




- @zoubf
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:大数据处理是云计算中非常重要的领域,自Google公司提出MapReduce分布式处理框架以来,以Hadoop为代表的开源软件受到越来越多公司的重视和青睐。本文将讲述Hadoop系统中的一个新成员:Impala。Impala架构分析Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已
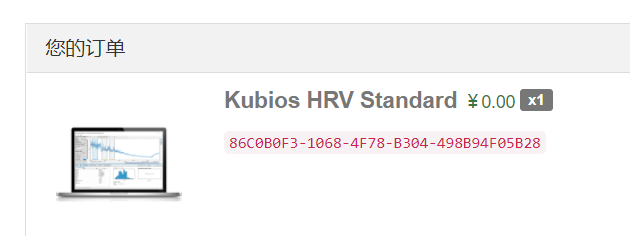
是由东芬兰大学研究团队开发的一款软件,目前在全球128个国家被1200所大学的科研人员使用。PC端的Kubios HRV主要分免费版()和收费版()两个版本。免费版仅支持,收费版既支持,也支持和功能。
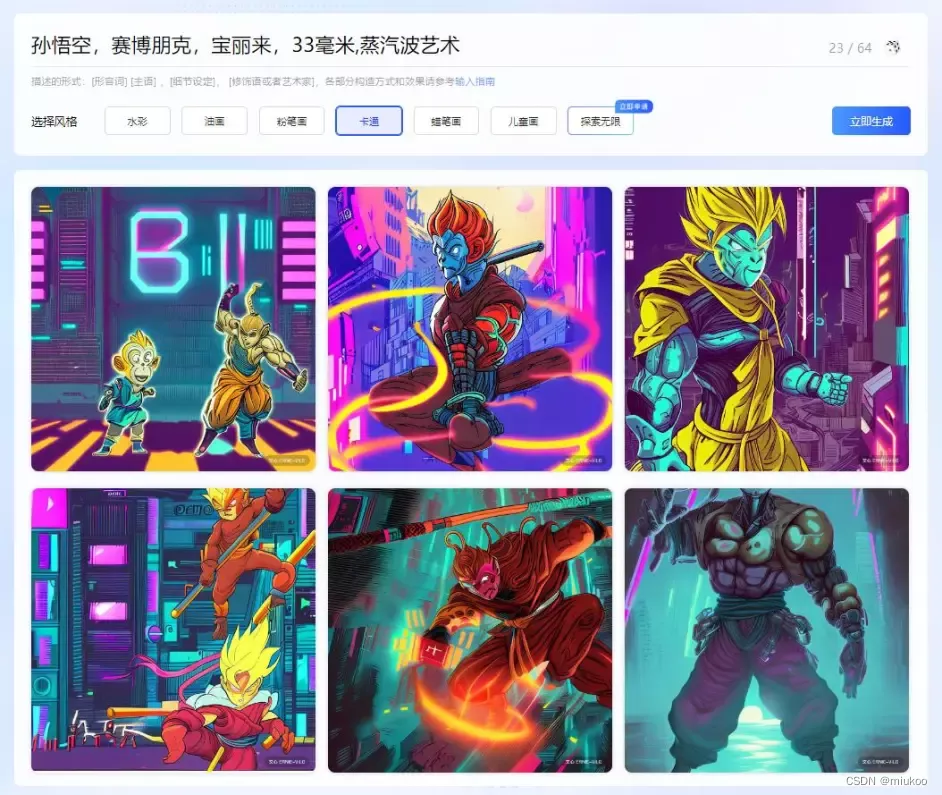
人工智能正在改变许多行业的格局,而其中改变最直观和影响最大的就是AIGC领域的图像创作。发展至今已经有很多AI图像生成平台,他们的共同特点就是使用人工智能将文本转换为图像,这是一次革命性的突破,也就是说通过这些AI工具可以在几秒钟内将文字转换成更具可视化表示的图片。那么,就目前而已有那些AI生成图片的平台呢?本文将带你了解全球顶级的15款AI图像生成平台。
SNS(简单通知服务):可用于向移动应用程序、电子邮件、SMS和HTTP / HTTPS端点发送消息,使应用程序更加动态和交互。Lambda:让开发人员运行代码而无需管理服务器,可自动缩放,可用于构建可扩展的后端服务、数据处理、图像处理和自动化工具等。RDS(关系型数据库服务):提供易于设置、操作和扩展的关系型数据库,如MySQL、Oracle和SQL Server等。S3(简单存储服务):提供高
