- @xianggll
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
《AI记忆革命:Claude 4.5开启智能体新时代》摘要 Anthropic最新发布的Claude 4.5通过革命性记忆系统实现三大突破:1)采用Markdown持久化存储扩展上下文窗口;2)基于知识图谱构建结构化记忆网络;3)结合GraphRAG技术实现智能检索。该进展标志着AI从工具向智能体的本质转变,企业需加速信息架构语义化转型以应对记忆驱动的AI新时代。行业预测显示,知识图谱市场规模将在

《AI智能体开发中的上下文工程优化策略》 本文系统阐述了从提示工程演进至上下文工程的关键转变,指出构建高效AI智能体需在有限上下文窗口中优化信息配置。文章分析了LLM架构的注意力稀缺性特征,强调需将上下文视为边际收益递减的有限资源。作者提出四大核心策略:1)设计简洁分区的系统提示;2)开发自包含的工具系统;3)精选多样化示例;4)实施"即时"上下文检索与渐进式披露机制。针对长时

《知识图谱与大语言模型融合推动下一代药物发现》摘要:本文探讨了知识图谱(KG)和大语言模型(LLM)在药物研发中的协同应用。KG通过结构化生物医学关系弥补LLM的语义缺陷,而LLM则增强KG的构建与推理能力。二者整合形成了三种创新框架:KG增强的LLM、LLM优化的KG以及协同推理模型,显著提升了靶点识别、药物相互作用预测等关键环节的效率和准确性。文章还分析了知识截止、幻觉等问题,并提出结合检索增

ServiceNow收购data.world引发关注,知识图谱与大语言模型的结合正成为AI时代的关键趋势。本文探讨了这一组合如何帮助企业整合数据资产,以及为什么多数组织尚未为此做好准备。

摘要:本文探讨知识图谱在生成式AI中的实际价值与适用边界,指出其在多跳推理和解释性方面的独特优势,同时揭示过度设计的风险。通过分析GraphRAG和代理记忆等案例,作者建议企业应先验证用户需求,仅当简单方案失效时才引入知识图谱的复杂性。文章强调成功的AI实施需要精准匹配技术工具与业务场景,避免盲目跟风技术热点。最后邀请行业专家分享实践经验,特别关注失败案例的学习价值。

摘要: 文章探讨了生成式AI与知识图谱结合如何优化企业数据管理,以Glean的GraphRAG技术为例,该技术通过整合知识图谱与大型语言模型(LLM),显著提升企业搜索效率,如某共享出行公司节省超2亿美元成本。尽管技术优势明显,但实施面临数据整合、专业人才短缺等挑战。未来,开源工具和战略合作将降低技术门槛,推动AI驱动解决方案的普及。企业需平衡创新与数据安全,投资人才培养以应对AI经济变革。 标签

在人工智能迅猛发展的今天,构建高效、自主的AI系统已成为行业焦点。谷歌首席技术官办公室高级总监兼杰出工程师Antonio Gulli近日宣布,其新书《Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems》将于2025年12月3日正式发布。这本400页的技术指南填补了AI开发方法论的空白,提供详细的架构蓝图
SciDaSynth:基于大语言模型的科学文献数据智能提取系统摘要:本文介绍了SciDaSynth这一创新交互式系统,它利用大语言模型(LLMs)和检索增强生成(RAG)技术,帮助研究人员高效地从多模态科学文献中提取和结构化数据。系统通过自然语言查询自动生成标准化数据表,并提供可视化摘要、语义分组和可追溯验证功能,显著提升了数据提取的效率和准确性。用户研究表明,该系统能有效解决传统手动提取方法效率

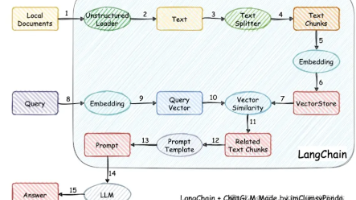
本教程由吴恩达与OpenAI合作推出,系统讲解如何基于大语言模型API快速开发应用。内容涵盖Prompt工程原则、文本处理技巧、ChatGPT问答系统搭建、LangChain框架应用及私有数据整合等核心技能,适合具备Python基础的开发者入门LLM应用开发。
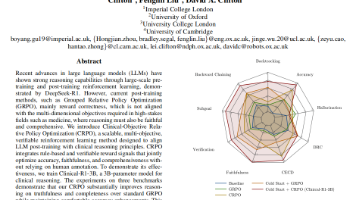
本文提出Clinical-R1-3B模型及CRPO(临床目标相对策略优化)方法,针对医疗领域设计的多目标强化学习框架。CRPO通过结构化奖励机制同时优化准确性、可信性和全面性三个目标,使模型推理过程符合临床医生的双过程思维模式。实验表明,该30亿参数模型在医疗推理任务中不仅保持与GRPO相当的准确率,更显著提升了推理可信度(减少幻觉、增强回溯能力)和全面性(增加子目标验证)。研究为医疗AI提供了可