




- @weixin_51031772
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一般来说,量化粒度越小,需要额外存储的量化系数就越多,比如针对卷积运算常见的 per-tensor/per-channel 量化,如下图所示,per-tensor 共享一组 (S, Z) 量化系数,而 per-channel 需要多组,提升了量化精度,但同时会一定程度增加量化后数据的大小。基于范围的近似,则需要统计待量化数据的分布,然后进行整体的缩放和偏移,再映射到量化空间,精度相对更高,但需要额

图是一种数据结构,他主要表达表示实体(entity,也就是图的节点node)之间的关系(relationship,也就是图的边edge)。这里说的图(Graph)并不是图片的图(Image),后者应该被叫做像素图,本质上是空间里的像素矩阵,当然,像素图也可以被理解为特殊情况下(每个像素为节点,连接方式固定)的Graph。每个节点,边,以及图的整体都有相应的embedding,这里说的embeddi

最近在学习深度学习模型部署,踩过了很多坑,写一些学习笔记以供参考交流。
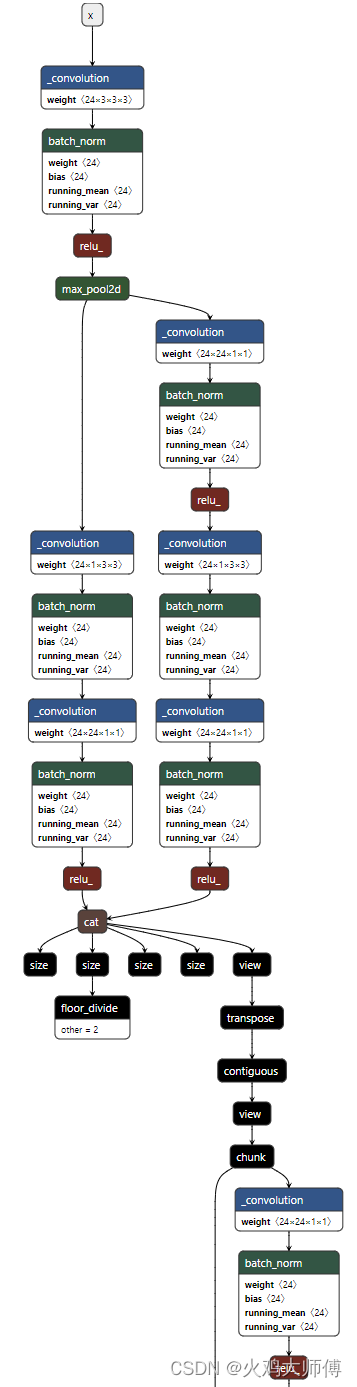
一般来说,量化粒度越小,需要额外存储的量化系数就越多,比如针对卷积运算常见的 per-tensor/per-channel 量化,如下图所示,per-tensor 共享一组 (S, Z) 量化系数,而 per-channel 需要多组,提升了量化精度,但同时会一定程度增加量化后数据的大小。基于范围的近似,则需要统计待量化数据的分布,然后进行整体的缩放和偏移,再映射到量化空间,精度相对更高,但需要额
一般来说,量化粒度越小,需要额外存储的量化系数就越多,比如针对卷积运算常见的 per-tensor/per-channel 量化,如下图所示,per-tensor 共享一组 (S, Z) 量化系数,而 per-channel 需要多组,提升了量化精度,但同时会一定程度增加量化后数据的大小。基于范围的近似,则需要统计待量化数据的分布,然后进行整体的缩放和偏移,再映射到量化空间,精度相对更高,但需要额
最近在学习深度学习模型部署,踩过了很多坑,写一些学习笔记以供参考交流。
最近在学习深度学习模型部署,踩过了很多坑,写一些学习笔记以供参考交流。