
写文章




- @weixin_51580530
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
华丽的分割线----2026.7.11----华丽的分割线
最近一段时间刚刚完成了硕士中期汇报,实习也已经有两段,再出去实习导师也不会放过。奈何组内资源实在有限,算力和资源都足以支撑做业界前沿的具身项目。遂希望能通过这段时间积累和吸收现有的业界产出和关键知识,分享的内容包括VLN 、VLA、RL、WM类的优质论文,会一直保持两日更的频率 (过期会补),通过输出内容来激励自己输入。
深度学习面试必会之常见激活函数
以下是常见激活函数的简介,包括它们的典型应用场景、优缺点,以及基于 NumPy 的 Python 实现。
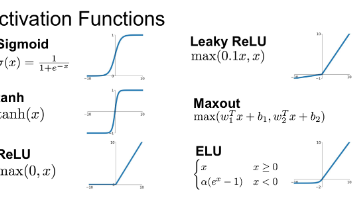
深度学习面试必会之常见激活函数
以下是常见激活函数的简介,包括它们的典型应用场景、优缺点,以及基于 NumPy 的 Python 实现。
视觉语言导航 之 人机交互主动对话导航新基准VL-LN Benchmark
本文提出 IIGN 任务与 VL-LN 基准,首次系统研究具备主动对话能力的具身导航智能体如何在房屋级长程环境中通过"主动提问"解决指令歧义、提升实例定位精度。arxiv研究领域:具身智能(Embodied AI)× 视觉-语言导航(VLN)× 人机对话arxiv核心任务:Interactive Instance Goal Navigation(IIGN)——在模糊类别指令下,智能体需边导航边向
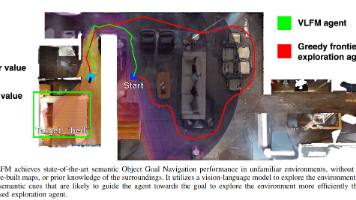
视觉语言导航 相关工作速览之一
人类在陌生环境中导航时,会结合语义知识(如物体空间分布规律)进行推理。受此启发,Yokoyama等(2023)[1]提出了一种零样本(zero-shot)语义导航方法VLFM,旨在让机器人在未知环境中高效寻找目标物体,。
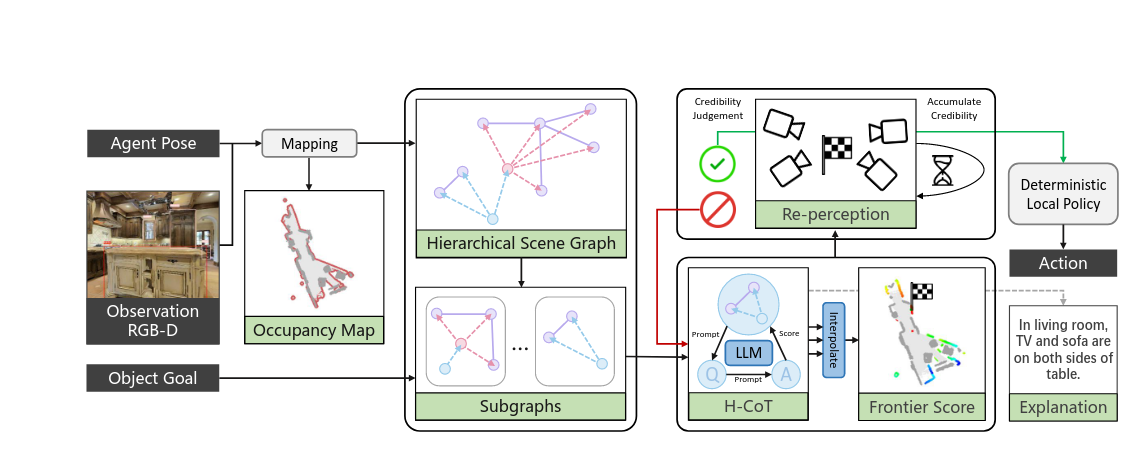
视觉语言导航 相关工作速览之二
SG-Nav首次通过场景图结构化表示与分层推理,实现了高精度、可解释的零样本导航,为LLM在具身智能中的场景理解提供了新范式[1]。
到底了