- @weixin_54387067
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
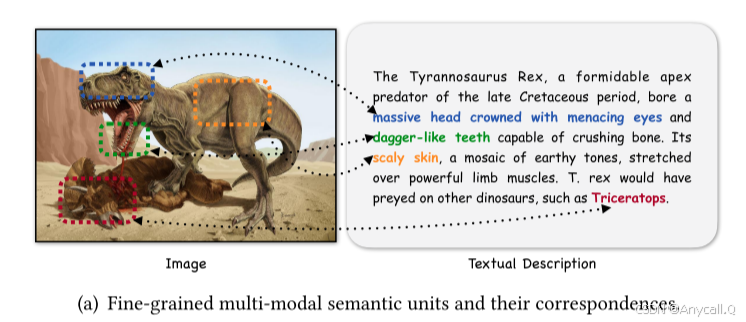
研究发现模型的输出对文本提示中。特别是,当生成有关频繁实体的文本提示时,这些模型通常会生成逼真的图像,忠实地反映实体的视觉外观。然而,当根据不太频繁的实体的文本提示生成时,这些模型要么幻觉不存在的实体,要么输出相关的频繁实体(见图 1),无法在生成的图像和提到的实体的视觉外观之间建立联系。这一关键限制可能会极大地损害文本到图像模型在现实应用中的可信度,甚至引发道德问题。在我们的研究中,我们发现这些
然后对 x1,x2 做边缘化(把联合分布里不关心的变量 x1,x2 积分掉,只留下 x0 的分布。它实际上描述的是一条完整的生成链。意思是:要生成 xt−1,不仅要看当前的 xt,还要看后面所有更噪的状态。我们通过对所有中间变量 x1∼xT 积分,得到数据 x0 的概率分布。注意:所有变量(包括噪声变量)与原图像的维度是相同的。,然后你把中间那些潜变量都积分掉,最终得到对真实图像的分布。因为这
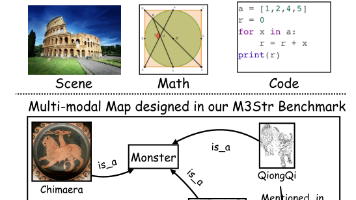
如风景、肖像、动植物。这些主要考验模型的视觉识别能力(这是什么?它在哪里?如数学公式、基础图表、代码截图。这些考验模型的符号解析能力。文中指出,现有的测试忽略了像思维导图和知识图谱这种高度抽象的内容。这类图像的特殊之处在于它们不仅是“画”,更是“逻辑”。
1、如果你让它画一个非常罕见的生物或特定的历史零件,它可能因为没见过而“胡编乱造”。例如,使用提示“一只暹罗猫正在嗅餐桌上的圣诞老人杯子。”作为查询,可能会返回“上面画着一只猫的杯子。”,因为知识语料库中缺乏与原始查询的精确匹配。这导致知识资源不完整,无法概括“暹罗猫”和“圣诞老人杯子”的概念。2、现有的“检索增强生成”(RAG)通常直接拿用户的整句话去搜图,搜出来的参考资料往往不够精准(噪声大)
在这些嵌入中,e𝑠𝑒𝑐,s(𝑒)封装了𝑒的全局信息,v(𝑒),w(𝑒)包含了局部模态信息。对于每个实体𝑒,我们可以收集其用于对比学习的候选对象为 C(𝑒) = {𝑒𝑠𝑒𝑐, s(𝑒), v(𝑒), w(𝑒)},它由其全局和局部特征组成。其中[CXT]是输入序列中捕获实体上下文嵌入的特殊标记,h是来自CMEE的<s:1>的输出表示,r是每个𝑟∈r的关系嵌入。为了捕获