
写文章




- @yuanyuanxingxing
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
xgb调参--简洁版
一、常调参数1、max_depth[默认6]树分裂最大深度,常用3~10之间树越深越容易过拟合(越深模型会学到越具体越局部的样本)树越深也会消耗更多内存且会使得训练时间变长(由于xgb会一直分裂到max_depth指定的值,再回过头来剪枝)2、eta[默认0.3]学习率,常用0.01~0.5之间太大准确率不高、难以收敛(梯度值可能在最优解附近晃荡,不收敛)太小运行速...
什么是element-wise
element-wise
数据并行(DP)、张量模型并行(TP)、流水线并行(PP)
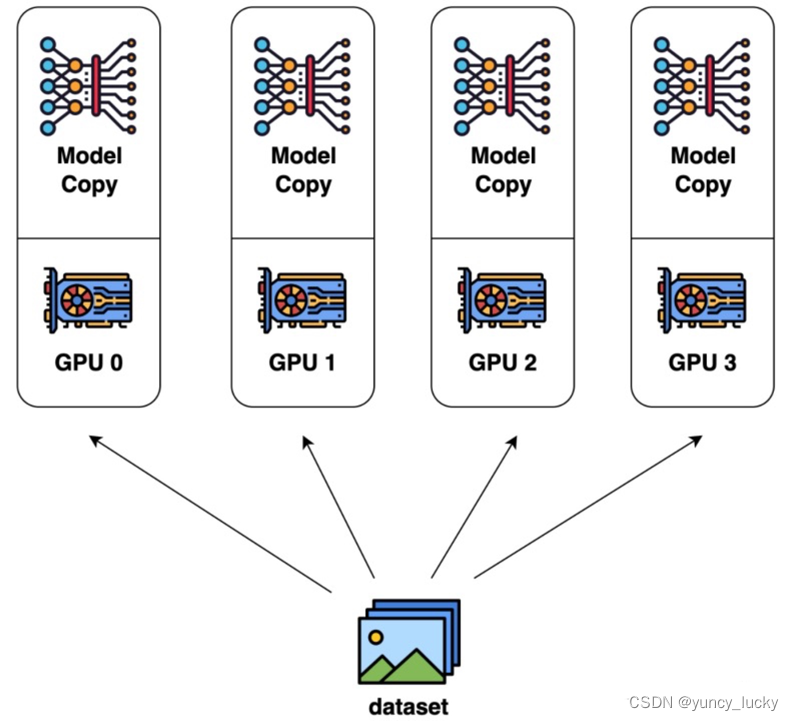
数据集分为n块,每块随机分配到m个设备(worker)中,相当于m个batch并行训练n/m轮,模型也被复制为n块,每块模型均在每块数据上进行训练,各自完成前向和后向的计算得到梯度,更新后,再传回各个worker。以确保每个worker具有相同的模型参数。下图1:每个设备分1份数据下图2:每个设备分4份数据数据不切分的话,就是总共N-1次传输中每次传输数据大小为O(O是模型参数量),数据流转完整一
到底了