




- @xiaofeixia002X
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作用:先跑一个简单、经典、容易复现的模型,拿到一个基础分数,作为后续改进的参照。你后面做的所有新方法,都要比 Baseline 好才有意义。特点:通常不复杂,可能是传统方法、简单神经网络、公开的轻量模型。中文常译:基线模型、基准线模型。
所有 Mamba 模型,本质都是:在不同任务上,如何设计“扫描顺序 + 状态更新方式 + 融合结构”。
它内部有三个线性层(Q、K、V),将 d_model 映射到 head_size,然后计算注意力。多头注意力 将多个单头注意力并行执行,每个头使用不同的线性投影(即不同的 Q、K、V 权重),从而让模型从不同的子空间(head_size 维)学习不同的特征交互模式。单头注意力 就是只使用一个注意力头的自注意力。也就是说,Q、K、V 的线性投影将输入映射到 head_size = d_model 的
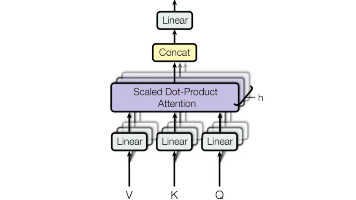
如果用最简单的话定义 Transformer:Transformer 是一种基于注意力机制的网络,它通过让每个 token 和其他 token 动态建立关系,来学习全局上下文信息。token:输入被拆成的小单位embedding:token 变成机器能处理的向量position:告诉模型顺序或位置self-attention:每个 token 去看和自己最相关的其他 tokenmulti-head

在工业自动化、嵌入式系统和机器人领域,工程师们面临着一个关键决策:我们的算法到底应该在哪里运行? 是放在功能强大的上位机,还是嵌入资源有限的下位机,抑或是烧录进并行处理的 FPGA?这个选择如同为军队选择战场,直接影响着整个系统的成败。
学习目标:1.掌握感知机的模型形式、损失函数及对应的优化问题。损失函数推导过程:最终优化函数:min L(w,b)2.掌握随机梯度下降算法原理。推导过程:3.理解感知机模型中随机梯度算法的收敛性。习题:1.思考感知机模型假设空间是什么?模型复杂度体现在哪?假设空间 {f|f=wx+b},即特征空间中的所有线性分类器。模型的复杂度主要体现...
方法一:使用 math.modf 函数;方法二:使用 int 类型转换;方法三:使用字符串操作;方法四:使用 decimal 模块。

tensorflow报错ModuleNotFoundError:no module named tensorflow.python
在OpenCV中,flip函数用于翻转图像。你可以沿x轴、y轴或两者同时翻转图像。这个函数非常直接,可以用于创建镜像图像或旋转图像。src:输入图像。dst:翻转后的输出图像。可以与输入图像相同(原地操作)。flipCode:指定翻转的轴。
