




- @yuyue1116
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
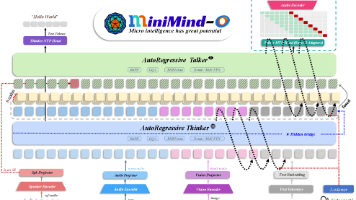
《MiniMind-O技术报告:一个开源的小规模全语音原生多模态模型》介绍了一种仅需0.1B参数的轻量级模型,能在4张RTX 3090显卡上4小时内完成训练。该模型创新性地采用Thinker-Talker双路架构,通过中间层桥接状态实现文本与语音生成的统一建模,并支持流式语音输出。实验表明,该模型在768维隐藏层配置下表现最佳,CER为0.0897。虽然性能不及更大规模的Mini-Omni模型,但
语音AI前沿周报摘要(2026.05.18-05.24) 本周语音AI领域取得多项突破性进展: 全双工语音大模型:DuplexSLA实现160ms粒度的听、说、规划三通道同步,开创实时语音交互新范式。 开源TTS生态:Raon-OpenTTS发布615K小时数据集和DiT模型家族,填补高质量开源TTS基础设施空白。 ASR泛化能力:Mega-ASR通过200万小时仿真数据和强化学习,在复杂场景WE
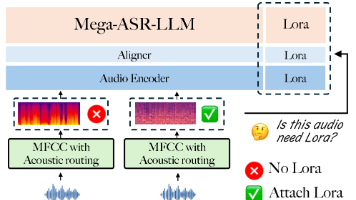
摘要: 论文《Mega-ASR》提出了一种针对真实噪声场景的鲁棒语音识别方案,通过构建包含2.4M复合噪声样本的仿真数据集(覆盖7类声学效应×54种场景),结合双阶段训练策略(课程式SFT+双粒度强化学习),显著提升了模型在极端噪声下的表现。核心创新包括:1)渐进式声学-语义解耦训练(A2S-SFT);2)基于WER门控的双粒度奖励机制(DG-WGPO);3)环境感知路由推理。实验表明,该方法在V
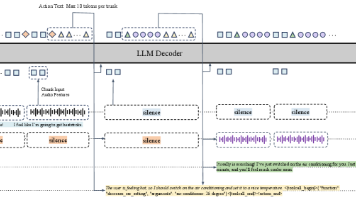
摘要 DuplexSLA提出了一种革命性的语音交互模型,将听、说、想三个功能压缩到160ms的时间块内同步完成,突破了传统语音助手ASR→LLM→TTS串行管线的延迟瓶颈。该模型采用7B参数的统一自回归架构,通过TA4技术将文本锚点与音频token绑定,实现精准的时间对齐;支持原生轮次控制和边说边调用工具,交互延迟低至0.27-0.4秒,工具调用速度比传统方案快4倍。实验显示其在轮次控制场景准确率
语音AI前沿周报摘要(2026.05.18-05.24) 本周语音AI领域取得多项突破性进展: 全双工语音大模型:DuplexSLA实现160ms粒度的听、说、规划三通道同步,开创实时语音交互新范式。 开源TTS生态:Raon-OpenTTS发布615K小时数据集和DiT模型家族,填补高质量开源TTS基础设施空白。 ASR泛化能力:Mega-ASR通过200万小时仿真数据和强化学习,在复杂场景WE
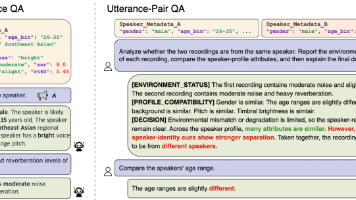
SpeakerLLM:首个专为说话人分析设计的音频语言模型 本文提出SpeakerLLM,解决传统说话人验证系统仅输出分数而缺乏解释能力的问题。通过层次化Tokenizer架构,模型同时捕获全局说话人特征和局部声学细节,显著提升说话人理解能力。实验表明,1.5B参数的SpeakerLLM在说话人验证任务上达到96.1%准确率,远超通用音频大模型。创新点包括:1)双分支Tokenizer处理不同粒度
《MiniMind-O技术报告:一个开源的小规模全语音原生多模态模型》介绍了一种仅需0.1B参数的轻量级模型,能在4张RTX 3090显卡上4小时内完成训练。该模型创新性地采用Thinker-Talker双路架构,通过中间层桥接状态实现文本与语音生成的统一建模,并支持流式语音输出。实验表明,该模型在768维隐藏层配置下表现最佳,CER为0.0897。虽然性能不及更大规模的Mini-Omni模型,但
📅 2026-05-01 至 2026-05-07 | 精选 TOP 10(含架构图)

📅 2026-05-01 至 2026-05-07 | 精选 TOP 10(含架构图)
《UAF:统一全双工语音交互的音频前端LLM》研究提出了一种创新方法,通过单个大型语言模型(LLM)统一处理传统级联架构中的五个语音前端任务。该方法采用Encoder-Projector-LLM结构,将语音活动检测(VAD)、说话人识别、自动语音识别(ASR)、轮次检测和问答(QA)重构为统一的序列预测问题。实验结果显示,该模型在噪声条件下WER仅5.34%,比基线提升7倍,同时在VAD任务上达到