
写文章




- @weixin_48606973
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
如何构造选择题进行垂域大模型微调
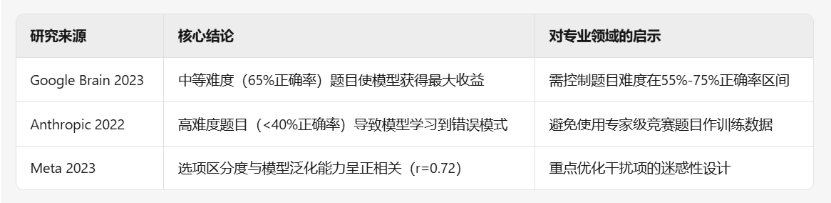
目前有前辈整理的专业领域QA对,但是质量不能算太好,模型效果也有提升的空间。在垂域大模型微调中,QA对通常能够带来更好的生成能力和上下文理解能力,特别是在需要生成详细回答的场景中。选择题则更适合需要推理和选择的场景,能够提高模型的准确性和推理能力。生成高难度选择题,增强模型判断答案完整性的能力,增强模型判断关键参数正确性的能力。在构造选择题之前,我们的先要明白什么样的选择题对于大模型微调之后的效果
HTML表格压缩——突破大模型Token限制
Token节省平均减少65-80% Token占用解决大模型上下文限制问题结构保留100%还原复杂合并关系多层表头关系完整保留模型友好JSON结构可直接输入模型减少模型解析HTML负担提升表格理解准确率。
大模型预训练的数据清洗——fasttext+datatrove
最近要做垂直领域大模型的预训练,准备收集1B tokens的专业领域文本数据。简单介绍一下,fasttext是用于领域分类的小模型,datatrove提供了pepiline处理整个数据清洗的流程,里面做了分布式计算和内存调优,在处理大数据的时候有明显优势。数据清洗的流程是:专业领域关键词过滤——fasttext领域分类过滤。整个流程都在datatrove的pipeline中运行。借此文记录这半个月

到底了