- @weixin_48167662
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在最近取得广泛关注的大规模语言模型(LLM)应用强化学习(RL)进行与人类行为的对齐,进而可以充分理解和回答人的指令,这一结果展现了强化学习在大规模NLP的丰富应用前景。本文介绍了LLM中应用到的RL技术及其发展路径,希望给读者们一些将RL更好地应用于大规模通用NLP系统的提示与启发。

忠实性幻觉指的是模型生成的内容与用户提供的上下文不一致。例如,当用户提供三篇关于“如何加热冷冻司康饼”的英文技术文档,并询问具体步骤时,模型可能在正确引用第一篇文档中的“预热烤箱”细节后,错误地将第二篇文档中关于“面粉蛋白质含量”的内容嫁接过来,或者编造出一个源自自身参数而非上下文的步骤(如“放入微波炉加热30秒”)。这些生成内容在语法上完全正确,但与给定的上下文相矛盾。由于忠实性幻觉通常发生在语
Text-to-SQL 旨在将自然语言问题自动转换为可执行 SQL,是自然语言接口、智能数据分析和企业级数据问答系统中的核心任务。随着大语言模型的发展,Text-to-SQL 的研究范式已经从早期的端到端语义解析,逐渐转向以 LLM 为核心、结合检索、结构建模、执行验证和多候选选择的系统化方法。近期研究表明,当前瓶颈并不只是 SQL 语法生成,而主要集中在复杂数据库环境下的用户意图理解、Schem
本次分享讨论了智能体技能相关的近期工作,包含构建与演化、组织、使用方向。在未来,skill 及存储执行架构的安全性、自我演化能力、过程验证和执行效率仍然是值得研究的角度。
忠实性幻觉指的是模型生成的内容与用户提供的上下文不一致。例如,当用户提供三篇关于“如何加热冷冻司康饼”的英文技术文档,并询问具体步骤时,模型可能在正确引用第一篇文档中的“预热烤箱”细节后,错误地将第二篇文档中关于“面粉蛋白质含量”的内容嫁接过来,或者编造出一个源自自身参数而非上下文的步骤(如“放入微波炉加热30秒”)。这些生成内容在语法上完全正确,但与给定的上下文相矛盾。由于忠实性幻觉通常发生在语
子图计数(Subgraph Counting)是图分析中重要的研究课题。给定一个查询图 和数据图 , 子图计数需要计算 在 中子图匹配的(近似)数目。一般我们取子图匹配为子图同构语义,即从查询图顶点集 到数据图顶点集 的单射 ,保持拓扑关系(当查询图存在边 时,数据图中对应点也需要有连边 )和标签(查询图顶点 和数据图中对应点 标签相同)不变。

在最近取得广泛关注的大规模语言模型(LLM)应用强化学习(RL)进行与人类行为的对齐,进而可以充分理解和回答人的指令,这一结果展现了强化学习在大规模NLP的丰富应用前景。本文介绍了LLM中应用到的RL技术及其发展路径,希望给读者们一些将RL更好地应用于大规模通用NLP系统的提示与启发。
北京大学 李荆编者按:原文《Foundations and modelling of dynamic networks using Dynamic Graph Neural Networks: A survey》介绍一篇关于动态图上的神经网络模型的综述,本篇综述的主要结构是根据动态图上进行表示学习过程的几个阶段(动态图表示、模型学习、模型预测)进行分别阐述。包括1. 系统的探讨不同维度下的动态图分
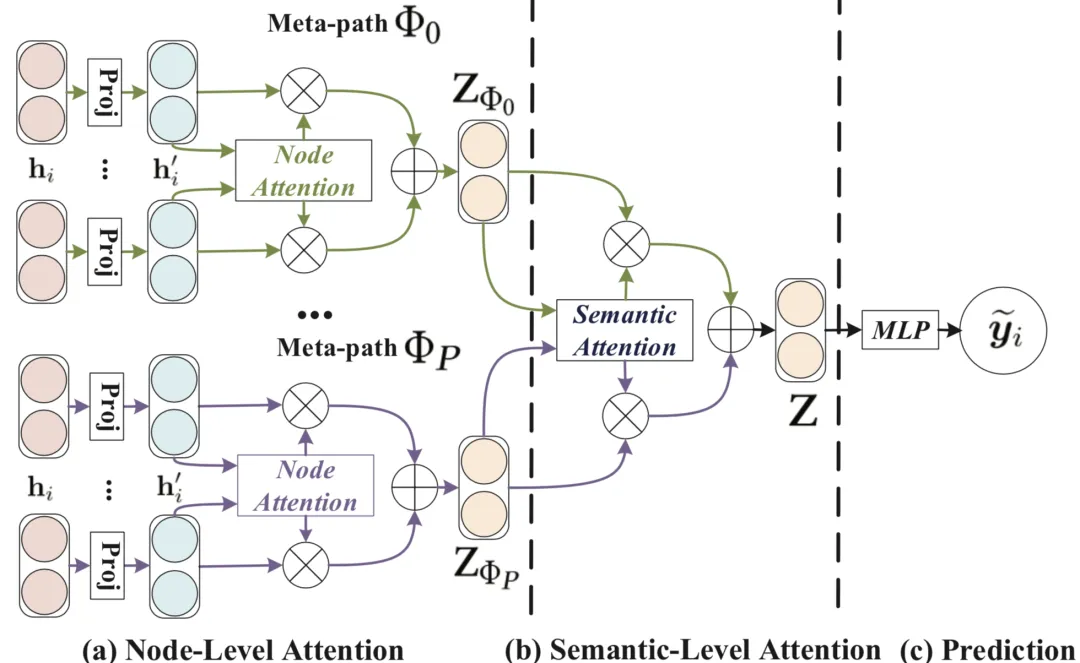
近年来,图神经网络(Graph Neural Networks, GNNs)已成为图挖掘研究的核心,研究人员开始关注其在异构图方面的潜力。异构图由多种类型的节点和边构成,且带有不同的辅助信息,这将新颖有效的图学习算法与嘈杂复杂的工业场景(如推荐系统)联系起来。在异构信息网络中,各类节点的嵌入空间通常不同。不同节点对之间以及相同节点对之间,都存在着各种各样的关系。
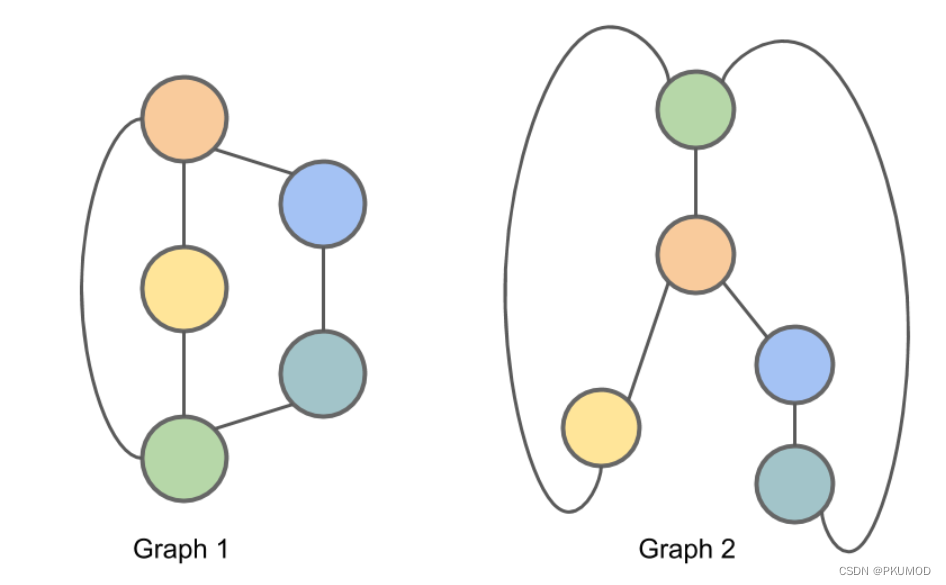
我们首先介绍图的同构问题。给定两个图GVGEGHVHEHGVGEGHVHEH,如果存在一个映射πVG→VHπVG→VHst∈EG⟺πsπt∈EHst∈EG⟺πsπt))∈EH那么GHG,HGH就是同构的,记作G≃HG\simeq HG≃H,且称π\piπ是图GGG和HHH的一个同构。