




- @weixin_49755078
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于追求与用户建立长期、个性化关系的对话 Agent 而言,一个可靠的“记忆系统”是不可或缺的核心组件。然而,随着对话轮次的增加,如何有效管理和利用日益庞大的历史信息,始终是一个悬而未决的难题。现有方案大多在复杂的架构上做文章,例如引入层级化摘要、知识图谱,甚至动用强化学习来优化记忆更新,但效果往往不尽人意,系统在长对话中依然容易“失忆”,遭遇“上下文稀释”(context dilution)的困

当前,)和)几乎已成为大模型对齐与微调的“标准动作”。我们似乎默认,先用SFT做监督微调,再用DPO对齐偏好,同时用LoRA来节省资源,就是一套黄金组合拳。但如果你的模型没那么“大”,数据也没那么“多”呢?这套组合拳还灵吗?来自斯坦福大学的一项最新实证研究,就给这个“想当然”的流程画上了一个大大的问号。研究者们在GPT-2(1.24亿参数)这样的小模型上系统地“解剖”了SFT、DPO、全量微调和L

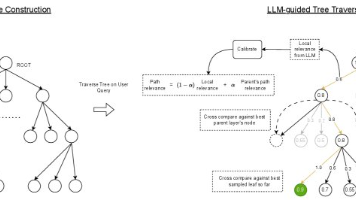
LLM引导的分层检索 (LLM-guided Hierarchical Retrieval):本文提出的核心框架。它将信息检索任务分为两个阶段:离线构建语料库的语义树,以及在线由一个“搜索LLM”导航该树以找到相关文档。语义树 (Semantic Tree):一种对文档语料库进行组织的树状结构。叶节点代表原始文档,而内部节点则是由LLM生成的、对其子节点内容的文本摘要。这种结构为LLM的导航提供了
在训练大语言模型(LLM)时,我们常常聚焦于模型架构、数据质量和训练规模,但一个“幕后英雄”同样至关重要——优化器。多年来,一直是训练Transformer模型的黄金标准。但它真的完美无缺吗?文本转载自公众号【AI研究】这会导致模型训练后期性能不佳。为了解决这个问题,研究者们提出了AdamHD,一个AdamW的即插即用替代品,效果惊人!

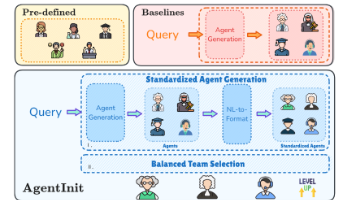
ArXiv URL: http://arxiv.org/abs/2509.19236v1发布机构: Harbin Institute of Technology; The University of Sydney文本转载自公众号【AI研究】。本文提出了一种名为 AgentInit 的多智能体系统(Multi-Agent System, MAS)初始化方法,该方法通过生成一组多样化的候选智能体,并利
FlowRL: 本文提出的核心算法。它是一种策略优化算法,其目标不是像传统强化学习那样找到单一的最优解,而是让模型的输出分布与奖励信号引导的目标分布相匹配。这通过一种受流网络(GFlowNets)启发的流平衡(flow balancing)机制实现,鼓励智能体探索更多样化且有效的推理路径。奖励分布匹配 (Reward Distribution Matching): 本文的核心理念。与最大化标量奖励

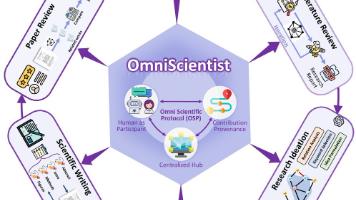
OmniScientist标志着一个范式的转变:从设计孤立的AI研究工具,转向构建一个全面的、可进化的AI与人类共生的科学研究生态系统。通过将人类科学界的协作规范、评价体系和知识结构融入AI,OmniScientist让AI Agent从单纯的任务执行者, evolve 成为能够理解科研范式、参与协作、并与人类科学家共同推动知识边界的真正“科学家”。一个AI与人类科学家共同演化、加速创新的新时代,
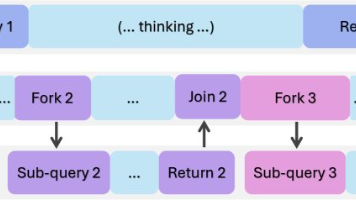
本文提出了一种名为 AsyncThink 的新推理范式,它允许大型语言模型通过一种“组织者-工作者”协议,将复杂的思考过程分解为可并发执行的子任务,并通过强化学习自主学会如何优化这种异步协同结构,从而在降低推理延迟的同时提升了解决问题的准确性。
本文认为,这两个谱系在底层机制上是根本不兼容的,将它们混为一谈导致了“概念修补”(conceptual retrofitting)的问题——即用一个谱系(通常是新的神经范式)的术语去描述另一个谱系(经典的符号范式)的系统。这些智能体通过结构化的消息(如JSON或XML)进行通信和协作,其功能是通过提示路由和API工具使用来实现的,这与符号范式中基于状态和规划的循环完全不同。它们将智能体的内部状态分
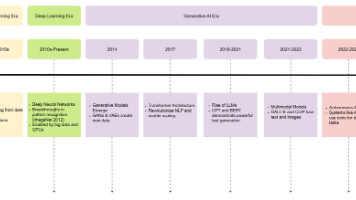
本文认为,这两个谱系在底层机制上是根本不兼容的,将它们混为一谈导致了“概念修补”(conceptual retrofitting)的问题——即用一个谱系(通常是新的神经范式)的术语去描述另一个谱系(经典的符号范式)的系统。这些智能体通过结构化的消息(如JSON或XML)进行通信和协作,其功能是通过提示路由和API工具使用来实现的,这与符号范式中基于状态和规划的循环完全不同。它们将智能体的内部状态分