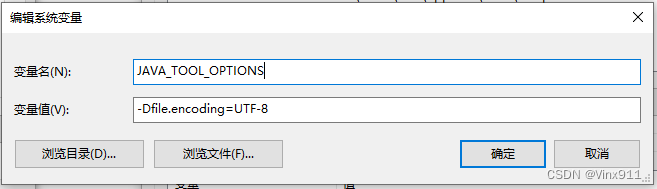
在Windows的环境变量中添加
- 变量名称:JAVA_TOOL_OPTIONS
- 变量值:-Dfile.encoding=UTF-8

更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)