




- @yyw794
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
非常多同学弄不清楚docker-compose up, docker-compose restart, docker restart的区别。up和restart的区别docker-compose restart不会加载新的docker-compose相关文件的新的改动(如,docker-compose.yml文件)docker-compose down ; docker-compose...
pytorch, tensorflow, onnx, tensorrt 格式的横向比较
pytorch, tensorflow, onnx, tensorrt 格式的横向比较
我的笔记本虽然有nvidia独显,但为了更好的续航,平时会切换为intel集成显卡,需要AI计算时,才临时切换会nvidia独显。采用prime-select指令prime-select query 可以查询在用的显卡是哪一个sudo prime-select nvidia 切换nvidia独显sudo prime-select intel 切换intel集成显卡...
什么是triton inference server?它的前身是nvidia的tensorRT,triton在具备tensorRT的基础上,增加了主流的TF,pytorch,onnx等模型的推理部署支持。是一款非常好的推理模型部署服务。具体了解:NVIDIA Triton Inference Server | NVIDIA Developerhttps://developer.nvidia.com
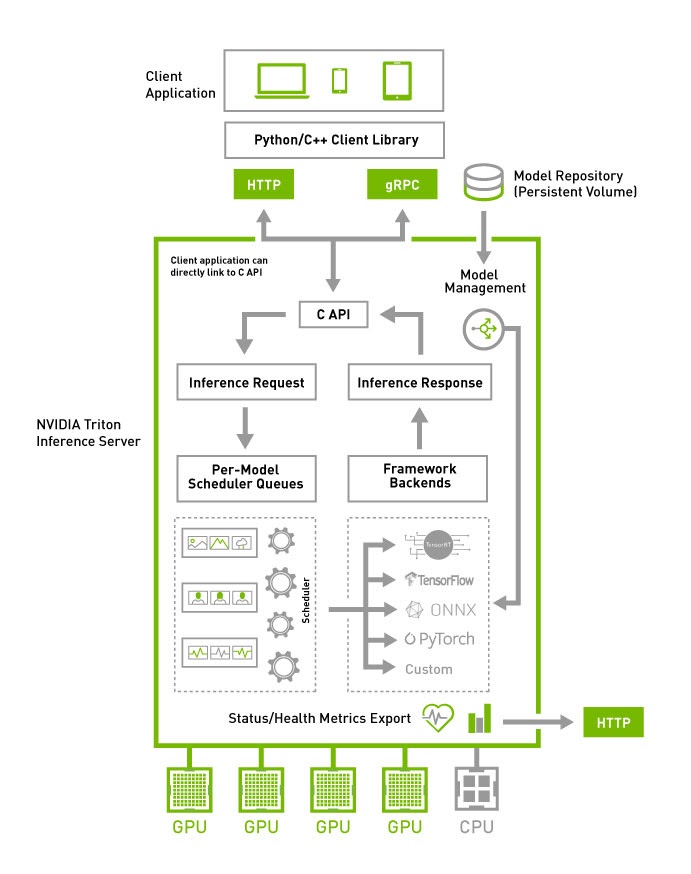
什么是triton inference server?它的前身是nvidia的tensorRT,triton在具备tensorRT的基础上,增加了主流的TF,pytorch,onnx等模型的推理部署支持。是一款非常好的推理模型部署服务。具体了解:NVIDIA Triton Inference Server | NVIDIA Developerhttps://developer.nvidia.com
我的笔记本虽然有nvidia独显,但为了更好的续航,平时会切换为intel集成显卡,需要AI计算时,才临时切换会nvidia独显。采用prime-select指令prime-select query 可以查询在用的显卡是哪一个sudo prime-select nvidia 切换nvidia独显sudo prime-select intel 切换intel集成显卡...
python的新款异步框架FASTAPIhttps://fastapi.tiangolo.com/是一款最近很火的框架。我过去使用了Flask很多年,当一使用上fastapi,就喜欢上它了。今天的问题是:我们的函数到底应该定义为async还是普通函数?直接上演示代码。from fastapi import FastAPIimport timeimport asyncioimport osapp =