




- @whatday
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Atheros现在可能是现在全球最大的无线网卡芯片供应商,此外大概就是Csico了。Atheros在无线网卡芯片领域跟Intel在中央处理器领域颇为相似,是在我国台湾宝岛的企业。虽然Intel的cpu和芯片组就是那些,但是与之配套的主板外观却五花八门各不相同。一样的,虽然Atheros的芯片组就那么几代,但是各厂商生产的无线网卡外观却有些不同。让人着实有些迷惑,事实上无论是Netgear还是D-L
要获取 DataFrame 的一行中的每个数值,可以使用 iterrows() 函数来遍历每一行并访问其中的元素。

检查pg日志,报错日志为FATAL:no pg_hba.conf entry for host "XX.XX.XX.XX",经查阅,这条错误的原因是因为客户端远程访问postgresql受限所致,因为postgresql默认情况下除本机外的机器是不能连接的。修改pg_hba.conf与postgresql.conf两个配置文件即可解决。因本地资源有限,在公共测试环境搭建了PGsql环境,从数据库本
简而言之,称为OSINT的开放源代码情报是指从公共资源中收集信息以在情报环境中使用它。从今天起,我们生活在“互联网世界”中,它对我们生活的影响将有利有弊。使用互联网的优势在于,它可以提供大量信息,并且每个人都可以轻松访问。缺点是滥用信息并花费大量时间。现在,出现了OSINT工具,这些工具主要用于收集和关联Web上的信息。信息可以各种形式获得;它可以是文本格式,文件,图像等。根据国会CSR报告,可以
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法。简单高效的数据挖掘和数据分析工具让每个人能够在复杂环境中重复使用建立NumP

今天看到一个电报群里说 利用BOT来签到,很好奇就想学学,来吧 !创建一个BOT!!!1、先搜索BotFather我这里搜索到好几个没有一个可用的,输入/help 返回俄文错误信息。后来在官网找到了https://telegram.me/BotFather 直接点击不用搜索,靠谱,管用。用带官网小图标的靠谱选项 中英文说明:/newbot - create a new bot 新建一个bot/my
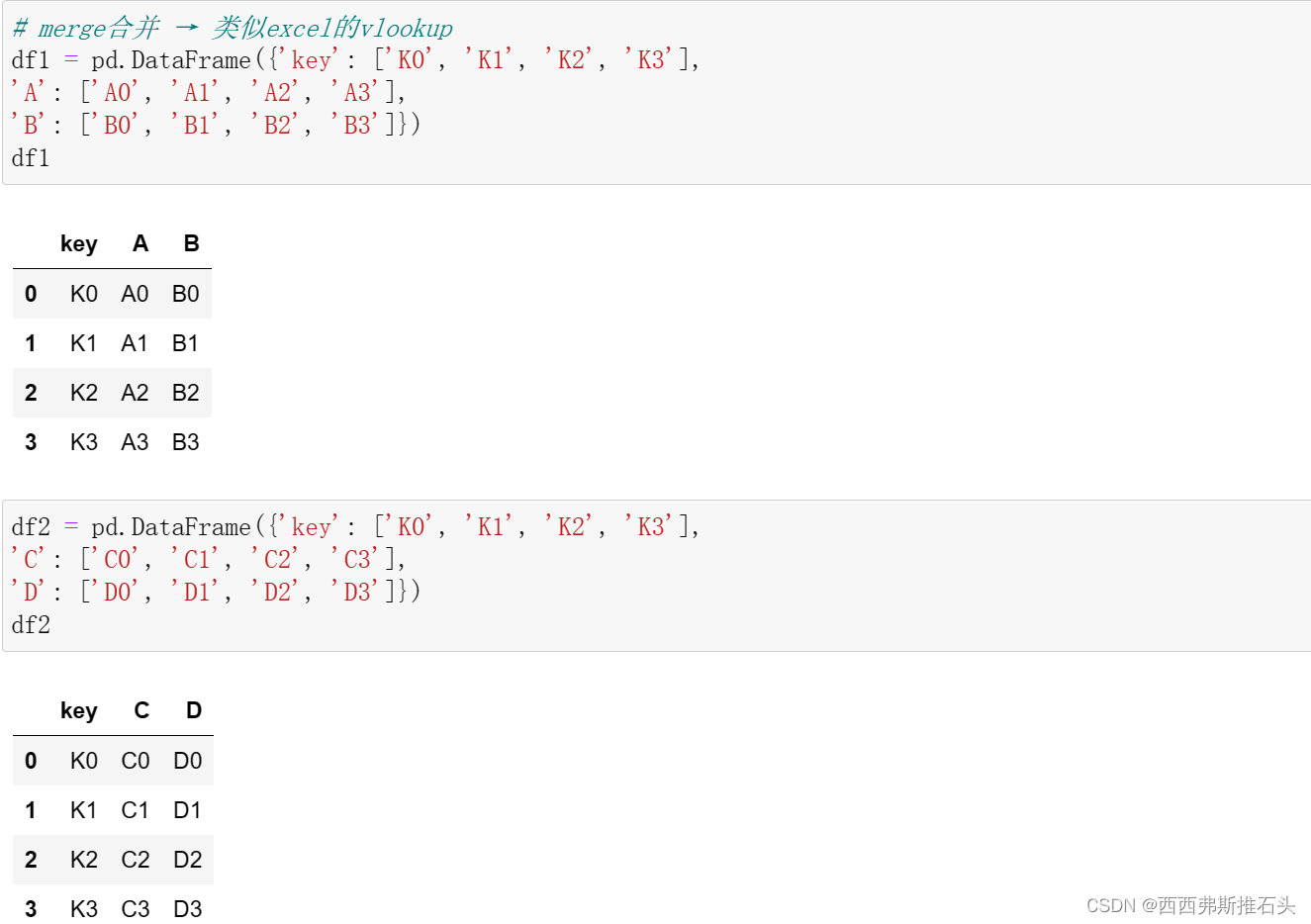
根据一个或多个键将不同DataFrame中的行连接起来。说明:类似于关系数据库的连接(join)操作、excel的vlookup应用场景:针对同一个主键存在两张包含不同字段的表,现在想把他们整合到一张表里。在此典型情况下,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量例:原有的两个DataFrame,分别为:df1;df2合并后:按指定的键连接,列数增加,去掉了多余的键可以沿着
首先介绍一下背景,在测试Deepgreen(Greenplum升级版)数据库时,pgbench并发数设置过多,导致数据库卡死了,在进行连接、重启、关闭时,都报同样的错误:psql: FATAL:the database system is in recovery mode。3、4、5、6.查看4个segment节点的postgres进程,看到有很多pgbench操作idle in transact
目录What surface can Vector live on? 矢量可以生存在哪个表面上?How far can Vector roam? 向量漫游能走多远?Why does Vector fall when he has cliff sensors? 为什么 Vector 有悬崖传感器的时候会摔倒?What surface can Vector live on? 矢量可以生存在哪个表面上?
概要:不知不觉中,WiFi几乎已攻占了整个世界。现在只要你上网,可能就离不开WiFi了。2014年是物联网WiFi市场关键的转折期,此前传统WiFi方案的价格超过40元,在对成本较敏感的电子产品消费市场应用普及较低。在2014年初,高通推出WiFi SOC芯片Atheros4004,TI推出3200芯片,芯片价格都在3美元左右,瞬间就将WiFi方案的价格拉到了30元左右。2014年中旬,M...