- @weixin_44887311
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
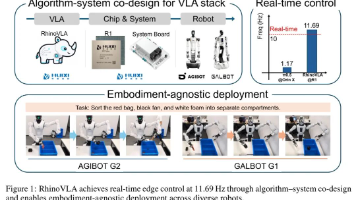
【论文摘要】RhinoVLA通过系统性优化在机器人视觉-语言-动作(VLA)任务中实现高效部署。研究发现传统VLM模型的延迟瓶颈主要来自MLP投影算子而非注意力机制,通过采用视觉词元更高效的Qwen3-VL架构(压缩75%词元)、设计72D统一动作槽空间和InstanceLoRA适配机制,在保持多模态能力的同时显著提升推理速度。在Huixi R1芯片上实现11.69Hz实时推理(较基线提升10倍)
OpenDriveLab与地平线机器人联合提出NativeMEM框架,实现机器人长程记忆的高效压缩与利用。该方案将每帧历史画面压缩为1个视觉Token,直接存储在VLA模型的原生特征空间中,使机器人能以极低成本保存分钟级、稠密更新的操作历史。关键创新包括:复用预训练VLA的视觉编码器生成原生兼容的记忆Token;仅通过动作损失监督记忆学习;采用两阶段训练实现快速适配。实验表明,该方法在仿真和真实任
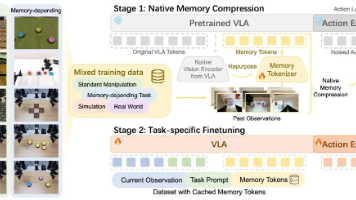
OpenDriveLab与地平线机器人联合提出NativeMEM框架,实现机器人长程记忆的高效压缩与利用。该方案将每帧历史画面压缩为1个视觉Token,直接存储在VLA模型的原生特征空间中,使机器人能以极低成本保存分钟级、稠密更新的操作历史。关键创新包括:复用预训练VLA的视觉编码器生成原生兼容的记忆Token;仅通过动作损失监督记忆学习;采用两阶段训练实现快速适配。实验表明,该方法在仿真和真实任
麻省理工学院团队研发出一款250克的扑翼机器人,成功模拟潜水鸟类"飞行-游泳-入水-跃出"的全套动作。研究发现:1)中等尺寸柔性机翼能平衡空中飞行(6.3米/秒)与水下游泳(0.79米/秒)需求;2)超柔性机翼通过被动形变减小水下阻力,使扑翼频率达6Hz;3)出水时70°仰角配合短尾设计成功率最高,但能耗是机械能增益的40倍。该研究揭示了鸟类跨介质运动机制,为两栖机器人设计提供
加州大学圣地亚哥分校团队在《Nature》发表研究,首次证实人形机器人(Unitree G1)可完成活体猪腹腔镜胆囊切除术。研究通过三阶段实验(台面测试、用户研究、动物实验)系统评估了可行性:机器人能完成关键手术步骤,但精度(1.30mm直线误差)和工作效率仍逊于达芬奇系统,且存在延迟、臂展限制等问题。研究指出,人形机器人的类人形态使其能直接使用标准手术器械,未来或可兼顾护理、物流等多重医疗角色,
DeepSeek研究团队通过强化学习训练大型语言模型DeepSeek-R1,使其具备自主推理能力。该模型在解决数学问题时采用逐步推理方式,通过正确奖励和错误惩罚机制,学会了自我验证和反思。与传统依赖人工标注的方法不同,DeepSeek-R1完全通过RL训练获得推理能力,在数学、编程和STEM领域表现优异。这一创新不仅提升了模型性能,还能指导小型模型的推理能力开发。目前DeepSeek-R1在Git

OpenAI正在重启机器人研发,重点布局人形具身智能领域。据招聘信息和媒体报道显示,公司正在组建机器人研发团队,招聘机械工程师、仿真环境工程师等岗位,强调规模化生产设计(百万量级)和遥操作/仿真训练技术(如Nvidia Isaac)。这是继2019年展示Dactyl机械手成果后,OpenAI再次将AI与物理世界深度结合的战略调整。业内人士分析,OpenAI意图将大语言模型的认知能力延伸至物理操作层

《高分辨率实时机械变色触觉传感器》提出了一种创新触觉传感方案,通过机械变色材料将接触应变直接编码为结构色变化,实现约100微米空间分辨率的实时触觉成像。该三层柔性传感器由光弹性薄膜制成的Bragg反射层构成,受压时反射波长随应变改变,相机可直接读取颜色分布映射接触形貌。实验验证了其对指纹、硬币纹理等微观特征的成像能力,并通过层厚调控实现在边缘检测与压力测量模式间的切换。相比传统视觉触觉需复杂图像重
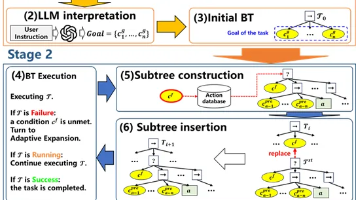
摘要:本文提出一种结合大型语言模型(LLM)与人机交互的机器人动作学习方法。通过设计包含提示工程、操作基元和动作数据库的上下文框架,LLM可生成包含前置/后置条件和操作基元的动作知识。关键创新是引入人机交互环节,允许人工修正LLM输出,确保知识安全性。实验表明,该方法在8个不同难度任务中成功率超80%,且能有效应对70%的外部干扰情况。相比基线方法,该方案显著提升机器人学习性能,但对新对象的泛化能
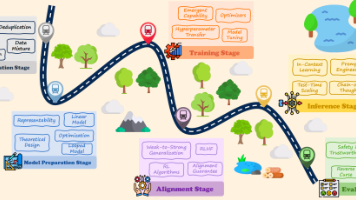
本文系统综述了大语言模型(LLMs)的理论基础与研究进展。研究者提出基于生命周期的分类法,将LLM理论研究划分为数据准备、模型准备、训练、对齐、推理和评估六个阶段。重点分析了数据混合的数学依据、Transformer架构的表示极限、预训练与对齐的优化机制等核心问题,并探讨了合成数据自我提升、安全保证数学边界等前沿挑战。该综述旨在推动LLM研究从工程启发式方法向严谨科学学科的转型,为理解模型底层机制