
写文章




- @weixin_46734801
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
学习FreeRTOS (一) - 芯片启动
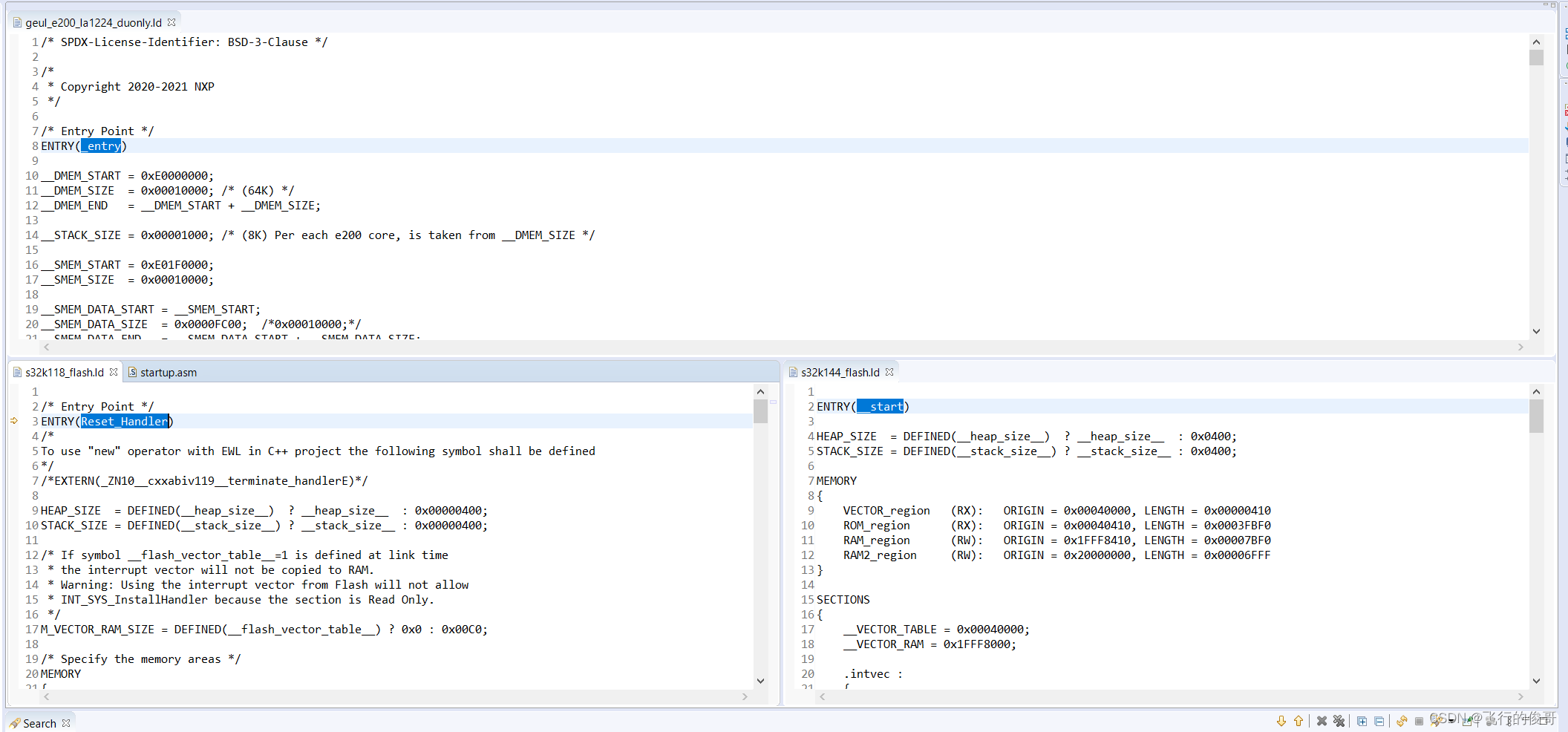
系统上电的时候,第一个执行的启动文件里面有汇编写的复位函数Reset_Handler(不同的芯片平台有不同的entry point). 复位函数最后会调用C库函数_main, 从而进入到用户编写的C语言的程序中。里面编译时用的link file的entry point 在不同平台是不同的,但是工作都是初始化处理器,配置各种堆栈(比如说起始地址和size),寄存器,interrupt 向量列表, 时
gpu 优化 - 256QAM
同样,256qam 做完之后的t1时刻,应该发动D2H的memory copy. 但是stream 0的D2H CUDA API 还没到,这时候要等改API被launch 才会触发D2H.接收端,接收N/8的复数序列(c0c1…),要把它解码到长度N 的uint8_t 的soft bit的序列。),要把它解码到长度N 的uint8_t 的soft bit的序列。以下是接收端的256qam从复数到s
GPU 优化 - 算力,内存带宽理论分析,roofline model, GPU演进
GPU 算力,内存分析
GPT-2 分析与实现
预处理之后,有5类参数:blocks (transformer层的参数), b,g(输出层的final_norm shift/scale), wpe (嵌入层的Positioning embedding layer), wte(嵌入层的Token embedding layer和输出层线性层out_head)。一般来说,当我们模型的输出每一维有50257个元素,每个元素代表该词元ID的概率,找到最
到底了