




- @weixin_60535956
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随着人工智能技术的飞速发展,AI Agent(智能体)正从实验室走向真实的生产环境。然而,复杂的部署流程、单机运行的局限、跨设备协作的缺失以及安全隐患,使得大多数用户仍无法享受AI带来的生产力红利。ToDesk依托其在远程控制领域深耕多年的技术积累,正式推出AI Agent产品——ToClaw。本白皮书将从市场背景、产品理念、核心技术、应用场景、安全合规等维度,全面阐述ToClaw如何通过“一个账

随着人工智能技术的飞速发展,AI Agent(智能体)正从实验室走向真实的生产环境。然而,复杂的部署流程、单机运行的局限、跨设备协作的缺失以及安全隐患,使得大多数用户仍无法享受AI带来的生产力红利。ToDesk依托其在远程控制领域深耕多年的技术积累,正式推出AI Agent产品——ToClaw。本白皮书将从市场背景、产品理念、核心技术、应用场景、安全合规等维度,全面阐述ToClaw如何通过“一个账
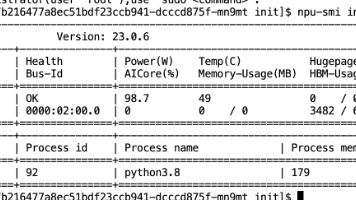
PD分离部署对大模型推理性能提升确实有明显效果,但配置过程比较繁琐,需要注意的点也很多。希望这份实战记录能帮大家少踩一些坑。一旦打通了HCCL通信链路,配合vLLM的PD分离架构,昇腾910B在DeepSeek这种大参数模型上的吞吐表现是相当可观的。如果在部署过程中遇到其他问题,建议先查看官方文档和社区讨论,很多常见问题都有解决方案,注明:昇腾PAE案例库对本文写作亦有帮助。昇腾社区。
随着人工智能技术的飞速发展,AI Agent(智能体)正从实验室走向真实的生产环境。然而,复杂的部署流程、单机运行的局限、跨设备协作的缺失以及安全隐患,使得大多数用户仍无法享受AI带来的生产力红利。ToDesk依托其在远程控制领域深耕多年的技术积累,正式推出AI Agent产品——ToClaw。本白皮书将从市场背景、产品理念、核心技术、应用场景、安全合规等维度,全面阐述ToClaw如何通过“一个账
随着人工智能技术的飞速发展,AI Agent(智能体)正从实验室走向真实的生产环境。然而,复杂的部署流程、单机运行的局限、跨设备协作的缺失以及安全隐患,使得大多数用户仍无法享受AI带来的生产力红利。ToDesk依托其在远程控制领域深耕多年的技术积累,正式推出AI Agent产品——ToClaw。本白皮书将从市场背景、产品理念、核心技术、应用场景、安全合规等维度,全面阐述ToClaw如何通过“一个账
PD分离部署对大模型推理性能提升确实有明显效果,但配置过程比较繁琐,需要注意的点也很多。希望这份实战记录能帮大家少踩一些坑。一旦打通了HCCL通信链路,配合vLLM的PD分离架构,昇腾910B在DeepSeek这种大参数模型上的吞吐表现是相当可观的。如果在部署过程中遇到其他问题,建议先查看官方文档和社区讨论,很多常见问题都有解决方案,注明:昇腾PAE案例库对本文写作亦有帮助。昇腾社区。
简要讲述一下稀疏矩阵及其使用方法
近年来,NLP 领域的深度学习方法取得了重大突破,包括BERT、GPT和XLNet等模型,这些模型都是基于 Transformer 架构的,并使用了大规模预训练技术,使得在语义理解、问答、文本生成等任务中都达到了领先水平。联邦学习:联邦学习是一种分布式机器学习方法,可以在保护数据隐私的前提下,将多个设备或数据中心的数据进行集成和分析。深度强化学习:深度强化学习是强化学习领域中的一种技术,结合了深度

具身智能是近期的一个热点方向。具身智能(Embodied Intelligence)指的是带“身体”的智能体,通过传感器和执行器在真实或虚拟环境中不断感知、行动和学习,从而形成对世界的理解和解决实际问题的能力。下面分几个方面详细说一下。
具身智能是近期的一个热点方向。具身智能(Embodied Intelligence)指的是带“身体”的智能体,通过传感器和执行器在真实或虚拟环境中不断感知、行动和学习,从而形成对世界的理解和解决实际问题的能力。下面分几个方面详细说一下。