- @weixin_61573157
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速度。访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
机器学习即Machine learning,涉及很多学科,简单点来说,就是使用计算机通过“学习“大量的数据模拟实现人类的行为,也就是让计算机自己学习到一些所谓的”知识与技能“(例如什么是苹果?什么是香蕉?),而且能够通过一些算法组织其实现不断学习不断完善自身的性能与知识架构,换句话说,让计算机越来越”知识渊博“,也就是-----人工智能。

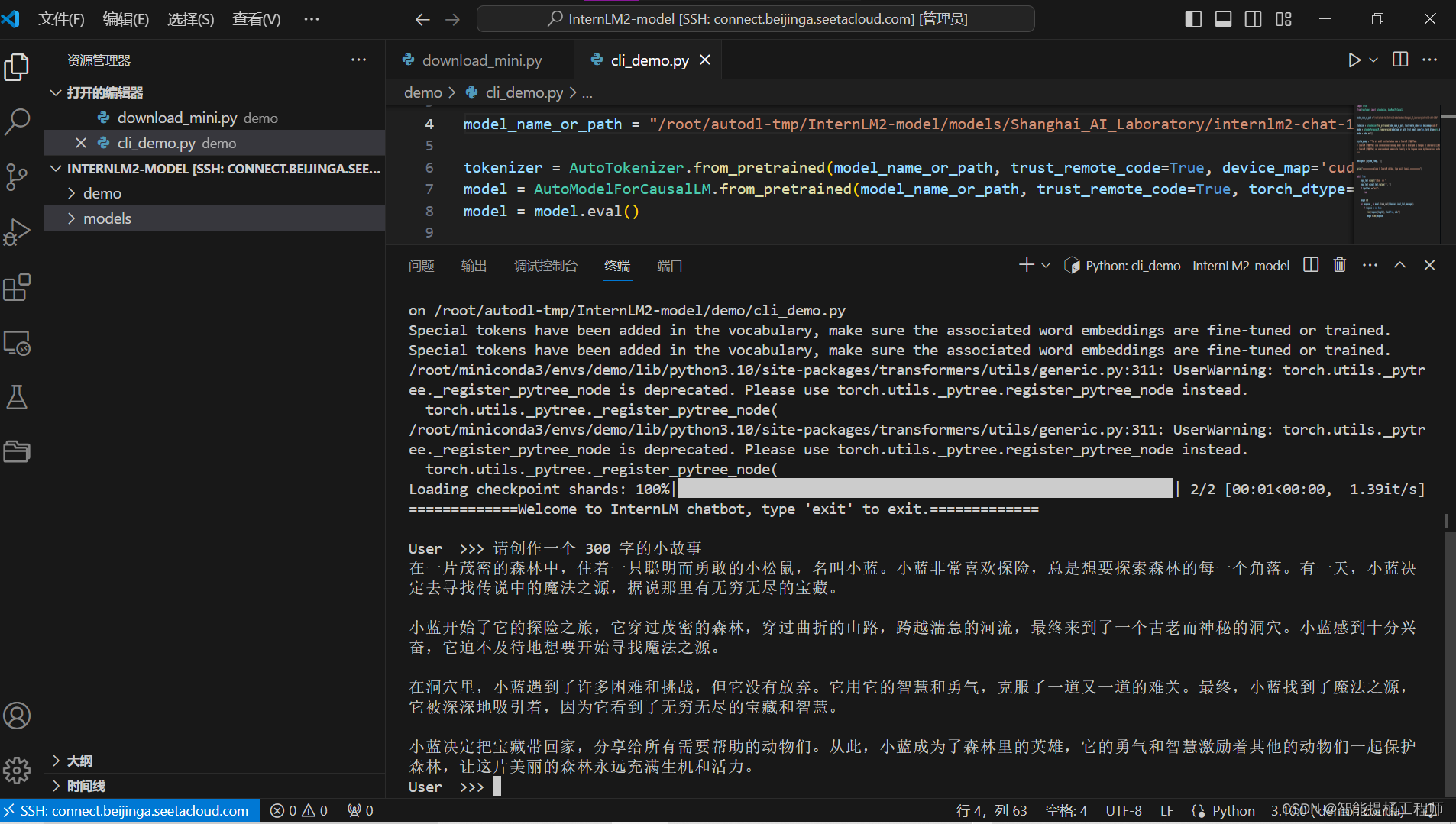
所谓的语料也就是新增知识数据,也就是这个小逼崽子的饲料,拿这些语料去数据去喂它它才能知道这么回答你问题(本地的语料数据库)----(后面会教你接通互联网,就可以直接用外界互联网的数据库来补充茴香豆的知识库)我是在autodl是租用的服务器来运行这次demo的,实在是一波三折啊,太难了,后续还是对操作文档的一句一句细致的精读,慢慢的理解思考,才最后解决了问题,成功部署!而茴香豆的主要应用目前是部署在

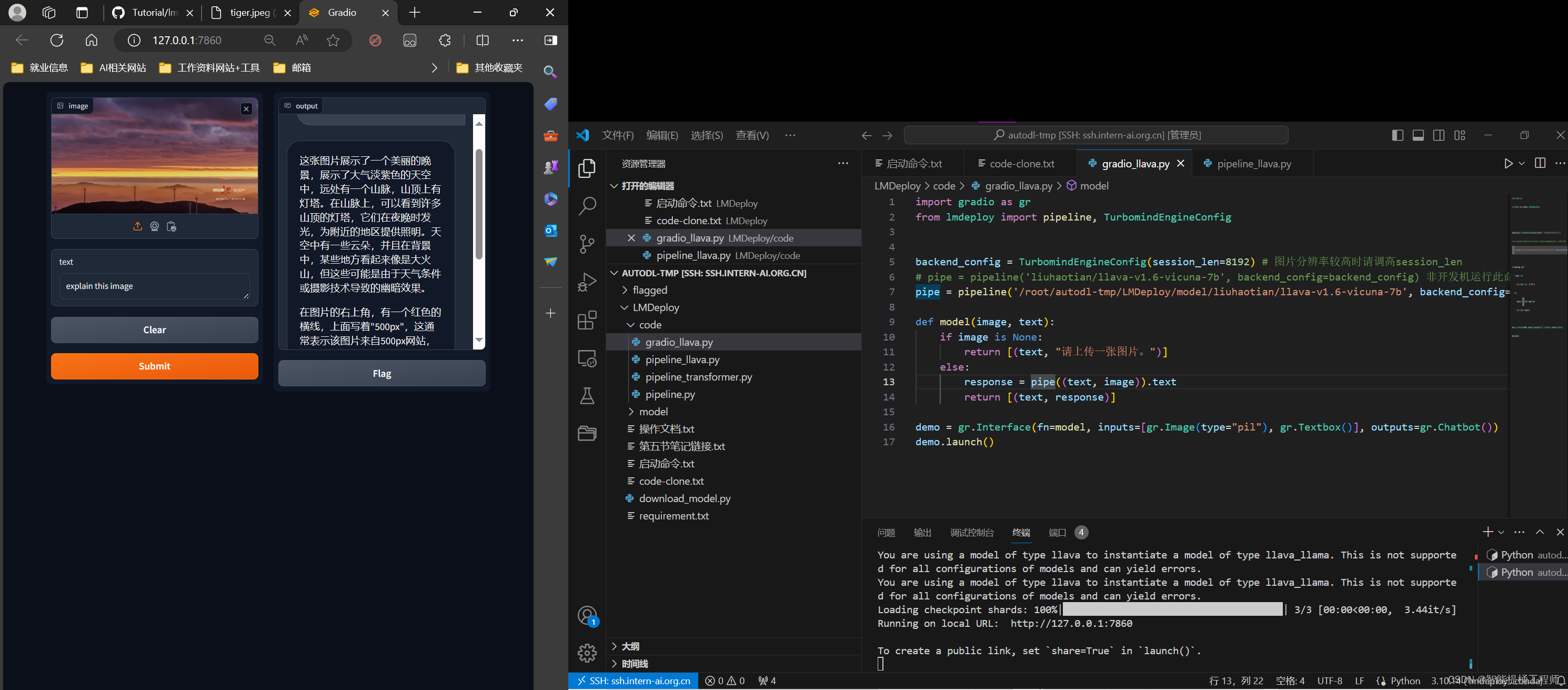
但是可以看到的是,大模型自身的计算量在增加时,其访存量不怎么变化,所以是不是模型自身的计算量上去了,基本就能平衡这个访存量,充分发挥GPU的算力不要再摸鱼了?GPU的显存根本耗不起,A100才80G显存,你自己看看下面这大模型加载的时候都需要这么大的显存,还部署个毛。而且还有KV的缓存,(保证整体模型结构的完整前提下,一块一块的剪掉,可以降低模型复杂性,缺点就是可能会误剪一些好的参数,和漏掉一些坏
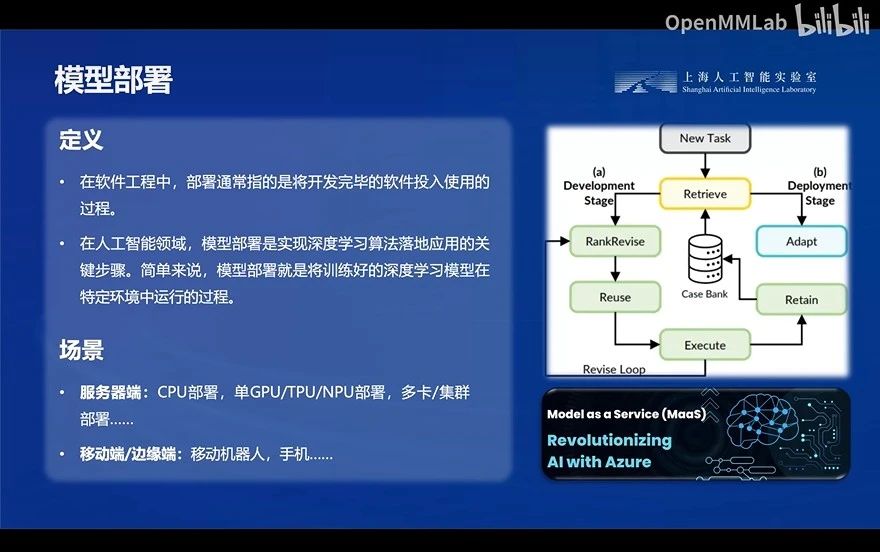
计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速度。访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速度。访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
所谓的语料也就是新增知识数据,也就是这个小逼崽子的饲料,拿这些语料去数据去喂它它才能知道这么回答你问题(本地的语料数据库)----(后面会教你接通互联网,就可以直接用外界互联网的数据库来补充茴香豆的知识库)我是在autodl是租用的服务器来运行这次demo的,实在是一波三折啊,太难了,后续还是对操作文档的一句一句细致的精读,慢慢的理解思考,才最后解决了问题,成功部署!而茴香豆的主要应用目前是部署在
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。它的整个框架图如下: