




- @weixin_44811994
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
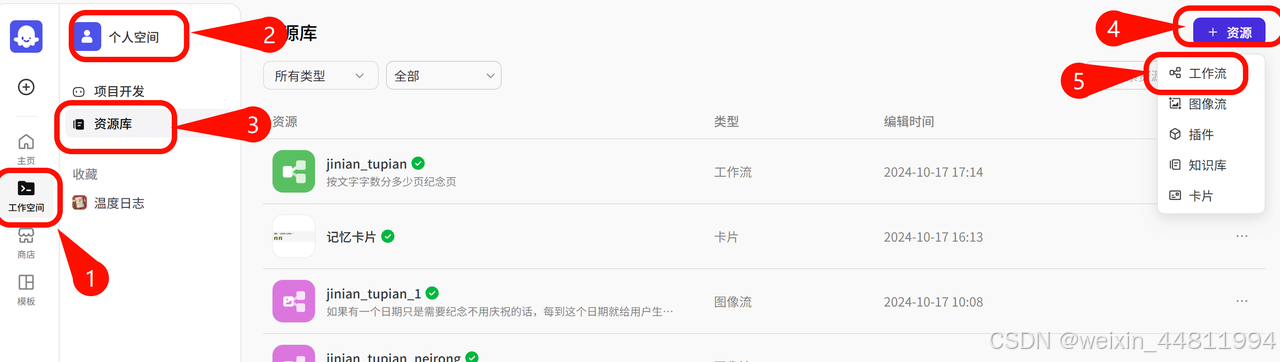
登录扣子平台。在左侧导航栏中选择工作空间,并在页面顶部空间列表中选择个人空间。(注意:系统默认创建了一个个人空间,该空间内创建的资源例如智能体、插件、知识库是你的私有资源,其 他用户不可见。你也可以创建团队或加入其他团队,团队内的资源可以和其他团队成员共享。在资源库页面右上角单击+资源,并选择工作流。设置工作流的名称与描述,并单击确认。(注意:清晰明确的工作流名称和描述,有助于大语言模型更好的理解
这一章重点探讨统计模型和机器学习模型,两个大的主题都建立在数据的基础之上,所以要熟练掌握对数据的处理与分析。实际上,机器学习本身就是统计模型的延伸,是在大数据背景下传统统计方法捉襟见肘了,所以才考虑引入机器学习。在学习过程中,大家会接触到大量的算法,一方面要理解算法的基本原理,另一方面又要能针对实际问题进行灵活应用。注意:本章内容是比较难以学习的一个章节,希望各位能够耐心去看完这一章。另外,大家还

如何用cc switch或智谱调用claude code.
拒绝过度设计,先构建一个包含“输入-处理-反馈-输出”的最简闭环,验证 AI 协作的可行性。
在VS Code的PowerShell终端中切换目录很简单。这样可以确保PowerShell正确地将整个带空格的路径名识别为一个参数。在PowerShell中处理带空格的路径时,:如果你在文件管理器复制了文件夹路径,可以直接在终端中。如果你希望每次在VS Code中新建终端时,它都自动在。这是最方便快捷的方式,终端会自动切换到该目录。这样,终端就会在当前活动文件所在的目录中打开了。:如表格中所述,
编辑jsonc复制},同级放定义服务端口、卷挂载等。表格方案适用场景隔离级别首次耗时一键复现venv/conda纯 Python进程级秒级全栈/系统依赖容器级分钟级✅根据项目复杂度选其一即可。复制分享venv 和conda 是并列关系吗?用了一个就不用另外一个了?复制不是并列,也不完全互斥,它们处在不同层级,可以二选一,也可以混用。定位不同•venv只解决“同一台机器里不同 Python 项目用不
拒绝过度设计,先构建一个包含“输入-处理-反馈-输出”的最简闭环,验证 AI 协作的可行性。
如何用cc switch或智谱调用claude code.
我们训练好的NER模型(能识别“高血压”、“降压药”等)现在要变成一个真正的“服务”,让别人可以通过网络来调用它。在这个页面中,可以查看所有的 API 端点(Endpoints)、参数和返回结构,并直接进行调用和测试。点击右上角的 “Try it out” 按钮,然后再点击蓝色的 “Execute” 按钮,页面下方会立即显示出 API 的执行结果。"text": "患者自述发热、咳嗽,伴有轻微头痛
想象一下,你读了一句话:“姚明昨天在北京打篮球。普通人一眼就能看出:“姚明”是个人,“北京”是个地方。就是让电脑也学会这种能力——从文字中找出(人名)、(地名)、(公司名)、等关键词语,并给它们贴上正确的标签。:姚明、雷军:北京、故宫:阿里巴巴、英伟达:黑神话:悟空、iPhone:昨天、2025年一个词是不是实体,取决于场景。比如“苹果”:在水果摊前 → 不是实体(普通名词)在手机讨论中 → 是组