
写文章




- @weixin_50910721
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
DrissionPage终极神器
这三个软件都是用python代码打开浏览器去执行操作。Selenium:不支持异步操作,打开网站后变量可能和人操作时不一样,不防检测,易被封。Pyppepteer:绕过接口加密,直接访问获取网站信息,支持异步,有js脚本可以修改可能被检测的变量。DrissionPage:比Pyppepteer多功能,很多大网站Pyppepteer已经不行了。
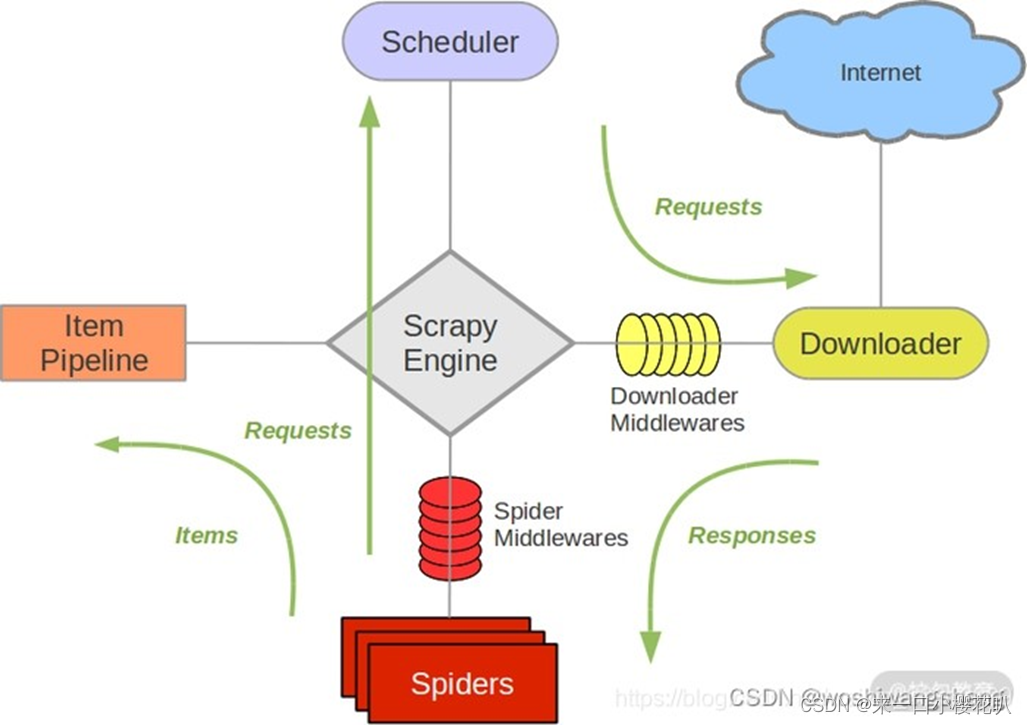
Scrapy框架——Downloader Middleware
新建了一个 Scrapy 项目,名为 scrapydownloadertest。pass修改 start_urls 为:[‘’]。随后将 parse() 方法添加一行日志输出,将 response 变量的 text 属性输出,这样我们便可以看到 Scrapy 发送的 Request 信息了。运行后,显示发送的 Request 信息q=0.9,*/*;q=0.8",},Scrapy 发送的 Requ
到底了