- @zqfzqfzqf123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
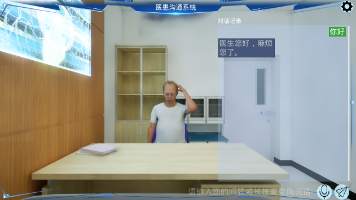
系统是一款基于虚幻引擎 5与大语言模型技术的 PC 桌面端医患沟通模拟实训软件。系统旨在为医学生提供低成本、高保真、可重复、标准化的临床问诊实训平台。医生(用户)通过麦克风输入与 AI 驱动的数字人患者(以 49 岁突发胸痛的“王大爷”为典型案例)进行多轮语音对话。系统在后端对学生的沟通表现和病史采集逻辑进行记录,并提供客观的反馈,为医学教育提供标准化的训练工具。
在上一阶段,我虽然通过全内存流式传输将纯语音的对话延迟降低到了较为理想的水平,但另一个棘手的问题又浮出了水面——。之前项目中采用的 Audio2Face 方案依赖深度学习算法,需要调用 GPU 来实时计算口型。这导致系统对硬件配置的要求极高,在我平常使用的笔记本上甚至根本带不动。为了能让这个医患沟通评价系统在更普及的硬件(如普通 CPU 平台)上流畅运行,我不得不寻找一种低开销、低延迟的唇形同步替
在初步实现了“医患沟通评价系统”的 AI 对话功能后,我很快遇到了一个严重影响交互体验的问题——。当时系统的运行链路是:前端采集音频 -> 后端语音转文字(ASR) -> 后端大模型(LLM)生成文本 -> 后端文本转语音(TTS) -> 前端读取音频并播放。:系统必须等待大模型和语音合成完整生成后,才能将音频整体输出给前端,导致单次对话的延迟高达 10 秒左右。:由于音频文件是作为 WAV 格式
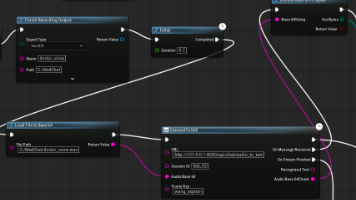
目前的整体数据流设计是这样的:前端通过UE的 AudioCapture 插件将用户的语音录制并保存到本地,后端读取该本地文件并调用大模型进行处理,最后通过FastAPI将AI生成的回复结果回传并输出到UE前端展示。随着后端组员完成了Prompt的调试与数据库的编写,我们开始使用Git合并代码。:目前整个语音输入、模型调用到结果回传的链路还存在延迟,如何进一步压缩响应时间、提升流畅度,是后续需要重点
通过在平台上编写Prompt来调试、设计具有特定情绪和质感的虚拟音色,并在后端调用对应的语音合成接口,将大模型输出的文本转化为动态音频文件。画好这些草图后,我们下一步的任务就是分工合作——前端同学负责将草图在UE5中落地并编写HUD的切换逻辑,而我则需要在后端提供对应的API接口,确保真实的动态数据能够准确渲染到界面中。在完成了前期的框架搭建与接口集成后,这一周我们把工作的重心放到了系统“交互体验
目前的整体数据流设计是这样的:前端通过UE的 AudioCapture 插件将用户的语音录制并保存到本地,后端读取该本地文件并调用大模型进行处理,最后通过FastAPI将AI生成的回复结果回传并输出到UE前端展示。随着后端组员完成了Prompt的调试与数据库的编写,我们开始使用Git合并代码。:目前整个语音输入、模型调用到结果回传的链路还存在延迟,如何进一步压缩响应时间、提升流畅度,是后续需要重点
作为一名数媒专业的学生,面对技术开发,我的底子其实并不算厚实。在项目启动之初,除了Python稍微熟悉一些,像FastAPI、Redis、PostgreSQL这些后端名词,对我而言都是全新的概念。好在借助AI工具和B站上的视频教程,我边学边练,总算理清了基本的开发思路,并一步步把后端的项目框架搭建了起来。理清架构后,为了让团队其他成员也能顺利上手,我连夜把环境配置的步骤整理并发布到了Gitee上,
上期博客已经实现了流式输出,纯语音对话的延迟已经达到了实时对话的标准,主要影响体验的还是唇形同步,当前项目使用Audio2Face插件,但插件使用深度学习算法计算口型,需要用上GPU跑模型,就导致对电脑性能要求极高(天选4笔记本带不动)本博客将记录我对,实现纯CPU和低性能需求的唇形同步。
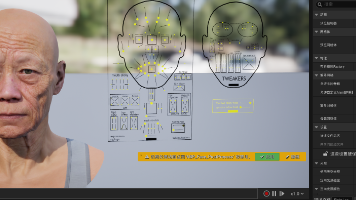
后端同学已经把prompt和数据库写好了,使用git合并代码主要几个注意点1.gitignore要把前端UE忽略掉,不然会覆盖掉前端项目2.不要把大模型API-Key上传到git上。
当前已初步实现AI对话,架构如下:前端生成音频--->后端音频转文字--->后端文字LLM--->后端文字转音频--->前端读取音频并播放。