




- @wkw_lzhl
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文系统分析了工业场景下时序数据库的选型策略。针对智能制造领域设备数量多、数据关联分析需求强、国产化和成本敏感三大特点,作者对比了TDengine、openGemini和InfluxDB三款主流时序数据库的核心特性及适用场景。TDengine采用"一设备一表"模型,集成缓存和流计算,适合大规模设备接入;openGemini作为华为开源产品,满足国产化需求且性能突出;InfluxDB则以成熟生态见长
本文系统分析了工业场景下时序数据库的选型策略。针对智能制造领域设备数量多、数据关联分析需求强、国产化和成本敏感三大特点,作者对比了TDengine、openGemini和InfluxDB三款主流时序数据库的核心特性及适用场景。TDengine采用"一设备一表"模型,集成缓存和流计算,适合大规模设备接入;openGemini作为华为开源产品,满足国产化需求且性能突出;InfluxDB则以成熟生态见长
2026年SCADA/组态软件选型标准已从传统功能转向平台化能力,重点关注7大核心要素: 原生Web架构:区分真Web化与桌面软件网页化,确保跨端体验一致。 开放数据接入:不只看协议数量,需支持现代IoT、业务系统集成。 高效可视化编辑:组件化、模板复用能力决定交付效率。 国产化与弹性部署:需适配国产系统、数据库,并支持云边协同。 项目复制能力:模板化和多站点管理是规模化落地的关键。
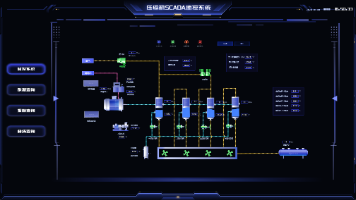
本文探讨了云边协同架构下组态系统在多工厂快速复制的实现路径。解决方案在于将"变化"留在边缘层(适配本地硬件),"标准"放在云端(统一数据模型和组态模板)。文章提出四步法:建立设备抽象层、设计组态模板体系、搭建分级数据同步机制、建立自动化运维流水线,并分享了实战教训,强调边缘侧必须能独立运行、模板颗粒度要适中。