




- @xwd18280820053
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
可视图讲解神经元w,b参数的作用在我们接触神经网络过程中,很容易看到就是这样一个式子,g(wx+b),其中w,x均为向量.比如下图所示:加入激活函数为g(x),我们就可以用公式g(w1x1+w2x2+b)(注:1,2均为下标,公众号很难打,下面所有的公式均是)来表示神经元的输出。其中b为神经元的偏置.那么w,b这些参数的作
阿里:7月份最早投的阿里(算法工程师),过了2天就收到一面通知,一面最主要的是问简历上写的内容,问基础。对简历上的项目中涉及到的所有知识点必须理清,期间面试官问了一个我简历上写的但我不是很了解的内容,结果我说不是很熟悉,面试官就说了我不熟悉的还敢往上写…面试主要问的其他知识点:有哪些聚类(当时我只熟悉kmeans,下来赶紧找资料https://www.zhihu.com/question/3...
tile() 平铺之意,用于在同一维度上的复制tile(input,#输入multiples,#同一维度上复制的次数name=None)示例如下:with tf.Graph().as_default():a = tf.constant([1,2],name='a')b = tf.tile(a,[3])sess
f = open("data/model_Weight.txt",'a') #若文件不存在,系统自动创建。'a'表示可连续写入到文件,保留原内容,在原 #内容之后写入。可修改该模式('w+','w','wb'等) f.write("hello,sha") #将字符
按照估计范围划分,因果效应估计包括对平均干预效应(Average Treatment Effect,ATE)、条件平均干预效应(Conditional Average Treatment Effect,CATE)以及个体干预效应(Individual Treatment Effect,ITE)的估计。
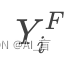
以下为layer normalisation文章解析:摘要训练目前性能最好的深度神经网络计算代价高昂. 一种减少训练时间的方法是规范化神经元的激活值. 近期引入的批规范化(batch normalisation)技术对一个训练样本批量集使用了求和的输入分布来计算均值和方差,然后用这两个来规范化那个神经元在每个训练样本的求和输入. 这个方法显著减少了前驱神经网络的训练时间.
朴素贝叶斯:优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。缺点:对输入数据的表达形式很敏感(连续数据的处理方式)。决策树:优点:计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征。缺点:容易过拟合(后续出现了随机森林,减小了过拟合现象)。逻辑回归:优点:实现简单,分类时计算量非常小,速度很快,存储资源低。缺点:容易欠拟合,一般准确度不高;只能处
1.什么是监督学习和非监督学习,请说明它们的区别,并各举一个例子。说明分类和回归问题的区别,并各举一个例子。答:(1)有监督学习:对具有标记的训练样本进行学习来建立从样本特征到标记的映射。例如:支持向量机 无监督学习:对没有标记的训练样本进行学习,以发现训练样本集中的结构性知识。聚类就是典型的无监督学习。比如:K-means等。(2)回归是监督学习的一种,它的标记是连续取值,有大小区别
阿里:7月份最早投的阿里(算法工程师),过了2天就收到一面通知,一面最主要的是问简历上写的内容,问基础。对简历上的项目中涉及到的所有知识点必须理清,期间面试官问了一个我简历上写的但我不是很了解的内容,结果我说不是很熟悉,面试官就说了我不熟悉的还敢往上写…面试主要问的其他知识点:有哪些聚类(当时我只熟悉kmeans,下来赶紧找资料https://www.zhihu.com/question/3...
可视图讲解神经元w,b参数的作用在我们接触神经网络过程中,很容易看到就是这样一个式子,g(wx+b),其中w,x均为向量.比如下图所示:加入激活函数为g(x),我们就可以用公式g(w1x1+w2x2+b)(注:1,2均为下标,公众号很难打,下面所有的公式均是)来表示神经元的输出。其中b为神经元的偏置.那么w,b这些参数的作